

- プロンプトの理解力が向上し、意図通りの画像を生成可能
- 従来のモデルと比べて2倍以上のパラメーター数で複雑なタスクに対応
- 繊細なライティングやシャドウ表現でリアルな仕上がりに
みなさんは、Stable Diffusion XL(SDXL)についてご存知でしょうか?Stable Diffusion XLとは、Stability AI社が開発した画像生成AIで、SDXLとも略されています。
旧モデルに比べて出力精度や解像度が大きく進化し、商用利用やアニメ・イラスト制作にも活用可能です。本記事では、SDXLの特徴・旧モデルとの違い・導入方法・使い方・注意点を分かりやすく解説します。
最後までご覧いただくと、自分の環境でSDXLを活用できるようになります。
\生成AIを活用して業務プロセスを自動化/
- Stable Diffusion XLとは
- Stable Diffusion XLと旧モデル(Stable Diffusion 1.5・2.1)との違い
- Stable Diffusion XLの導入方法
- Stable Diffusion XLを使って画像を生成してみた
- Stable Diffusion XLの活用事例
- Stable Diffusion XL対応ツール・サービス一覧
- Stable Diffusion XLを利用する際の注意点とトラブル対策
- Stable Diffusion XLは無料でも使える?有料版との違いは?
- Stable Diffusion XLに関するよくある質問
- Stable Diffusion XLで高精度な画像生成にチャレンジしよう
- 最後に
Stable Diffusion XLとは
Stable Diffusion XL(SDXL)とは、Stability AI社が2023年にリリースした高性能な画像生成AIモデルです。従来のStable Diffusionシリーズに比べて、プロンプトの解釈力や出力精度が大きく進化しており、複雑な構図や自然なライティング・シャドウ表現にも対応できます。色彩や質感の再現度も高く、フォトリアルな表現からアートスタイルまで幅広い生成が可能です。
また、SDXLはパラメータ数が旧モデルの2倍以上に増加しており、より豊かな表現力を実現しています。生成可能な画像サイズも最大1,024×1,024ピクセルまで拡大され、高解像度の出力に対応しています。推奨環境としては8GB以上のVRAMを備えたGPUが望ましく、大規模モデルを快適に動かすためには12GB以上が推奨です。
オープンソースで提供されているため、研究利用から商用利用まで幅広く活用できるのも大きな特徴です。
なお、Stable Diffusionについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

Stable Diffusion XLと旧モデル(Stable Diffusion 1.5・2.1)との違い
Stable Diffusion XLと旧モデルのStable Diffusion 1.5との違いをまとめました。
- 複雑な構図で画像生成が可能
- パラメーター数が従来のモデルの2倍以上
- 出力精度が上がった
- 最大1,024×1,024の画像が生成可能
とくに、画像の出力精度や画質が向上している点が大きな違いです。Stable Diffusion XLの特徴を詳しく解説していくので、ぜひ参考にしてみてください。
複雑な構図や背景表現が可能に

Stable Diffusion XLは、旧モデルと比較して、複雑な構図での画像生成が可能になりました。手やテキストを綺麗に表現できるほか、上記画像の犬を追いかける女性といった空間的に配置された構図を表現できるのが特徴です。
画像モデルがレンダリングしにくかった概念を生成できるようになったので、画像生成の幅が広がっています。
パラメーター数は旧モデル比で2倍以上に増加
Stable Diffusion XLは、旧モデルのStable Diffusion 1.5と比較してパラメーター数が2倍以上になっています。パラメーター数とは機械学習モデルが学習中に最適化する変数の数を表しており、数値が大きいほど複雑なタスクを高精度でこなせます。
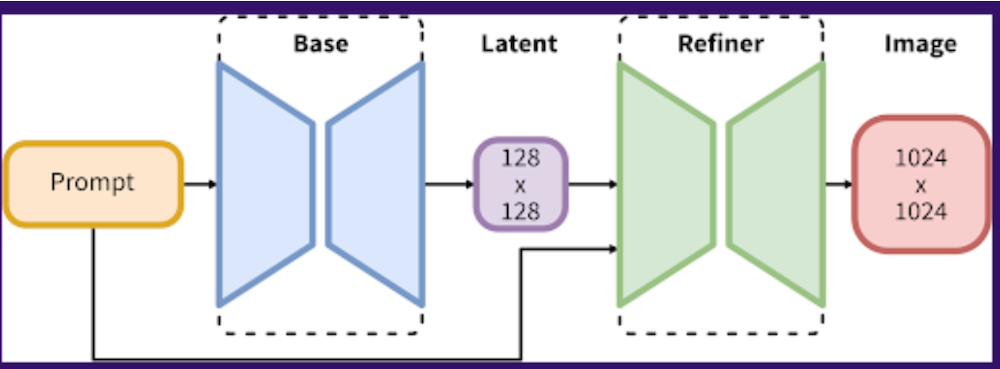
なお、Stable Diffusion XLは、3.5BのBaseモデルと6.6BのRefinerモデルの2種類で構成されているのが特徴です。Baseモデルが潜在情報を生成したあと、Refinerモデルがノイズ除去を実行して効率よく画像を生成できます。
プロンプト理解力の向上
Stable Diffusion XLでは、入力したプロンプトの理解力が大幅に向上しました。旧モデルでは複雑な指示や長文プロンプトを使うと意図通りに反映されにくいことがありましたが、SDXLでは細かなニュアンスまで反映されやすくなっています。
たとえば「夕暮れの街並みを背景にした人物イラスト」といった複合的な要素も正確に組み合わせて描写できるため、クリエイターのイメージにより近い画像生成が可能になりました。
テキスト生成精度の改善(文字が読める画像)
Stable Diffusion XLでは、画像内に表示されるテキストの精度が大幅に改善されています。旧モデルでは英数字や単語が崩れたり、意味のない文字列になることが多く、ポスターやロゴ風デザインには不向きでした。
SDXLでは文字の形状が安定し、シンプルな単語や短いフレーズであれば読み取れるレベルの画像を生成できます。これにより、広告風のビジュアルや同人誌の表紙デザインなど、文字要素を含む用途にも活用の幅が広がりました。
出力精度が上がった

Stable Diffusion XLは、短いプロンプトからでも高画質画像の出力が可能になりました。単語を詳しく説明する修飾語を使わずとも、ユーザーの意図を理解した画像を作成できます。
「The Red Square」と「(a) red square」のように、概念の違いも理解できるようになったので、画像生成の利便性も向上しています。
最大1,024×1,024の画像が生成可能
Stable Diffusion XLでは、最大1,024×1,024の解像度で画像を生成できます。旧モデルのStable Diffusion 1.5が最大512×512だったため、2倍の大きさになりました。
画像サイズのアップに伴い、コントラスト・ライティング・シャドウなどの表現も向上しているので、色彩豊かで美しい画像を作成できるようになっています。


Stable Diffusion XLの導入方法
Stable Diffusion XLの導入手順を以下にまとめました。
- Stable Diffusion Web UIをインストール
- 必要なファイルをダウンロード
- ファイルを適切な場所に格納
- Stable Diffusion Web UIを起動してモデルを切り替え
導入するまでの手順が複雑ですが、以下で詳しく解説していくので、参考にしてみてください。
Stable Diffusion Web UIをインストール
まずは、Stable Diffusion Web UIをインストールします。すでにローカルPCにインストール済みの方は、この手順を飛ばして問題ありません。
Stable Diffusion Web UIをインストールする際は、PythonやGitなどの必要なファイルをいくつもダウンロードする必要があります。
インストール方法について詳しくは以下の記事をご覧ください。

必要なファイルをダウンロード
Stable Diffusion XLを導入するには、Baseモデル・Refinerモデル・VAEの3つのファイルをダウンロードする必要があります。
RefinerモデルとVAEはダウンロードしなくてもStable Diffusion XLを使えますが、生成画像を高画質化させる重要な役割を担っているのでダウンロード推奨です。
まずは、Hugging FaceからBaseモデルのダウンロードページにアクセスしてください。
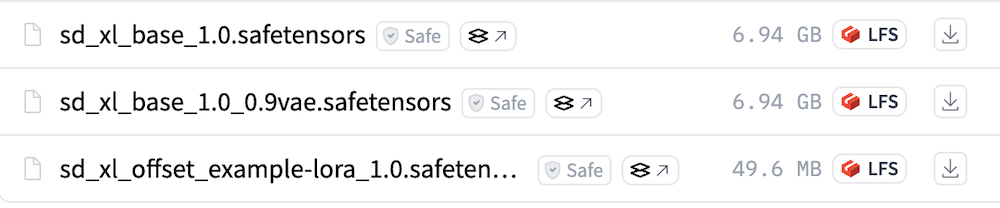
上記画像のうち、1番上の「sd_xl_base_1.0.safetensors」をダウンロードします。
次はRefinerモデルをダウンロードします。

Hugging FaceのRefinerモデルのダウンロードページにアクセスして、上記画像にもある「sd_xl_refiner_1.0.safetensors」をダウンロードします。
最後にVAEです。
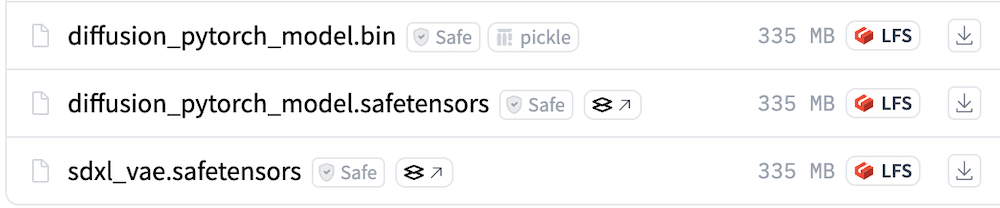
Hugging FaceのVAEのダウンロードページにアクセスして、上記画像にもある「sdxl_vae.safetensors」をダウンロードします。
これで必要なファイルのダウンロードは完了です。
ファイルを適切な場所に格納
ダウンロードしたBaseモデル・Refinerモデル・VAEの3つをそれぞれ適切な場所に格納します。
- BaseモデルとRefinerモデル:「stable-diffusion-webui」→「models」→「Stable-diffusion」
- VAE:「stable-diffusion-webui」→「models」→「VAE」
筆者はMacを使用しているので、Macの手順を解説します。
まずはFinderを開いて、「stable-diffusion-webui」のファイルを検索して見つけ出します。
検索しても出てこない場合は、Stable Diffusion Web UIをインストールできていないので、「Stable Diffusion Web UIをインストール」の手順に戻ってください。
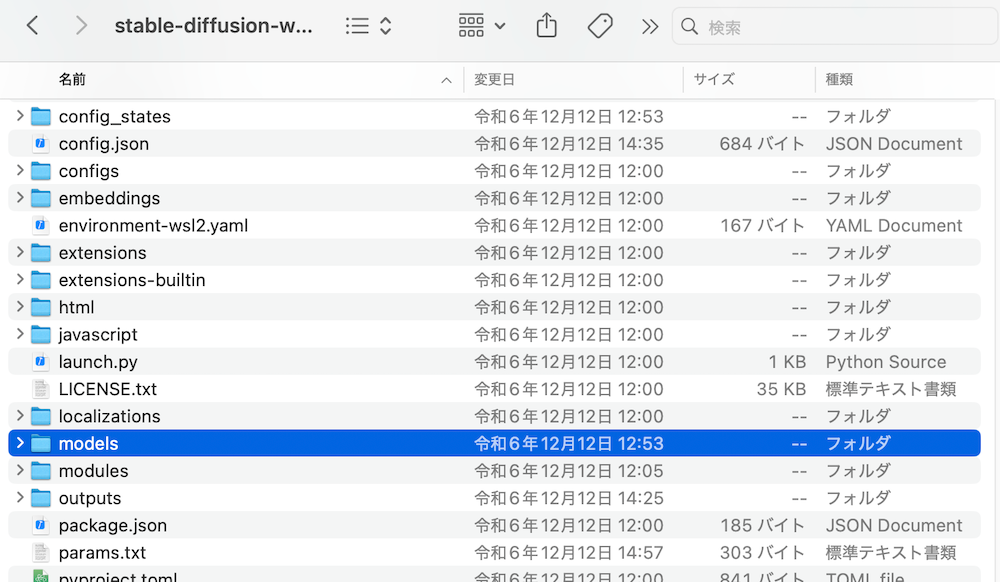
「stable-diffusion-webui」→「models」の順に開きます。
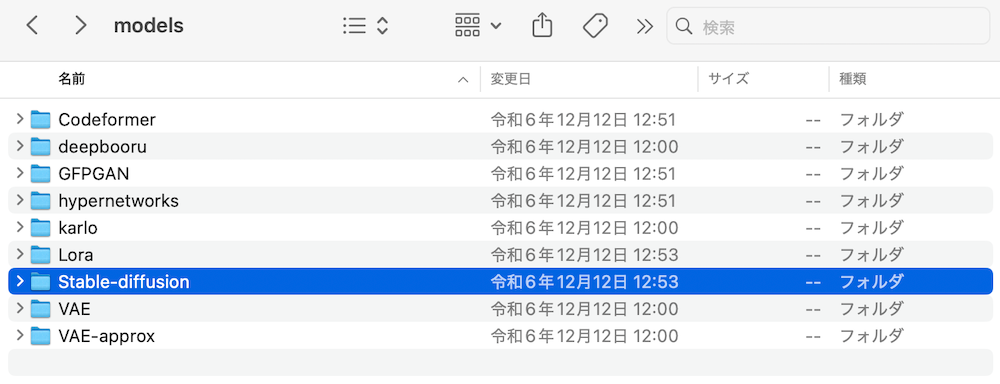
「models」→「Stable-diffusion」の順に開いたら、ここにBaseモデルとRefinerモデルのファイルを格納してください。
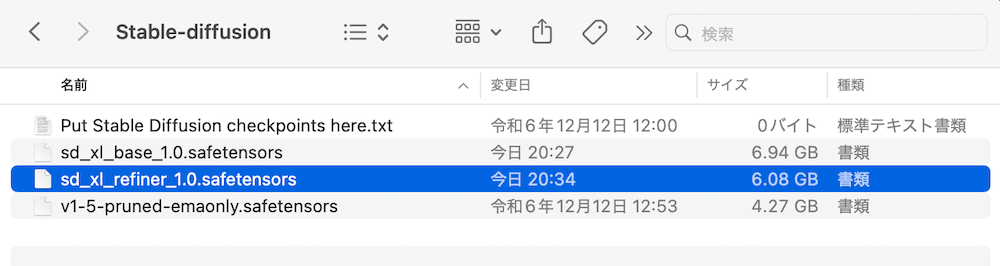
VAEも同じ要領で「models」→「VAE」に格納します。
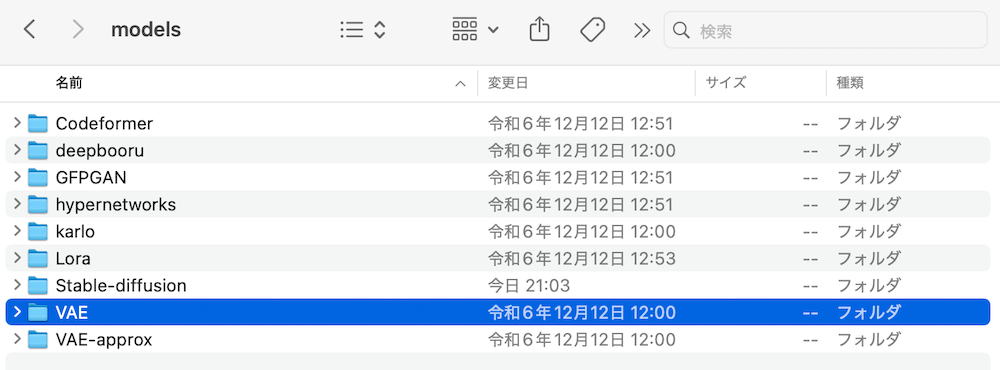
これでファイルの格納は完了です。
Stable Diffusion Web UIを起動してモデルを切り替え
Macの場合はターミナルで以下のコマンドを実行して、Stable Diffusion Web UIを起動します。
bash stable-diffusion-webui/webui.sh
起動後は上記の更新ボタンを押したあと、ダウンロードした「sd_xl_base_1.0.safetensors」を選択してモデルを切り替えてください。
続いて、「txt2img」タブの下部にある「Refiner」横の三角アイコンをクリックします。
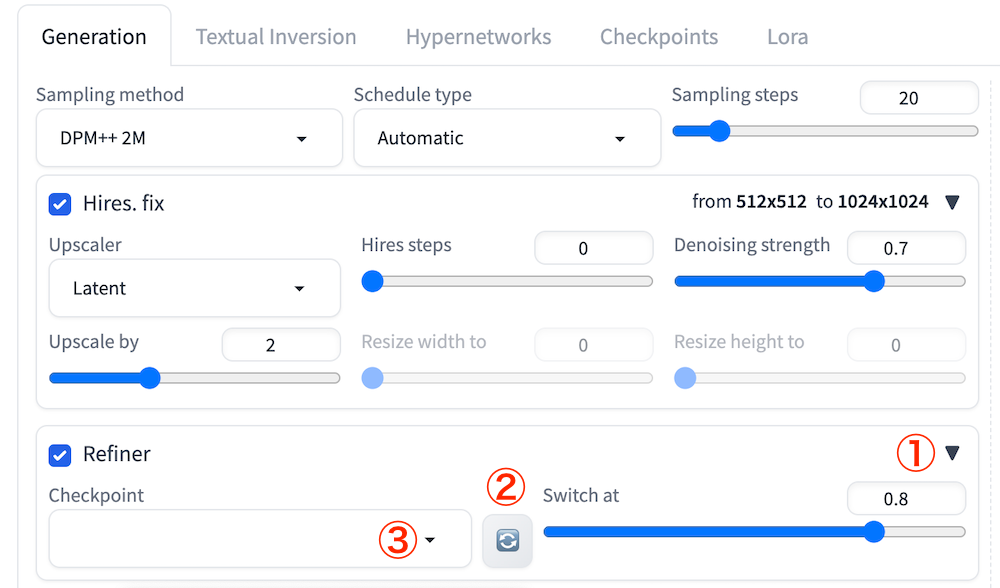
「Checkpoint」の更新ボタンを押してから、プルダウン内で「sd_xl_refiner_1.0.safetensors」を選択してください。
次は「Settings」タブを開いたあと、サイドバーの「VAE」を開きます。その後、「SD VAE」から「sdxl_vae.safetensors」を選択してください。
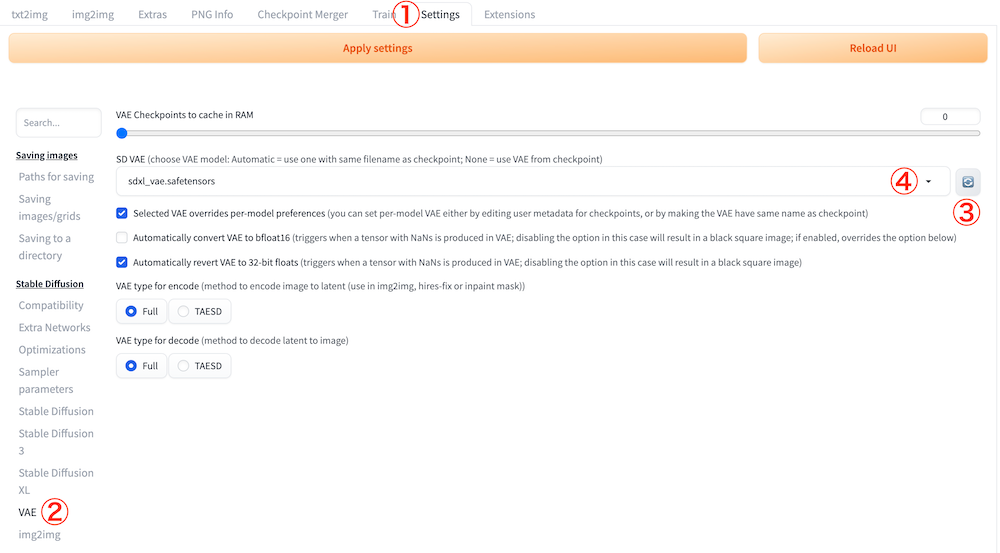
サイドバーの「User interface」を開きます。
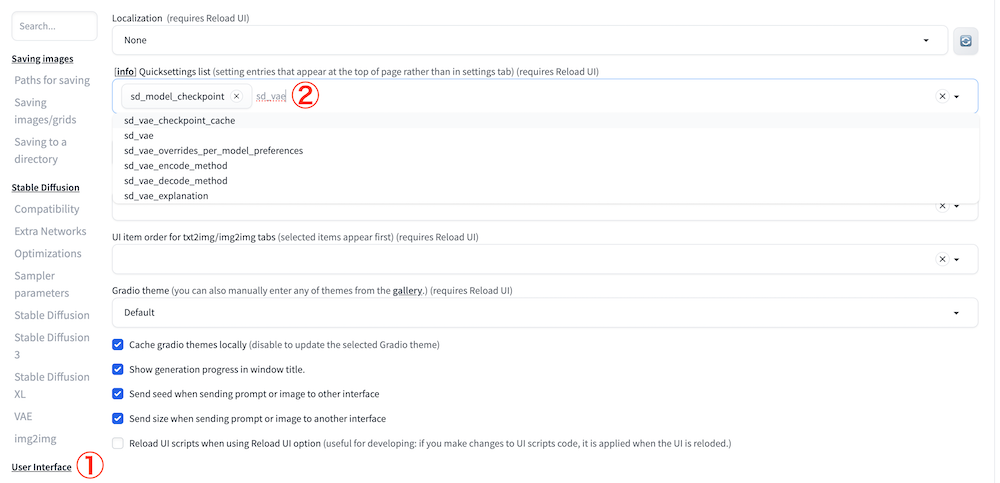
上記画像の②の場所にカーソルを合わせて「sd_vae」と入力して、候補に出てくる「sd_vae」をクリックしてください。
次は「Apply Settings」をクリックして設定内容を保存したあと、「Reload UI」をクリックしてWeb UIをリロードします。
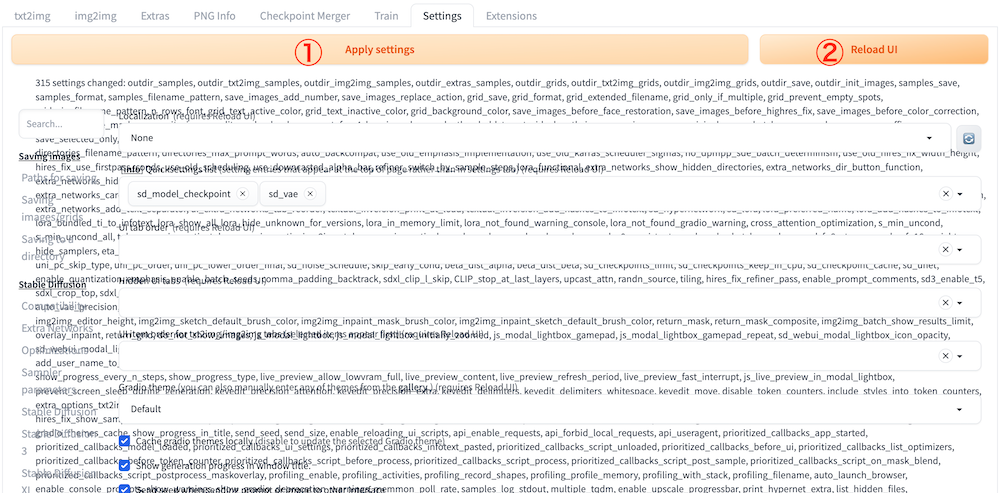
「Apply Settings」をクリックしたあとに一瞬表示がおかしくなりましたが、「Reload UI」でリロードしたあとは解決しました。
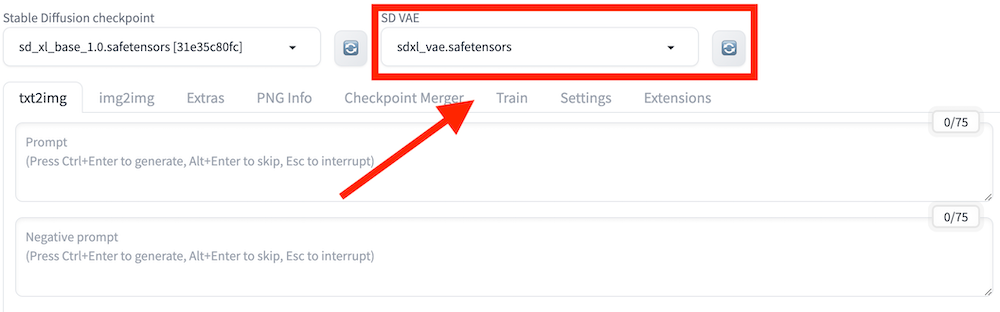
リロード後の画面上部に「SD VAE」が追加されていれば、Stable Diffusion XLを導入する一連の作業は完了です。
なお、Stable Diffusion Web UIについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
Stable Diffusion XLを使って画像を生成してみた
実際にStable Diffusion XLを使って、画像を生成してみました。まずは、以下のシンプルなプロンプトを入れてみます。
Beautiful girl in white dress.(白いドレスを着た美少女)ネガティブプロンプトには「low quality(低い画質)」を入れてみました。
生成された画像がこちらです。

仕上がりはだいぶ微妙ですね…。頭の上に変な物体がありますし、目の表現も綺麗ではありません。今度はノイズの除去回数を示す「Sampling steps」を22に上げてみました。

プロンプトをしっかり把握できており、人物も綺麗な見た目になりましたね。
このように同じプロンプトでも設定をいじるだけで画像の出力精度が変わってきます。まだまだ改善の余地があるので、実際にStable Diffusion XLを利用する際は、色々な設定を試してみてください。
Stable Diffusion XLの活用事例
Stable Diffusion XLは、ただ高精度な画像を作れるだけでなく、使い方の自由度が高いのも魅力です。X(旧Twitter)では、イラスト風の作品から写真のようなリアルな画像、複雑なワークフローの共有まで、多くのユーザーが活用方法を発信しています。ここでは、実際に投稿された事例をいくつか紹介します。
4コマ漫画の自動生成:思い通りの仕上がりに驚きの声
こちらの投稿では、4コマ漫画を自動で作っています。
使われたのはStable Diffusion XLと「Nano Banana Pro」という画像編集ツール。吹き出しの配置やセリフの日本語も自然で、投稿者は「ほとんど思った通りにできた」とコメントしています。手間をかけずに形になるので、気軽に作品づくりを楽しみたい人にとって、参考になる内容です。
写真のようなリアル画像が手軽に作れる新ツールセット
SDXL神アプデでリアル画像が爆誕!
— ハカセ アイ(Ai-Hakase)
Stable Diffusion XLに13種類の写真ツールセットが登場しました!まるでプロが撮ったような写真レベルのリアル画像が簡単に作れますよ!プロンプトの悩みが解決ですね#SDXL #画像生成AI pic.twitter.com/iGurTj9TrV
最新トレンドAIのためのX


別の投稿では、13種類の新しい写真用ツールセットが紹介されていました。
これを使うと、まるでプロのカメラマンが撮影したようなリアルな画像が生成できるとのことです。細かいプロンプトを工夫しなくても、それなりに自然な仕上がりになるのがポイント。特に初心者には嬉しい機能で、「リアル画像が簡単に作れる」といった声も見られました。
独創的な表現スタイル
この投稿では、Stable Diffusion XLを使った画像をRedditで共有していました。
使われているのはComfyUIというツールで、安定した出力と柔軟な設定が特徴です。生成された画像はどれも個性的で、海外のアーティストのような雰囲気を感じさせます。リアルな写真表現よりも、独自の世界観や芸術性を重視したい人に特に人気があるようです。
SDXLの持つ高い表現力と自由度が活かされており、創作ツールとしての奥深さを感じます。
Stable Diffusion XL対応ツール・サービス一覧
Stable Diffusion XLは、さまざまなツールやクラウドサービスで利用可能です。ローカルでじっくり使いたい人から、クラウドで手軽に試したい人まで、目的に合った使い方が選べます。
以下に、SDXLに対応している主要ツール・サービスを、用途別にまとめました。
| ツール/サービス名 | タイプ | 特徴 | 向いているユーザー | 料金 |
|---|---|---|---|---|
| ComfyUI | ローカルアプリ | ノード型UIで自由度が高く、拡張性が非常に高い | カスタマイズ重視の中〜上級者 | 無料(GPU推奨:CPU可だが非実用的) |
| Stable Diffusion Web UI(AUTOMATIC1111) | ローカルアプリ | 高機能でアドオン多数。SDXL対応の定番WebUI | 中〜上級者/開発者 | 無料(GPU推奨:CPU可だが極めて低速) |
| Google Colab | クラウド | ブラウザだけで利用可能。SDXL用ノート多数 | GPU非搭載PCのユーザー | 基本無料(一部有料) |
| DreamStudio(公式) | 公式クラウド | Stability AI公式。SDXLが最も安定して動く環境 | 初心者〜業務利用者 | 無料枠あり・クレジット制(商用利用可/規約準拠) |
| Mage.space | クラウド | 登録不要ですぐ使える。直感的UIで初心者に最適 | 気軽に試したい人 | 無料プランあり・有料あり(商用利用可/規約準拠) |
| RunDiffusion | クラウド | 高速で安定したクラウドUI。SDXLも即動作 | 商用利用/長時間作業向け | 有料(月額・従量課金) |
| Leonardo AI | クラウド | テンプレ・モデルが豊富。デザイン制作に最適化 | デザイナー/非エンジニア | 無料枠あり・有料あり(商用利用可/設定により制限あり) |
| Hugging Face Spaces | クラウド | SDXLデモ多数。検証・学習用に便利 | モデル検証・技術学習者 | 無料(軽量処理向け/重負荷は有料ハードウェア必要) |
Stable Diffusion XLは、使う環境によって性能や操作感が大きく変わります。
- 自分のPCで細かく調整したい人は ComfyUIやWeb UI
- PCスペックに不安がある人は Google ColabやHugging Face
- インストールなしで使いたい人は DreamStudio、Mage.space
- 商用・長時間利用したい人は RunDiffusionやLeonardo AI
Stable Diffusion XLを利用する際の注意点とトラブル対策
Stable Diffusion XLを利用する際には、高精度で便利な反面、初心者がつまずきやすいポイントも存在します。特に次の4点には注意が必要です。
- 初心者がつまずきやすい導入の壁
- GPUメモリ不足エラーと対処法
- 商用利用・著作権の注意点
- 動作が重いときの改善策
これらを理解しておくことで、トラブルを未然に防ぎ、安定してSDXLを活用できるようになります。
初心者がつまずきやすい導入の壁
Stable Diffusion XLを導入するには、WebUIの環境構築やモデルファイルの配置が必要です。初心者にとっては少し複雑で、手順を誤ると正常に起動しないケースもあります。
公式手順や当記事で紹介している情報を参考にしながら、一つひとつ確実に進めるのがポイントです。
GPUメモリ不足エラーと対処法
Stable Diffusion XLは高度な画像を生成できる分、GPUメモリの消費量が激しいです。GPUが搭載されていないPCでも動作はしますが、画像生成に多くの時間がかかります。
PCのスペック的にローカル環境へのインストールが厳しい場合は、Google Colab上で利用するか、DreamStudioなどのオンライン上で利用する方法を検討してみてください。
SDXLは高精度な分、GPUメモリを大量に消費します。特にVRAMが8GB未満の環境では「out of memory」エラーが発生することがあります。
解像度を下げたり、バッチサイズを小さくすることで改善でき、クラウドGPUの活用も有効な手段です。
商用利用・著作権の注意点
Stable Diffusion XLはオープンソースで公開されていますが、生成した画像を商用利用する場合は著作権や利用規約に注意が必要です。二次創作や特定の版権キャラクターを利用した画像は権利侵害につながる可能性があるため、必ず利用用途を確認しましょう。
安全に活用するためには、公式のライセンス文書や利用規約を事前に確認することをおすすめします。
動作が重いときの改善策
SDXLは旧モデルに比べて動作が重くなる傾向があります。生成時間が長い場合は、解像度の調整やRefinerモデルをオフにする、軽量化モデルを選択するなどの工夫で改善可能です。
さらに、バッチサイズを小さくすることでVRAMの負荷を軽減できます。加えて、クラウドGPUサービスを活用すれば、ローカル環境よりも快適に動作させることができます。
Stable Diffusion XLは無料でも使える?有料版との違いは?
Stable Diffusion XLは、基本的には無料で使えるオープンソースの画像生成AIです。ただし、使い方や使うサービスによってはお金がかかる場合もあります。例えば、「DreamStudio」というサイトでは、最初に少しだけ無料で使える枠がありますが、それを超えるとクレジットを購入して使う仕組みです。
Stable Diffusion XLに関するよくある質問
なお、Stable Diffusionが使えるWebアプリについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

Stable Diffusion XLで高精度な画像生成にチャレンジしよう
Stable Diffusion XLは、プロンプトの理解力や出力する画像の精度が向上しているので、ユーザーニーズに沿った綺麗な画像を出力できます。
とくに、旧モデルと比較して、以下の点が大きく異なるのが特徴です。
- 複雑な構図で画像生成が可能
- パラメーター数が従来のモデルの2倍以上
- 出力精度が上がった
- 最大1,024×1,024の画像が生成可能
導入までの手順は複雑ですが、当記事でも詳しく解説しています。
うまく使いこなせれば、高精度かつ自由度の高い画像を生成できるようになるので、ぜひ利用してみてください。

最後に
いかがだったでしょうか?
Stable Diffusionなどの画像生成AIを活用し、高精度な画像生成で広告バナーやSNS投稿用ビジュアルを迅速に作成。さらに、製品デザインのモックアップ作成を効率化し、時間とコストを削減しませんか?
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。 ︎株式会社WEELのサービスを詳しく見る。
︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、弊社紹介資料もご用意しておりますので、併せてご確認ください。

