

- 約150msの低遅延でライブ音声を途切れず文字起こし可能
- 90以上の言語・アクセントに対応し、雑音環境でも高い認識精度を維持
- VADや手動コミットなど、開発者向けのリアルタイム制御機能が充実している
2025年11月、ElevenLabsが新たな自動音声認識モデルをリリース!
今回リリースされた「Scribe v2 Realtime」は低遅延で音声からテキスト変換が可能です。多数の言語に対応しており、周囲の環境音にも左右されません。
本記事ではScribe v2 Realtimeの概要から仕組み、実際の使い方まで解説をします。本記事を最後までお読みいただければScribe v2 Realtimeの使い方を取得できます。ぜひ最後までお読みください!
\生成AIを活用して業務プロセスを自動化/
Scribe v2 Realtimeの概要
Scribe v2 Realtimeは、ElevenLabsが提供するリアルタイム特化型の音声認識モデルであり、約150msというきわめて低い遅延で文字起こしが可能。※1
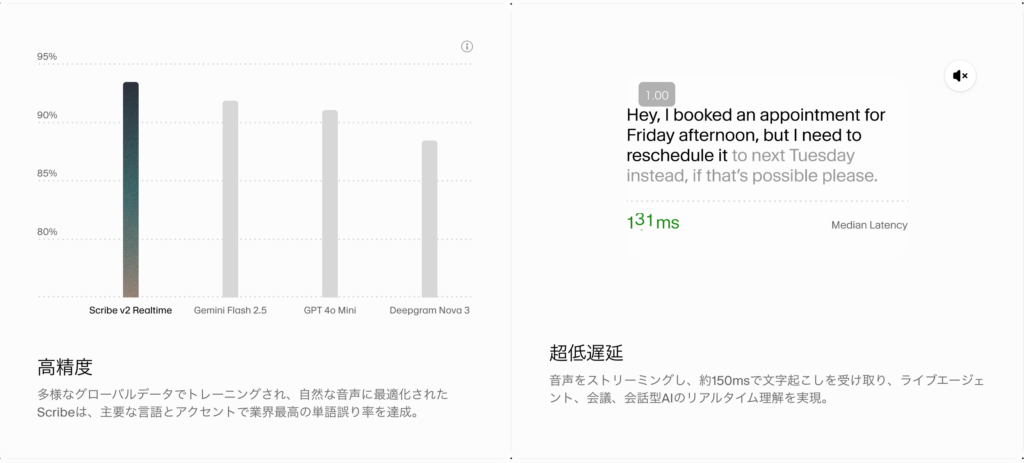
対応言語は90超と幅広く、多様なアクセントや雑音環境でも精度を維持するよう開発されています。単語誤り率の低さは業界上位レベルであり、技術用語や固有名詞を含む複雑な語彙にも対応。
さらに、PCMやμ-lawといった複数のオーディオフォーマットに対応し、電話回線からブラウザ、スタジオ収録環境まで幅広いシーンで利用できます。
音声の開始・終了を判定するVAD、接続再開時に文脈を引き継ぐテキストコンディショニング、文字起こし確定タイミングを制御できる手動コミットなど、開発者向けに柔軟な制御機能が整備されている点も特徴です。
また、SOC2、HIPAA、GDPRなどの主要基準に準拠し、EUデータレジデンシーやゼロリテンションモードも選択できるなど、エンタープライズ環境で求められるセキュリティにも対応しています。これにより、厳格なデータ管理が必要な業務でも安心して導入できる設計となっています。
Scribe v2 Realtimeの仕組み
Scribe v2 Realtimeのリアルタイム認識は、Scribe v2を基盤とした高速化アーキテクチャによって実現。モデル内部では、音声ストリームを即時に解析しながら、最も可能性の高い次語や句読点を継続的に予測する構造が採用されており、これが約150msという低遅延でのテキスト生成につながっています。※1
音声入力はフレーム単位で処理され、各フレームは逐次的にモデルへ渡されます。
モデルはその都度、前後の文脈を踏まえて推論を行い、短いセグメントとして認識結果を返し、連続的な推論と局所的な確定処理を組み合わせることにより、ライブ環境での会話でも途切れのない文字起こしが可能です。
リアルタイム出力の技術
リアルタイムでの安定性を担保するため、音声の開始と終了を自動判定するVADや、接続再開時に文脈を引き継ぐテキストコンディショニングも組み込まれています。これらの仕組みによって、途中で通信が切断された場合でも前後関係を保ったまま認識を継続できます。
また、Scribe v2 Realtimeは開発者がセグメントの確定タイミングを制御できる手動コミット機能を備えており、会話の区切りやアプリケーション仕様に合わせた柔軟な運用が可能。


Scribe v2 Realtimeの特徴
Scribe v2 Realtimeは、ライブ用途に最適化されたリアルタイム音声認識モデルとして設計されており、低遅延・高精度・高い運用性の3点が特徴的です。※1
超低遅延でのリアルタイム認識
Scribe v2 Realtimeの最大の特徴は、約150msという低遅延でテキストを返せる点です。音声ストリームを受け取りながら推論を継続し、短い単位で認識結果を出力する構造を採用することで、会話の流れを阻害しないレスポンスを実現しています。
90超の言語に対応する多言語認識
対応言語は90を超え、日本語・英語だけでなくヒンディー語、ポーランド語、スウェーデン語、中国語など多様な地域言語に最適化されています。アクセントや雑音環境にも強く、国際的なサービスや多文化環境での導入にも適しています。
開発者向けの高度な制御機能
Scribe v2 Realtimeは、リアルタイム運用に求められる制御機能が充実しています。文字起こしの確定タイミングを操作できる手動コミット機能を備え、アプリケーション仕様に合わせた柔軟な切り分けが可能です。また、音声の開始・終了を自動検知するVADや、接続断後も文脈を維持できるテキストコンディショニングも標準搭載されています。
なお、OpenAIの次世代音声認識モデルについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
Scribe v2 Realtimeの安全性・制約
Scribe v2 Realtimeは、エンタープライズ用途にも対応できるよう設計されており、安全性やデータ管理に関する要件を幅広く満たしています。一方で、運用上の制約も存在するため、それらを理解したうえで導入することが重要です。
エンタープライズ基準に準拠した堅牢なセキュリティ
Scribe v2 Realtimeは、主要な国際規格に対応しており、企業利用に必要な安全性が確保されています。SOC2、HIPAA、GDPRといった基準に準拠して提供されており、医療・公共領域を含む厳格なデータ環境でも利用可能。
また、EUデータレジデンシーにも対応しているため、地域ごとにデータの保存先を分離する必要がある場合にも運用が可能です。

データ利用とモデル動作に関する制約
高い安全性を確保している一方で、運用にあたってはいくつかの制約も。
まず、入力可能な音声フォーマットはPCMおよびμ-lawに限定されており、それ以外の形式を利用する場合は事前の変換が必要です。
また、リアルタイム認識では接続の継続性が前提となるため、ネットワークの揺らぎが激しい環境では処理が分断される可能性があります。ただし、テキストコンディショニングにより文脈の継続は可能ですが、完全に途切れを防げるわけではありません。
Scribe v2 Realtimeの料金
Scribe v2 RealtimeのAPIの料金は下記のような設定です。
| Tier | 料金/月 | 利用可能時間 | 時間あたりの料金 | 追加時間あたりの料金 |
|---|---|---|---|---|
| Free | $0 | 利用不可 | 利用不可 | 利用不可 |
| Starter | $5 | 10時間 | $0.48 | 利用不可 |
| Creator | $22 | 48時間 | $0.46 | $0.63 |
| Pro | $99 | 225時間 | $0.44 | $0.53 |
| Scale | $330 | 786時間 | $0.42 | $0.46 |
| Business | $1,320 | 3,385時間 | $0.39 | $0.39 |
上記はScribe v2 RealtimeのAPI料金になります。Tierが上がれば利用可能時間が伸び、時間あたりの料金は抑えられます。
Scribe v2 Realtimeのライセンス
Scribe v2 Realtimeのライセンスについては、明示的な記載は見つかりませんでした。
唯一見つかったのはこちらです。
Free tier requires attribution and does not have commercial licensing.
Speech to Text
無料プランでは商用利用不可とのことなので、もしかしたら課金していれば商用利用が可能になるかもしれません。
なお、Alibaba発の多言語×高精度な音声認識モデルであるQwen3-ASR-Flashについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

Scribe v2 Realtimeの実装方法
Scribe v2 RealtimeはAPIの提供があるため、API経由で利用可能です。
公式ドキュメントがJavaScriptなので、今回はgoogle colaboratoryではなくローカル環境でリアルタイム文字起こしを実装します。
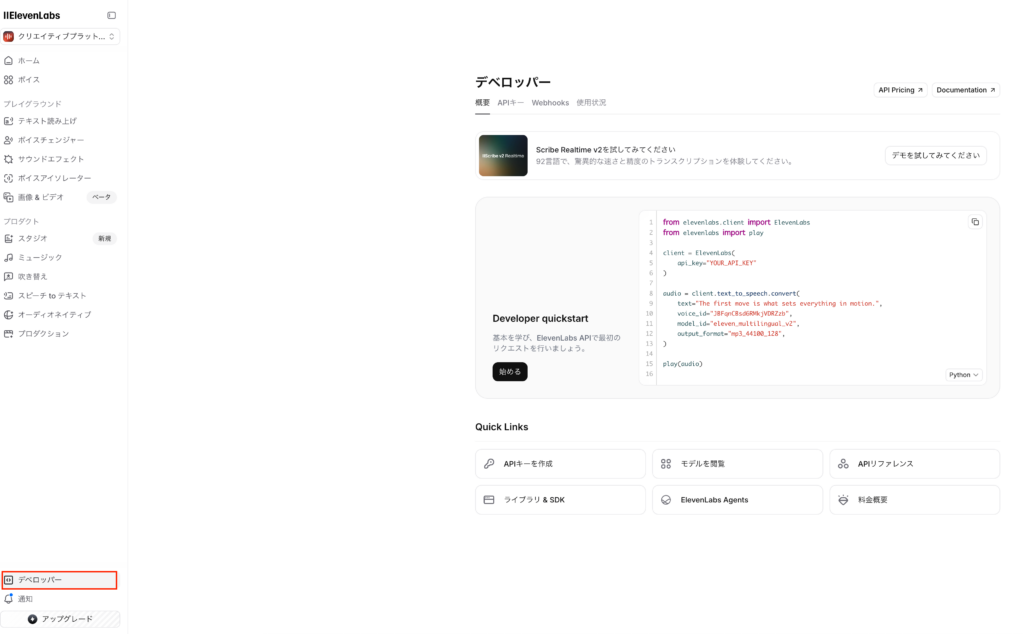
まずはAPIキーを取得しておきましょう。デベロッパーのタブがあるので、そこからAPIキーを作成を選択すればOKです。
また、実行するにあたっての注意ですが、GenSparkを私は使っていたのですが、ブラウザ側でブロックされてしまうようで実行できませんでした。ChromeであればOKです。
APIを使った実装ファイルが下記です。ダウンロードしていただき、APIキーを書き換えていただければ利用可能です。


Scribe v2 Realtimeの活用事例
Scribe v2 Realtimeは、約150msという低遅延でライブ音声を文字起こしできる特徴から、即時性が求められる幅広い領域での活用が考えられます。
会話型エージェントへの組み込み
高いレスポンス性を必要とする会話型エージェントでは、音声入力を即座にテキスト化できることが重要。
Scribe v2 Realtimeは低遅延での文字起こしを実現しているため、ユーザーの発話内容が迅速に処理され、自然な対話体験につながります。
コールセンターや通話支援
電話回線で用いられるPCMやμ-lawに対応しているため、コールセンター業務とも相性が良いモデルです。通話内容をリアルタイムで文字起こしし、オペレーター支援や自動応答システムと連携させることで、業務効率の向上やミスの削減を図れます。
会議記録と議事録作成
会議やオンラインミーティングの場面でも、リアルタイムで文字起こしが行えるため、議事録作成を効率化できます。音声の開始と終了を検出するVADによって、発言区切りが自動的に整うことで、後処理の負担も軽減されます。
Scribe v2 Realtimeを実際に使ってみた
公式ページのトップにデモ版がおいてあるので、手軽に使いたい方はこちらをご利用ください。
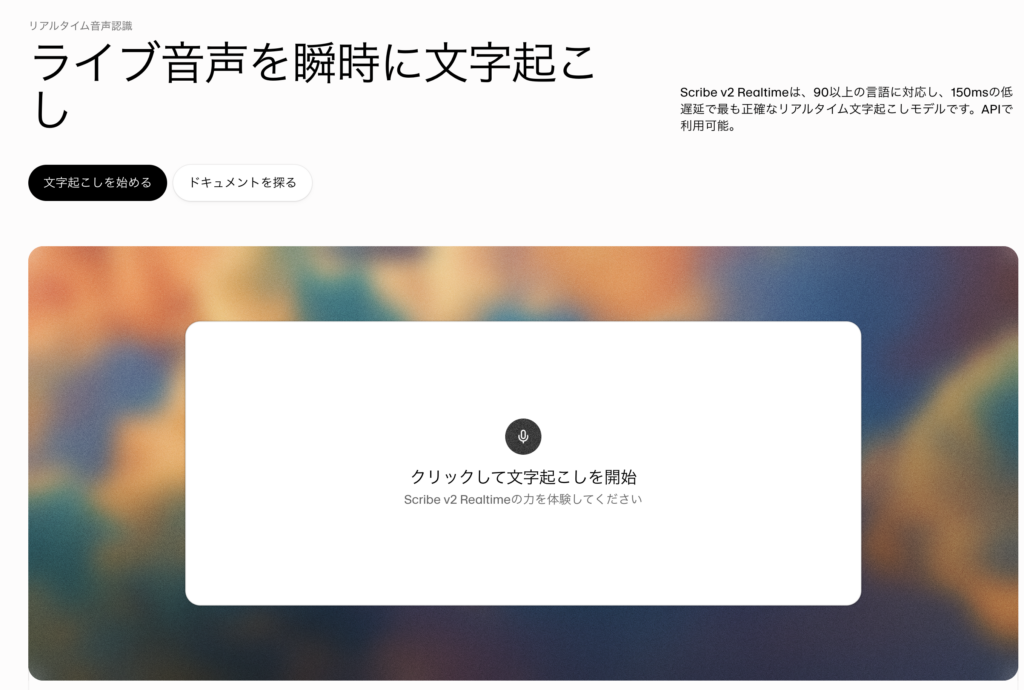
また公式ページからサインアップもしくはログインをしてFreeプランで利用することもできます。
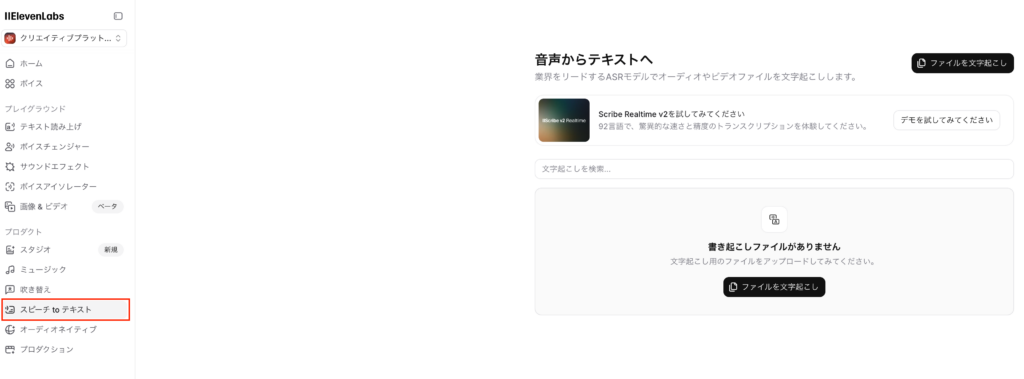
デモ版、API経由どちらでも使ってみましたが、即時的に文字起こしがされ、しかも誤字脱字がありませんでした。
もしかしたら話している分量が少ないからかもしれませんが、精度も高いなと感じます。ちなみに話者分離にはまだ対応していないようです。※1
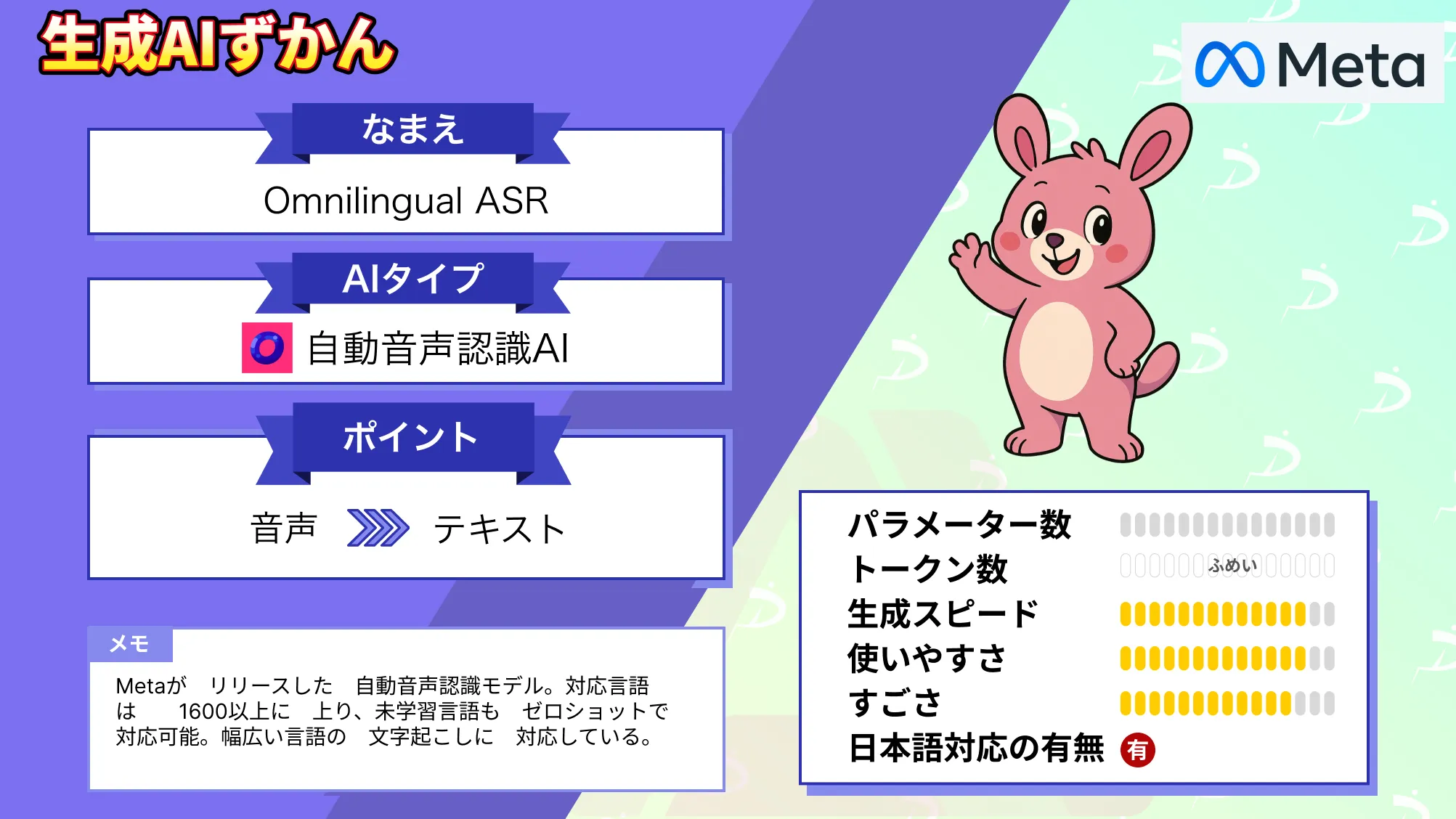
なお、1600言語対応の次世代音声認識モデルであるOmnilingual ASRについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
まとめ
本記事ではScribe v2 Realtimeの概要から仕組み、実際の使い方を解説しました。実際に使ってみて、低遅延は本当であり、かなり有用性が高いなと感じました。
ぜひ皆さんも本記事を参考にScribe v2 Realtimeを使ってみてくださいね!

最後に
いかがだったでしょうか?
Scribe v2 Realtimeを実際に試して、リアルタイム音声認識の新しい基準を体験してみませんか?
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。 ︎株式会社WEELのサービスを詳しく見る。
︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

