- 世界1600以上の言語をゼロショットで扱える、現時点で最も広範なASR
- 自己教師あり学習+LLMデコーダにより、未学習言語でも高い汎用性を発揮
- オープンソースで無料利用可能で、研究用途から実サービスまで幅広く応用可能
2025年11月、Metaから新たなモデルが登場!
今回リリースされた「Omnilingual ASR」は世界1600以上の言語をカバーする大規模な自動音声認識モデルです。
本記事ではOmnilingual ASRの概要から仕組み、実際の使用方法について解説をします。本記事を最後までお読みいただけば、Omnilingual ASRの理解が深まり実際に使えるようになります。
ぜひ最後までお読みください!
\生成AIを活用して業務プロセスを自動化/
Omnilingual ASRの概要
Metaの研究部門であるFAIRが2025年に公開した「Omnilingual ASR」は、世界で1600以上の言語をカバーする大規模な自動音声認識モデルです。
これまで高精度なASRが使えたのは英語や中国語など一部の高リソース言語に限られていましたが、Omnilingual ASRはその常識を覆し、「すべての言語に声を与える」ことを目指しています。
Omnilingual ASRはファミリー構成で提供されており、軽量な300Mモデルから研究用途の7Bモデルまでラインアップされています。
軽量モデルはローカルデバイスや低電力環境での運用を想定しており、クラウド環境に依存せず利用できるのも魅力。また、基盤となる「Omnilingual wav2vec 2.0」はASR以外の音声関連タスクにも応用可能で、研究・開発の双方に開かれた設計になっています。
Omnilingual ASRの仕組み
Omnilingual ASRは、音声を文字に変換するASRの仕組みを根本から再設計。特徴的なのは、自己教師あり学習と大規模言語モデルアーキテクチャの融合によって、未学習の言語でも汎用的に理解できる点です。
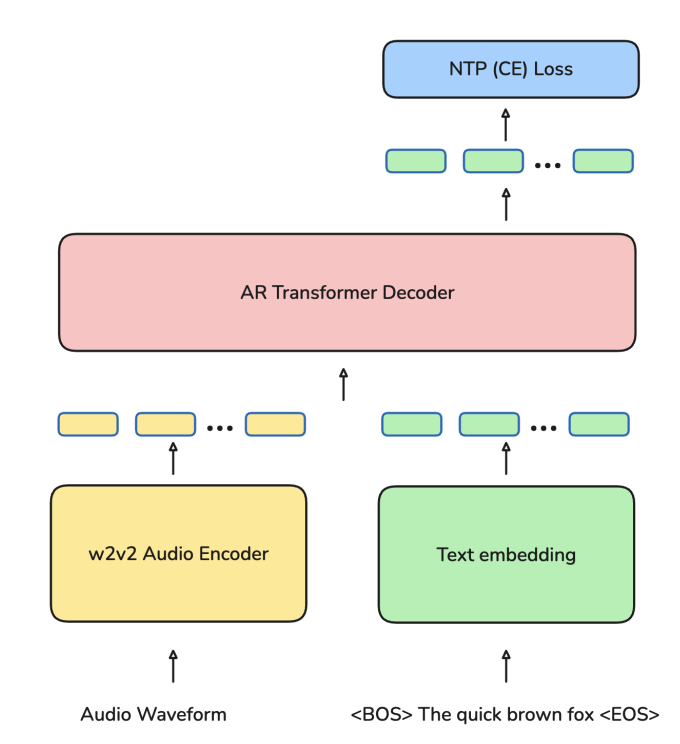
モデル全体は大きく「エンコーダ」と「デコーダ」の2段構成になっています。
エンコーダが音声波形を意味のある特徴量に変換し、デコーダがそれを文字列に変換。従来のASRと異なり、このプロセス全体が多言語かつゼロショットに対応するよう設計されています。
7Bパラメータ規模のOmnilingual wav2vec 2.0
音声理解の基盤となるエンコーダには、Metaが新たに開発した「Omnilingual wav2vec 2.0」を採用。これは従来のwav2vec 2.0を多言語対応に拡張した自己教師あり学習モデルで、1600以上の言語から集めた膨大な未ラベル音声を使って訓練されています。
この自己教師あり学習では、モデルが音声の一部をマスクし、欠落部分を予測することで音声構造を理解。結果として、文字情報を使わずに音声の意味的特徴の抽出が可能です。
学習済みエンコーダは7Bパラメータに拡張されており、これまでの多言語ASRよりも圧倒的に高い表現力を持ちます。

LLMに着想を得た言語理解機構
エンコーダで得た音声表現は、Transformerベースのデコーダによって文字列に変換。ここで特徴的なのは、2種類のデコーディング方式を併用している点です。
1つは「CTC」ベースの方式で、音声と文字の時間的整合性を保ちながら直接変換を行うシンプルな構造。
もう1つは「LLM-ASR」と呼ばれる方式で、大規模言語モデルの推論能力を取り入れたTransformerデコーダを使います。これにより、音声文脈の理解力が向上し、未知の言語や曖昧な発音にも強くなっています。
特にLLM-ASR方式では、推論時にわずかな音声テキストペアを入力することで新しい言語に対応できる「インコンテキスト学習」が機能します。


Omnilingual ASRの特徴
Omnilingual ASRは、単なる多言語対応モデルではありません。世界中の誰もが、自分の言語でAIと対話できるように設計された、包括的かつ拡張可能な音声認識フレームワークです。
史上最大規模の言語カバレッジ
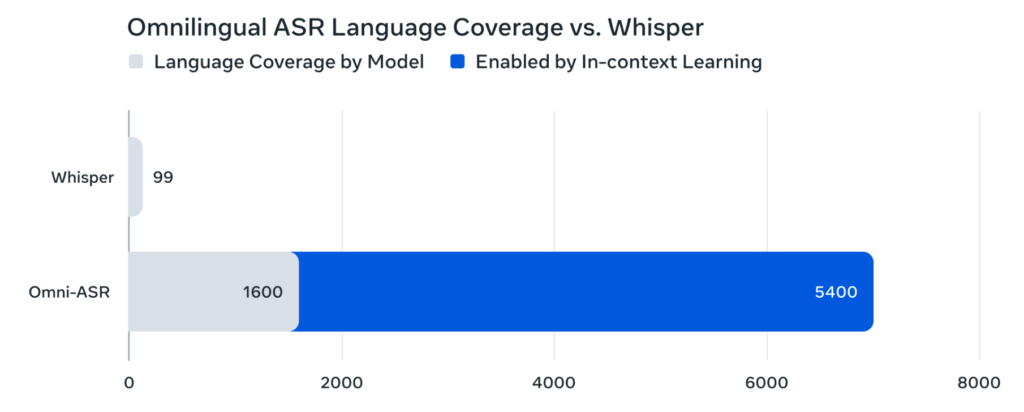
Omnilingual ASRは、1600以上の言語をサポートしています。そのうち約500言語は、これまで一度もASR技術の対象になったことがありません。
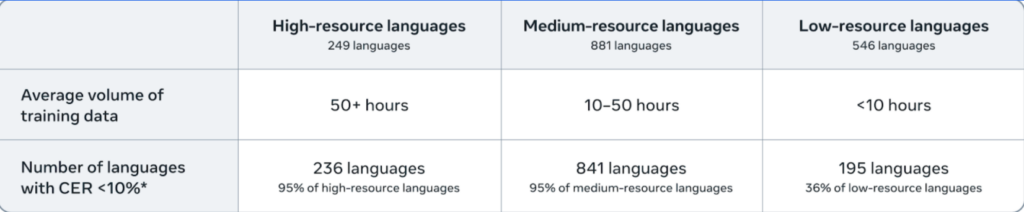
このカバー範囲は、GoogleのUSMやMeta自身のMMSをも超える規模であり、現存するASRモデルの中で最大です。
対応言語の多くは、教育・行政・文化活動において十分なデジタル資源を持たない「ロングテール言語」です。
ゼロショットで新言語に対応
従来のASRモデルでは、新しい言語を扱うために数百時間分の音声データと大規模な再学習が必要でした。しかしOmnilingual ASRは、わずか数例の音声とテキストを提示するだけで未知言語を認識可能にします。
これは、LLM的な「インコンテキスト学習」をASRに応用した初の試みです。
言語の専門家や研究機関だけでなく、地域コミュニティの話者自身が自分の言語をAIに教えられるようになった点で、音声認識の民主化を象徴する技術と言えます。
モデルファミリー構成と柔軟な運用性
Omnilingual ASRは単一のモデルではなく、用途に応じて選べる複数のファミリーとして提供されています。
軽量な300Mモデルから、最高精度を誇る7Bモデルまで幅広くラインアップされており、研究開発から現場導入までカバーできます。
軽量モデルはローカルデバイスやエッジ環境でも動作する設計で、通信環境が不安定な地域でも利用が可能です。一方で、7Bモデルはクラウド環境で動作し、大規模音声処理や多言語解析などに最適化されています。
なお、92言語を高速・高精度に繋ぐ次世代翻訳LLMであるQwen3‑MTについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
Omnilingual ASRの安全性・制約
Metaの研究チームは、Omnilingual ASRの導入が持つ社会的影響とリスクを明確に認識しています。論文では、同モデルの多言語対応能力が「社会的包摂を促す一方で、監視や不当な検閲といった用途にも転用され得る」ことを指摘しています。
このため、著者らはコミュニティ主導のガバナンスと継続的な対話の必要性を強調しています。技術提供を一度限りの支援ではなく、利用者側と共同で管理・調整する「参加型の運用体制」が求められると述べています。※1
Omnilingual ASRの料金
Omnilingual ASRは無料で利用できるオープンソースモデルです。MetaがGitHub上で公開しており、誰でもダウンロード・実行・改変が可能です。商用利用も制限されていません。


Omnilingual ASRのライセンス
Omnilingual ASRは、モデルとコードに関してはApache License 2.0で公開されています。このライセンスは商用利用・改変・再配布を広く許容するオープンソースライセンスであり、研究開発から産業応用まで幅広い利用が可能。
| 利用用途 | 可否 |
|---|---|
| 商用利用 |  |
| 改変 | |
| 配布 | |
| 特許使用 | |
| 私的使用 | |
学習と検証に用いられた音声データはCreative Commons BY 4.0で公開。このライセンスは商用利用・改変・再配布を広く許容するオープンソースライセンスであり、研究開発から産業応用まで幅広い利用が可能。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | |
| 改変 | |
| 配布 | |
| 特許使用 |  |
| 私的使用 | |
なお、見て・理解し・行動する次世代マルチモーダルAIであるQwen3-VLについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
Omnilingual ASRの実装方法
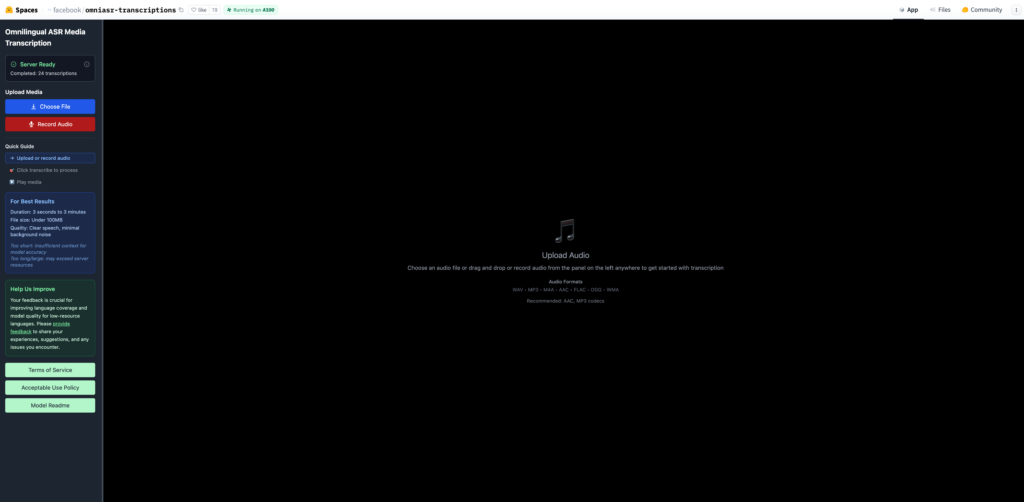
Omnilingual ASRはデモ版もしくはGitHubからダウンロードしてローカル環境で実行する2通りがあります。
デモ版は上記URLにアクセス後、ファイルをアップロードすればすぐに利用可能です。
サンプル音声のCM原稿(せっけん)をダウンロードして、アップロードしてみました。
結果はこちらです。
無添加のシャボン玉石 ⁇ なら もう安心 天然の保出成分が含まれるため 肌にうるおいを与え 即やかに保ちます お肌のことでお悩みの方は是非一度 無添加シャボン玉石 ⁇ をお試しください お求めは 0120 0 055 九5までQwen3-ASR-Flashでも同じ音声で文字起こしをしていますが、その時の結果と比べるとQwen3-ASR-Flashに軍配が上がります。
ただ、Omnilingual ASRの特徴は音声認識の精度というよりも幅広い言語に対応していること、未学習の言語にもゼロショットで対応できることかと思いますので、使い分けが必要ですね。
Omnilingual ASRの活用事例
Omnilingual ASRは、世界1600以上の言語に対応する高汎用ASR基盤として、研究・教育・地域コミュニティなど多様な場面で活用できそうです。ここではResearch paperを元に活用事例をいくつか紹介します。
低リソース言語の音声認識研究
Omnilingual ASRの最初の用途として挙げられるのが、低リソース言語に対する音声認識精度の改善研究です。
MetaのFAIRチームは、これまでASR技術が存在しなかった500以上の言語に対して初めてAIによる文字起こしを実現しました。この成果は、音声認識研究の分野で大きな転換点となっています。
既存の多言語ASRモデルでは対応できなかった言語に対しても、Omnilingual ASRはゼロショットで利用可能。
そのため、各国の大学・研究機関では、言語学・音声処理・自然言語処理の分野で新しいベンチマークや評価手法の基盤モデルとして採用されています。※2
アクセシビリティと多言語サービスの基盤
Omnilingual ASRは、多言語アクセシビリティ向上の基盤技術としても活用が期待されています。
Metaは、音声テキスト変換を通じて、教育・行政・医療などの分野での情報格差を縮小することを目的に、この技術をオープン化。特に、テキスト入力が困難な言語環境や、識字率の低い地域では、音声認識によるコミュニケーション支援が実用的な解決策となります。
この分野では、研究機関だけでなく、社会起業団体や教育NPOもOmnilingual ASRを利用し、地域言語での音声教材・字幕生成・情報アクセシビリティツールの開発を進めていると報告されています。※1
Omnilingual ASRを実際に使ってみた
先ほどは日本語を文字起こししたので、今度は英語を文字起こししてみたいと思います。
今回はこちらの音声を使って文字起こしをします。
結果はこちら。
what yoshi did was unbrand i was space that i was so that i was so that i was so that i was so that i was so that i was so that i was so that i was so that i was so that i was so that i was so that i was so that i was so that i was so that最初だけは適切に文字起こしされていますが、それ以降は同じ単語の繰り返しになってしまっています。
もしかしたら複数人が同時に話している、バックミュージックが影響しているかもしれません。やはり精度で言えばQwen3-ASR-Flashが良さそうです。
なお、日本語含む10言語対応の多言語音声生成モデルであるQwen3-TTS-Flashについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
まとめ
本記事ではOmnilingual ASRの概要から仕組み、実際の使い方について解説をしました。これまで学習に時間のかかっていたASRですが、Omnilingual ASRの技術を使えば、未学習言語であっても自動音声認識をさせることができそうです。
皆さんもぜひ本記事を参考にOmnilingual ASRを使ってみてください!

最後に
いかがだったでしょうか?
多言語サービスの強化、グローバル展開、音声データの利活用をご検討中の企業様は、ぜひお問い合わせください。
貴社の環境・要件に応じて、最適なASR導入・運用のソリューションをご提案します。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。 ︎株式会社WEELのサービスを詳しく見る。
︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

