院生がわかりやすく解説この記事はベクトルデータベースの概要について、従来のデータベースと比較しながら説明しています。
AIについて研究している大学院生の方と協力して書きました。
最後まで読んでいただくと、ベクトルデータベースとは何かわかります。
ぜひ最後までご覧ください!

ベクトルデータベースとは?
ベクトルデータベースとは、その名の通り、ベクトルという数学的概念を用いてデータを管理するデータベースシステムのことを指しています。
この説明だとわかりにくいと思うので、ベクトルデータベースの特徴を以下にまとめました。
- 高次元データの処理能力:大規模なデータセットや高次元のベクトルデータを効率的に処理できます。
- 類似性検索の高速性:データ間の類似度を計算し、最も似ているアイテムを迅速に検索できます。
- スケーラビリティ:データ量の増大に対しても性能を維持しやすい設計がなされています。
- リアルタイム処理:クエリに対する応答時間が短く、リアルタイムでのデータ分析が可能です。
- 非構造化データのサポート:テキスト、画像、音声などの非構造化データを数値ベクトルに変換して取り扱うことができます。
- 柔軟なデータ構造:様々なタイプのデータを一定の形式に変換せずに扱うことができます。
- 機械学習との統合性:機械学習モデルが生成するベクトル表現をそのまま利用してデータの保存、検索、分析が行えます。
これらの性能によって、ベクトルデータベースは多様なAIアプリケーションにおいて、中心的な役割を果たしています。
ベクトルデータベースについてもう少し詳しく説明するために、以下ではベクトルとデータベースに分けてそれぞれの意味を解説していきます。
ベクトルとは
ベクトルとは、高校数学でも習うように、大きさと向きを持つ量を表すためのものです。多次元空間内での位置関係や特徴を表現することができ、その性質を利用してデータ間の類似性などを計算します。
具体的には、機械学習やデータ分析の領域でよく用いられています。例えば、商品やユーザーの特徴を多次元のベクトルで表現し、それぞれのベクトル間の角度や距離を計算することで、類似度を測定します。これにより、高度な検索や推薦などのタスクが可能となります。
身近な応用例だと、AmazonやYouTubeのレコメンドシステムにも使われています。
YouTubeの場合、1つ動画を見たら、その動画の関連動画が出てくると思います。これは、動画1つ1つをベクトルに見立てて、システムが「似ているか否か」を判定し、「似ている」と判定された動画たちが表示されているのです。

ベクトルデータベースは、こうしたベクトルの特性を活かし、YouTubeの動画のような高次元データや非構造化データも、効率よく格納し、処理することが可能になります。
データベースとは
データベースは「データを効率的に管理、検索、分析するためのシステム」を指しています。ちなみに、データとは「情報そのもの」のことです。
ここでは、データベースとデータの違いについても解説しておきます。
ベクトルデータベースにおける「データ」と「データベース」の違いを理解するには、基本的な概念を把握することが重要です。
データ(Data)
- 定義: データは、情報の基本的な単位です。これは、数字、テキスト、画像など、様々な形で存在できます。
- ベクトルデータベースにおける役割: ベクトルデータベースでは、データはしばしばベクトル形式に変換されます。この変換は、非構造化データ(例えばテキストや画像)を数値ベクトルに変換し、これをデータベースで効率的に処理することを可能にします。
データベース(Database)
- 定義: データベース(DBと略されることが多い)は、データを整理・保存し、アクセスするためのシステムです。これはデータの集合を管理し、クエリに基づいて情報を取りだす機能を提供します。
- ベクトルデータベースの特徴: ベクトルデータベースは、特にベクトル形式のデータを効率的に扱うように設計されています。これには、類似性に基づく検索(例えば最も近いベクトルを見つけること)や高次元データの高速処理などの機能が含まれます。
ベクトルデータベースは、特にベクトル化されたデータを取り扱うことに特化しており、類似性検索や高度なデータ解析を可能にする高度な機能を備えています。
ベクトル埋め込みとは
ベクトルデータベースを理解する上で重要な概念「ベクトル埋め込み(Vector Embedding)」についても説明をしておきます。
ベクトル埋め込みとは、高次元のデータセットを、より低次元のベクトル空間に変換するプロセスを指します。この変換により、複雑なデータ構造や関係性を保持しながら、データの操作や解析を効率的に行うことが可能になります。
ベクトル埋め込みの主な特徴と用途:
- 次元削減:ベクトル埋め込みは、大規模なデータセットや複雑なデータ構造をより扱いやすい形式に変換するために用いられます。例えば、テキストや画像のような非構造化データを数値ベクトルに変換し、これをデータベースで効率的に処理します。
- 類似性の計算:ベクトル空間に変換されたデータは、類似性を計算するのに適しています。例えば、ベクトル間の距離(後述するユークリッド距離やコサイン類似度など)を計算することで、アイテム間の類似性を測定可能です。
- 機械学習との連携:機械学習モデルは、多くの場合、入力データをベクトル形式で受け取ります。ベクトル埋め込みは、これらのモデルにデータを供給するための前処理ステップとして機能します。
- 検索と推薦システム:ベクトル埋め込みは、検索エンジンや推薦システムにおいて重要な役割を果たします。類似性に基づいてアイテムを検索したり、ユーザーの好みに合った推薦を生成したりする際に使用されます。
ベクトル埋め込みは、データの特性や関係性を保持しながら、効率的な計算や解析を可能にする強力なツールです。
ベクトルデータベースは、これらの埋め込みベクトルを利用して高速で精度の高い検索やデータ分析を実現します。
大規模言語モデル(LLM)におけるベクトルデータベースとは
大規模言語モデル(LLM)は、自然言語処理(NLP)技術を使用して大量のテキストデータから学習する機械学習モデルです。テキストの生成、翻訳、要約など、さまざまな言語タスクを実行できます。
その中においてベクトルデータベースは、データをベクトル(数値の配列)として保存し、検索します。この特性は、LLMが生成する大量のテキストデータや、言語データを効率的に処理するのに特に有用です。
例えば、ユーザーが入力した質問に対して最も関連性の高い回答を検索する際、LLMはテキストをベクトルに変換し、ベクトルデータベース内で類似性の高いベクトルを検索します。これにより、関連する情報を迅速かつ正確に見つけることができます。
LLMにおけるベクトルデータベースは、膨大な言語データを効率的に処理し、高度な自然言語処理タスクを可能にするための強力なツールです。


ベクトルデータベースの仕組み
ベクトルデータベースでは、機械学習やベクトル埋め込みなどの手法でさまざまな情報をベクトルに変換しています。そして、データベースにある無数のベクトルから類似性を検索しているのです。
例えば、下記の表はECサイトでユーザーが何に関心があるかを購入点数で表しています。
こちらの表を見るとBとCの類似性が高いと判断できるはずです。実際には、ユークリッド距離・コサイン類似度・内積などを用いて類似性を測っています。
このように、膨大なデータをベクトルで表し類似性のデータを抽出するのがベクトルデータベースの仕組みなのです。
ベクトルデータベースにおける検索の原理
データベースが持つデータに対する要求(データの検索や更新など)をクエリといいます。
今回は、ベクトルデータベースのクエリ処理の「検索」について話します。
ベクトルデータベースでの検索では、以下の大きな流れをたどります。
- 検索時の類似度指標を決める
- 生データをベクトル化
- ベクトルデータをDBに格納
- ベクトルデータを抽出し, 近似最近傍探索
- クエリに対する最近傍の検出(検索)
それでは順番に見ていきましょう!
1. 検索時の類似度指標を決める
最初に行うことは、ベクトルの類似性を測るための、類似度指標を決めることです。
類似度指標によって用途が異なるため、必要に応じて使い分ける必要があります。
ベクトルの類似性を測るには、主に以下の3つが使われます。
- ユークリッド距離
- コサイン類似度
- 内積
どれもベクトル間の類似度を測るための指標として、よく使われます。
例えば、ユークリッド距離はベクトルの大きさも考慮したい場合などに使います。
また、コサイン類似度や内積は、ベクトルの大きさは考慮せず、ベクトルの向きだけに着目したい場合に用います。
分かりやすくするために、「ベクトルの大きさを考慮したい場合」や「ベクトルの向きだけに着目したい場合」の具体例を以下に示します。
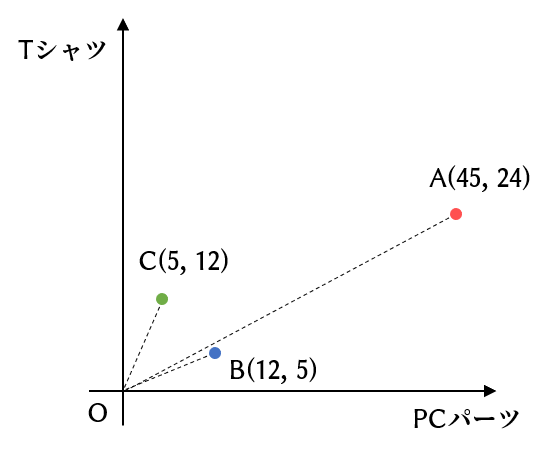
まず、下にあるレコメンドシステムの図をご覧ください。
この図は、各カテゴリの購入点数でベクトル表現したものから、各ユーザー間の好みの類似度を可視化するための図です。
各ユーザー(A, B, C)が何に関心があるかを、各カテゴリの購入点数でベクトル表現しています。
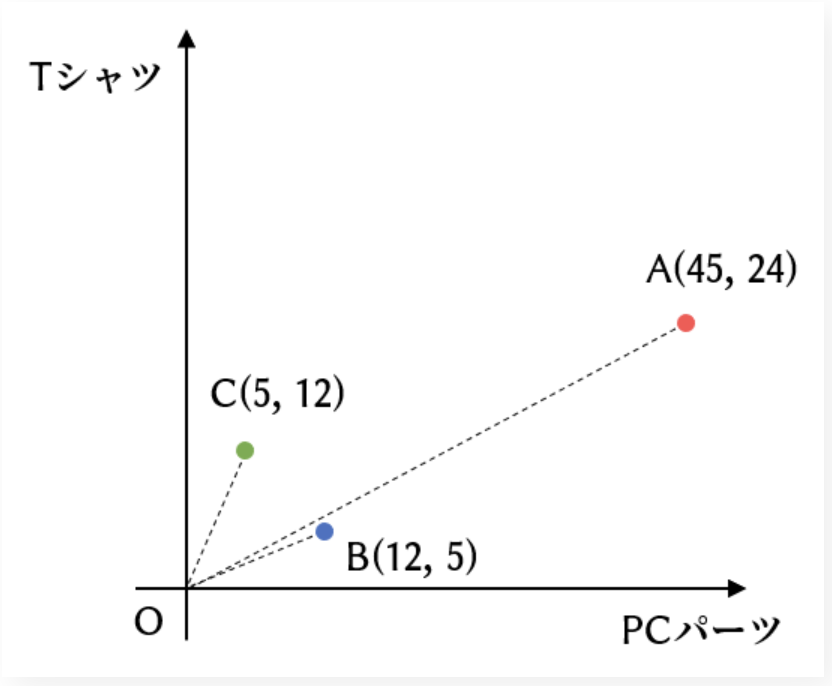
上記の画像を見ると、ユークリッド距離の観点で最も似ているベクトルのペアはBとCです。(ユークリッド距離が一番近いため。)
しかし、コサイン類似度の観点で見ると、角度が一番小さい、つまり最も似ているベクトルのペアはAとBになります。
このように、ベクトルの類似度指標によって結果が異なります。
ベクトルの大きさは「ユーザーの利用頻度」を表しているので、ユーザーの利用頻度を考慮したい場合は、ユークリッド距離を使うのが望ましいです。
一方、それらの利用頻度は考慮せず、単純に商品の購入傾向だけからユーザー間の好みの類似度を計算したい場合は、コサイン類似度や内積を用います。
これらの指標の決め方は、「インデックス」の作成時に引数に渡すだけです。
インデックスというのは、 ベクトルデータを管理する単位のことで、リレーショナルデータベースでいう「テーブル」と同じ位置付けです。
2. 生データをベクトル化
次に、深層学習などの技術を用いて、「生データ」からベクトルを生成します。
生データとは、文書データや音声データなどのことです。
機械が理解できるのは数値のみなので、生データからベクトルを作る必要があります。その中でも、ベクトルは表現力が高く、機械が理解しやすい形です。
ベクトル化のもう一つの重要な利点は、データ間の類似度を測定しやすいことです。具体的には、データ間の類似度を測るためには、ベクトル間の類似度を計算するだけです。これにより、検索時にデータがどれだけ似ているかを簡単に判断できます。
ベクトル化の一例として、文章データを考えてみましょう!以下は、文章がベクトル化された例です。
| 文章例 | ベクトル |
|---|---|
| 猫は可愛い | [0.234, -0.567, 0.890, 0.123, -0.456, 0.789] |
| 今日は晴れた日だった | [0.567, -0.123, 0.456, -0.789, 0.234, -0.567] |
| 人工知能の発展が進んでいる | [0.890, 0.123, -0.456, 0.789, -0.234, 0.567] |
| 最新のディープラーニング技術について学びたい | [0.123, -0.456, 0.789, -0.234, 0.567, -0.890] |
| 自然言語処理の応用は幅広い | [-0.456, 0.789, -0.234, 0.567, -0.890, 0.123] |
このように、Transformerなどのライブラリを用いることで、文章をベクトルに変換することができます。
また、他の深層学習ライブラリを用いることで、「画像→ベクトル」や「音声→ベクトル」のような変換も可能です。
3. ベクトルデータをDBに格納
生データをベクトル化した後は、次にこれらのベクトルをデータベースに格納します。
これは、大量のデータの高速な検索や類似性の比較を可能とするためです。
以下の図は、データの格納時の違いです。ベクトルデータベースでは、ベクトル化したデータをDBに格納しています。
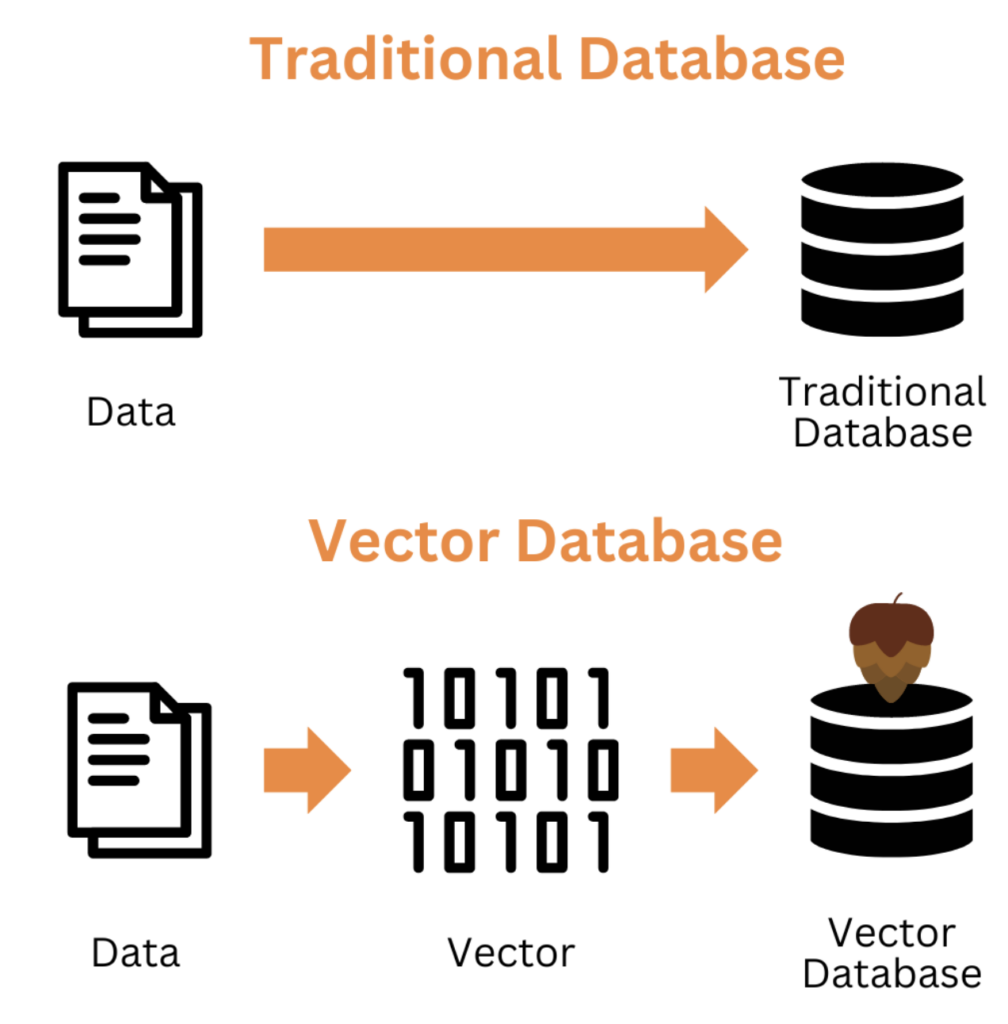
ベクトルデータベースでは、ベクトル化したデータをDBに格納していることがわかりますが、
従来のデータベースでは、生データをそのままDBに入れています。
このように、ベクトルデータベースでは、データをベクトルとしてDBに格納する点が特徴的です。
4. ベクトルデータを抽出し、 近似最近傍探索を行う
データの格納ができたら、近似最近傍探索というベクトル量子化手法を実行します。
この処理は、検索効率を上げるために必要な処理です。
もし、この手法を施していない場合どうなるでしょうか。
仮に、ベクトル数が1,000,000で、それぞれの次元数が1,000だとしたら、1,000,000×1,000個の値全てを確認して検索しなくてはなりません。
そこで、以下のように似た者同士を集め、1つのベクトル(代表点)とみなす処理が考えられました。
こうすることで、似たものだけを検索すれば良いので検索効率がアップしました。
ただし、正確性と速度はトレードオフの関係にあるため、検索精度をある程度犠牲にしなければなりません。
代表点からの距離が近ければ、より細かく検索することになるので、正確性は上がります。
反対に、距離を大きくとって、「ある程度近ければ1つのベクトルでいいよ」というふうにすれば、処理速度は上がります。距離を大きくとるということは、おおざっぱに探索するイメージです。
5. クエリに対する最近傍の検出(検索)
最後に、クエリに対して似たデータの検索です。
先ほどは、似たベクトルたちを1つの「グループ」にまとめました。ここの検索では、クエリと似ている「グループ」を検出します。グループを検出するために、「代表点」を見つけています。
つまり、「クエリのベクトル」と「DB内の代表点のベクトル」との類似度を計算しているのです。
ここまでが、ベクトルデータベースにおける検索の仕組みです。
なお、ChatGPTに自社データを学習させる方法が気になる方は、以下の記事もご覧ください。

ベクトルデータベースと従来のデータベースとの違い
現代の情報社会において、データは様々な形で存在します。
これまでは主に
- リレーショナルデータベース
- グラフデータベース
などのシステムを用いてデータを管理してきました。
しかしその性質上、リレーショナルデータベース・グラフデータベースとベクトルデータベースの間にはいくつかの重要な違いが存在します。
以下の表は、それらの主な違いを簡潔に示しています。
| ベクトルデータベース | リレーショナルデータベース | グラフデータベース | |
|---|---|---|---|
| データ表現 | ベクトル | 表 | ノード(点)とエッジ(線)のグラフ |
| データの処理速度 | 高次元データにおいても処理速度が速い | データの規模が大きくなるにつれて処理速度が落ちる | 関連するデータを高速で処理できる |
| 対応するデータの種類 | 非構造化データも可能 | 構造化データ | 関係性が複雑なデータやネットワークデータ |
| クエリ処理 | ベクトル間の類似度や距離に基づくクエリ処理 | テーブル間の関係や条件に基づくクエリ処理 | ノード間の関係性に基づくクエリ処理。 |
| 得意とする用途 | 画像、音声、テキストなどの非構造化データの検索。 | 在庫管理システム、顧客情報管理、会計システムなどの構造化データの管理。 | SNS分析、レコメンドシステムなどの関連性が複雑なデータの分析。 |
ベクトルデータベースと従来のデータベースとの違いについて、以下で詳しく解説していくので、ぜひ参考にしてみてください。
データの保存方法や得意なクエリ
リレーショナルデータベースは、データをベクトルではなく、「表形式」で保存します。また、リレーショナルモデルを使って構造化データを保存し取得することを目的として設計されています。※1
そのため、データの列と行に基づくクエリに最適化されています。
リレーショナルデータベースでは、画像ファイルや音声ファイルに含まれる膨大なデータポイントを効率的に扱うことができません。
一方、グラフデータベースは、データを「グラフ形式」で保存します。これにより、複雑な関係や相互作用を持つデータを直感的かつ動的にモデル化することが可能になります。※2
データの接続性を重視するため、ノード間のパスを追跡するようなクエリに特化しています。
しかしグラフデータベースも、画像や音声などの非構造化データ内の複雑なパターンや類似性を直接的に処理するのには向いていません。
検索処理のコスト
ベクトルデータベースと従来のデータベースでは、検索処理にかかるコストが異なります。
ここでは、リレーショナルデータベースとグラフデータベースの検索処理のコストについて紹介し、ベクトルデータベストとどのように違うのか解説していきます。
リレーショナルデータベースの検索処理のコスト
リレーショナルデータベースで検索を行う場合、ベクトルデータベースと比較すると計算時間がかかります。そう考えられる理由としては、以下の2つです。
- 「データをわざわざDBから出してからベクトル演算」という工程が必要
- 近似最近傍探索のために、外部ツールとのやり取りが必要
詳しく説明していきます!
まず1つ目。
検索処理の中に、ベクトル演算という工程を必要とします。
ベクトルデータベースでは、対象となるデータを直接ベクトル形式で操作でき、一部のデータに対して高度な数値演算(ベクトル演算)を直接適用できるため、短時間で処理が可能です。
これに対して、リレーショナルデータベースでは、必要なデータを一度DBから取り出し、外部の計算環境(例えばPythonなどのプログラミング環境)でベクトル演算を行う必要があります。
この工程は、データの取り出しやデータの変換、そしてベクトル演算自体に時間がかかる可能性があります。
2つ目。
検索スピードをアップさせるために、近似最近傍探索という処理が必要です。
ベクトルデータベースでは、この処理が可能ですが、リレーショナルデータベースでは外部ツールが必要となります。
加えて、これらの要素がプログラムの複雑さを増すため、メンテナンスもより時間を要することになります。
そうすると、データベースと外部ツールとの間で、データのやり取りが増えるため、ベクトルデータベースに比べ遅くなってしまいます。
※DB内には、生データをベクトルデータに変換したものが格納されているとします。
以上2つのようなことがあると、処理を実行するプログラムが複雑になってしまいます。
そうなると、処理時間だけではなく、プログラムの修理や管理にも時間がかかるようになります。
グラフデータベースの検索処理のコスト
またグラフデータベースのデメリットについても、以下のコストが考えられます。
- スケーラビリティの問題
- クエリの複雑性
まず1つ目は、スケーラビリティの問題。
グラフデータベースはノードとエッジの複雑な関係を管理します。大規模なグラフになると、データの量が増えるにつれて、ノード間の接続を追跡し管理するのが難しくなります。これは、大量のデータを扱う場合にパフォーマンスの低下を招く可能性があります。
次に2つ目。
クエリの複雑性の問題です。グラフデータベースのクエリは、リレーショナルデータベースに比べて複雑になることがあります。ノードとエッジの関係性を理解し、それに基づいたクエリを作成する必要があります。このため、クエリの設計や最適化には特別な知識が必要になります。
これらの点は、グラフデータベースが特定の用途には非常に有効である一方で、すべてのデータストレージや処理のニーズに適しているわけではないことを示しています。
適材適所を見極めて、利用することが重要そうですね。
【実演】ベクトルデータベースと従来のデータベースの性能差を比較
ここでは、ベクトルデータベースと従来のデータベースは、どのくらい性能に差があるのか検証したいと思います。ベクトルデータベースのPineconeと従来のデータベースであるSQLを使って、下記の内容を比較しました。
- 検索の計算スピード
- コード記述量
今回は、100次元のベクトルデータを検索します。ちなみに、100次元のベクトルデータは、LLMなどでも使われるほど高次元なデータです。
このベクトルデータをN個用意し、N=100, 500, 1000, 5000, 10000, 20000と変化させた時の、検索スピードを比較します。 さらに、ベクトルデータを検索する際に、どのくらいコード量に違いがでるのかを比較します。
コード記述量を抑えられれば、コードの加筆・修正も容易になり、効率的にデータベースを扱えるようになるのです。まずはPineconeで処理してみます!
Pineconeで処理
まず、Pineconeを用いて、データの検索を行います。ソースコードは以下の通りです。
import pinecone import numpy as np import random, string import time import matplotlib.pyplot as plt # ランダム文字列生成 (idの重複を避けるため) def randomname(n): return ''.join(random.choices(string.ascii_letters + string.digits, k=n)) # Pineconeの初期化 pinecone.init( api_key="2d84de31-820b-4a30-b64f-55733e90c95f", environment="asia-southeast1-gcp-free" ) # インデックスの生成 pinecone.create_index( "quickstart", dimension=100, pod_type="p1" ) # インデックスに接続 index = pinecone.Index("quickstart") # クエリベクトル query_vector = np.random.normal(50,10,100).tolist() data_sizes = [100, 400, 500, 4000, 5000, 10000] # データ量のリスト execution_times = [] # 時間計算量を保存するリスト for size in data_sizes: for i in range(size): # 正規分布に従う乱数ベクトル生成+データの挿入 index.upsert([ {"id": randomname(20), "values": np.random.normal(50,10,100).tolist()} ]) start_time = time.time() # 類似のベクトルの取得 index.query( vector=query_vector, top_k=20, include_values=True ) end_time = time.time() elapsed_time = end_time - start_time execution_times.append(elapsed_time) # 速度表示 plt.plot([100, 500, 1000, 5000, 10000, 20000], execution_times, marker='o') plt.xlabel('data_size') plt.ylabel('time') plt.title('Pinecone') plt.show()次に、SQLで同様の処理をします。
SQLで処理
先ほどは、Pineconeを使用して類似データ検索をしていました。ここでは、従来のデータベースである、リレーショナルデータベースで同様の処理をしてみます。
オープンソースのリレーショナルデータベースである「PostgreSQL」が有名ですが、今回はPythonライブラリの「SQLsqlite3」を用います。実行するのは以下の手順です。
- データベース作成
- データ格納
- データ抽出
- 類似度検索
そして、ソースコードは以下の通りです。
import sqlite3 import numpy as np import time import matplotlib.pyplot as plt data_sizes = [100, 400, 500, 4000, 5000, 10000] # データ量のリスト execution_times = [] # 時間計算量を保存するリスト # クエリベクトル query_vector = np.random.normal(50,10,100).tolist() # コサイン類似度 def cos_sim(v1, v2): return np.dot(v1, v2) / (np.linalg.norm(v1) * np.linalg.norm(v2)) # SQLiteデータベースの接続とカーソルの作成 conn = sqlite3.connect('keyword_search.db') cursor = conn.cursor() # テーブル作成 columns = ['id'] + [f'vector{i}' for i in range(1, 101)] column_definitions = ', '.join([f'{column} INTEGER' for column in columns]) cursor.execute(f'CREATE TABLE database({column_definitions}, PRIMARY KEY (id))') for size in data_sizes: for i in range(size): # データの挿入 vectors = np.random.normal(50,10,100).tolist() # ベクトルデータのリスト(長さは100) vector_values = ', '.join([str(vector) for vector in vectors]) cursor.execute(f'INSERT INTO database({", ".join(columns)}) VALUES (NULL, {vector_values})') # コミットして変更を確定 conn.commit() start_time = time.time() # データの抽出 cursor.execute('SELECT * FROM database') rows = cursor.fetchall() # query_vectorをNumPy配列に変換する query_vector = np.array(query_vector) # rows内の各行とのコサイン類似度を計算する similarities = [] for row in rows: # データベースから取得したベクトルをNumPy配列に変換する db_vector = np.array(row[1:]) # ベクトルはid列以外の要素 # コサイン類似度を計算 similarity = np.dot(query_vector, db_vector) / (np.linalg.norm(query_vector) * np.linalg.norm(db_vector)) similarities.append(similarity) # 上位20件のベクトルを取得する top_indices = np.argsort(similarities)[::-1][:20] # 降順ソートして上位20件のインデックスを取得 top_vectors = [] for index in top_indices: top_vectors.append(rows[index]) # 結果の表示 for vector in top_vectors: print(vector) end_time = time.time() elapsed_time = end_time - start_time execution_times.append(elapsed_time) import matplotlib.pyplot as plt plt.plot([100, 500, 1000, 5000, 10000, 20000], execution_times, marker='o') plt.xlabel('data_size') plt.ylabel('time') plt.title('SQL') plt.show()次に、いよいよ比較の結果を発表します。
検索スピードの比較結果
ベクトルデータを多くしていった時の、計算時間の推移をプロットすると、以下の通りになりました。
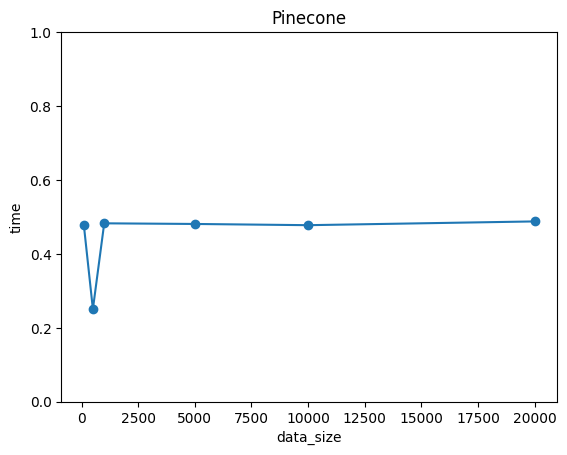
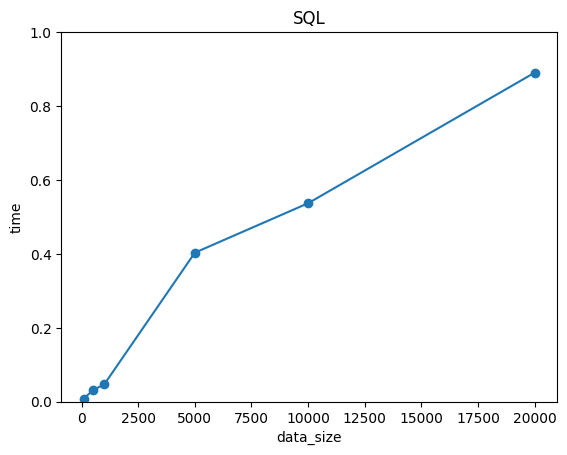
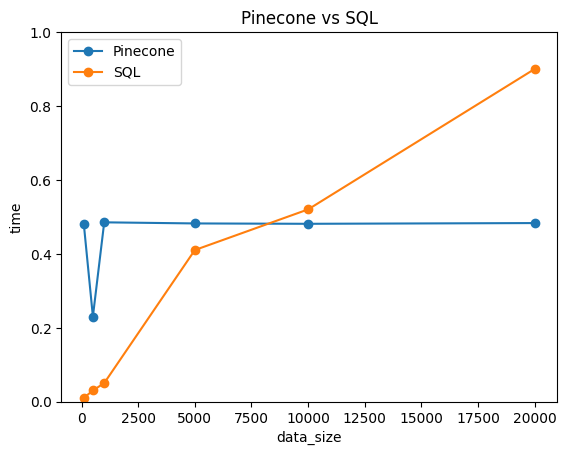
SQLは小規模なデータの計算スピードは速く、大規模なデータになるにつれて大幅に時間が増える結果でした。一方で、pineconeはサンプルサイズによらず、常に0.5付近を推移しているのです。
計算スピードに関しては、N=10000付近でSQLよりも速くなっています。この結果から、NLPやLLMのように「大量の高次元データを扱うタスク」では、ベクトルDBの方が効率的であると分かります。
では、コード記述量の方は、どうなったでしょうか?
コード量の比較結果
コード記述量は、Pineconeに比べてSQLの方が多かったです。
要因としては、Pineconeと違ってSQLでは、
- クエリ処理の際にDBからデータをわざわざ取り出さないといけない
- ベクトルの類似度を計算する実装を自分で行う必要がある
という面倒が追加されたからだと考えられます。
やはり、LLMやデータ解析などでベクトルは必ず使うデータ型なので、ベクトルのままデータベースに格納できるベクトルデータベースの方が圧倒的に便利です。また、SQLの場合は生データのままの格納になるので、わざわざ取り出した生データをベクトルに直す必要があり面倒です。
さらに、類似データの検索という観点でも、Pineconeだとライブラリ側で類似度を勝手に計算してそのままデータを表示できます。一方で、SQLの場合はデータをすべて取り出してベクトルに直し、さらに1つずつ類似度を計算する処理を自分で実装する必要があります。
そのあたりも自動で行ってくれるPineconeの方が、コード記述量も抑えられてやはり便利です。このことから、ベクトルデータを扱うようなタスクでは、Pineconeの方が効率的なコーディング・管理が可能です。
なお、ローコード開発でできることについて詳しく知りたい方は、こちらの記事をご覧ください。

ベクトルデータベースが重要である理由
新しいアプローチであるベクトルデータベースが注目されているのは、進化しつつあるAIにおける「データの特性」と「処理の要求」に非常に適しているからです。
具体的な理由は以下のとおりです。
- 非構造化データの増加: 現代では、画像、ビデオ、音声、テキストなどの非構造化データが爆発的に増加しています。ベクトルデータベースは、これらのデータタイプを効率的に処理し、分析するのに適しています。
- 高速な類似性検索: AIアプリケーションでは、類似性に基づく検索が頻繁に必要とされます。ベクトルデータベースは、類似または関連するアイテムを迅速に検索する能力に優れています。
- 機械学習との親和性: 機械学習モデルは、データをベクトル空間内で解釈します。ベクトルデータベースは、これらのモデルが生成するベクトル表現を直接的に保存・検索できるため、機械学習ワークフローとの統合が容易です。
- スケーラビリティ: AI社会では膨大なデータを扱う必要があります。ベクトルデータベースは、大量のデータセットに対しても高速でスケーラブルな検索を提供します。
- リアルタイム分析: AIアプリケーションはリアルタイムのデータ分析を要求することが多いです。ベクトルデータベースは、リアルタイムでのデータのクエリと分析に適しており、即座の意思決定をサポートします。
これらの理由から、ベクトルデータベースは現代のAI社会におけるデータ処理の要求を満たす重要な技術となっています。
従来型のデータベースの検索のアプローチでは効率が悪い
「検索」は、データベースにおいて重要な処理の一つです。データベースに蓄積された情報の中から、特定の条件に合致するデータを効率的に見つけ出す必要があります。
データベース内の各アイテムを数値のベクトルとして表現し、要求されたベクトルに最も近いアイテムを見つけ出す検索手法を「ベクトルサーチ」と呼びます。
例えば、Amazonなどのレコメンドシステムでは、ユーザーが購入した商品のデータと、類似するDB内のデータを検索し、それらのデータをユーザーに表示します。
従来のデータベースで、構造化データを扱う前提で類似データの検索を行う場合、
- パターンマッチング
- 全文検索
などの手法を用いてましたが、データベース内の全データに対して検索をかけるため、データ数が増えるにつれて効率性は低下します。
Amazonの商品データはDB内に大量にあるので、上記の方法で検索を行うと、かなりの計算時間を必要とするでしょう。これでは、レコメンドシステムの際に、ユーザーにおすすめ商品がなかなか表示されない、という問題が起こります。
この問題を解決するために、
- インデックス
- クラスタリング
- カーネル法
などがあります。これらの手法はデータの特性を利用し、検索効率を向上させることを目指しています。
ただし、リレーショナルデータベースは主に構造化データを扱う設計となっているため、非構造化データを扱う際には限界があります。例えば、画像や音声などの非構造化データをリレーショナルデータベースで直接的に管理しようとするのは難しいです。
そこで、データベース内の特定のカラムに、非構造化データをバイナリ形式で格納するためのBLOBデータ型を使用することがありますが、データの検索や処理は制限される場合があります。
なお、生成AIでシステム開発する方法が詳しく知りたい方は、以下の記事をご確認ください。

ベクトルデータベースで解決できる問題と具体的な用途
従来のデータベースと異なり、ベクトルデータベースはベクトル間の類似度や距離に基づくクエリ処理が可能で、非構造化データや高次元データも効率的に処理できます。
これにより、画像や音声といったメディアデータの検索や分析といった課題に対応することが可能です。
なお、ベクトルデータベースの代表的な事例としては以下の3つが挙げられます。
- 類似画像検索:ベクトルデータベースは、画像をベクトルに変換し、類似画像を検索するのに使用されます。例えば、ユーザーがアップロードした画像に似た画像をデータベースから見つけることができます。
- レコメンドシステム:商品やコンテンツの推薦システムでは、ユーザーの過去の行動や好みを基にしたアイテムのベクトルを生成し、それに基づいて個人に合わせた推薦を行います。ユーザーの興味に最も近いアイテムを見つけ出すのに役立ちます。
- 自然言語処理:ベクトルデータベースは、テキストデータをベクトル化し、そのベクトルを用いて文書の類似性を判断する自然言語処理アプリケーションに使用されます。例えば、類似するトピックや内容を持つ文書を検索する際に有効です。
身近にある検索機能や、AIのシステムとして活用されていることがわかりますね。
ベクトルデータベースの作り方
ベクトルデータベースを作るには、文章や音声などの生データが必要です。まず、Word2vecなどを用いて生データからベクトルを作成します。
ベクトルは単語ではなく数字の羅列になるので、機械が理解しやすいのがメリットです。次に、ベクトルをデータベースに格納します。そうすると、類似性検索を容易にするベクトルデータベースを作れるのです。
従来のデータベースだと生データをそのまま格納しています。そのため、データベースから生データを取り出してベクトルに変換する必要があるので厄介です。
しかし、ベクトルデータベースの場合はベクトルがあらかじめ格納されているので簡単に類似しているデータをすぐに検索できます。
なお、生成AIを使った開発環境と手法を詳しく知りたい方は、以下の記事をご覧ください。

ベクトルデータベースはどこがおすすめ?代表的なサービス4選
ここでは、ベクトルデータベースの代表的なサービスを、4つほどご紹介します。ここでご紹介するサービスは以下の通り。
- Pinecone
- Weaviate
- Chroma
- Oracle
これらのサービスの特徴を、以下の表にまとめました。
| サービス | 開発元 | 特徴 |
|---|---|---|
| Pinecone | Pinecone社 | 数十億のベクトルを10msで検索可能なほどの、処理精度の高さ |
| Weaviate | Weaviate社 | オープンソースの検索エンジンで、自分でホストすることが可能 |
| Chroma | Chroma社 | angChainやLlamaIndexとの連携が可能。オンラインメモリでも可能 |
| Oracle | Oracle社 | 企業システムの様々なニーズを満たす拡張機能を所持 |
ちなみに、他の記事ではElasticsearchやgensim、Faiss、Annoyがベクトルデータベースだと紹介している記事がありますが、これは間違っています。
- Elasticsearchは、オープンソースの全文検索エンジン
- gensimは、自然言語処理のためのオープンソースライブラリ
- Faissは、近似最近傍探索ライブラリ
- Annoyは、近似最近傍探索ライブラリ
ベクトルデータベースは、高次元データをベクトルとして扱う「データベース」なので、上記のサービスは該当しません。
くれぐれも間違えないよう、注意してくださいね!
それぞれのサービスについて詳しく解説していきます。
Pinecone
Pineconeは、数十億ものデータを扱うことができ、高速なクエリ処理を実現するベクトルデータベースです。シンプルなAPIを備えているため、使いやすさがメリットの1つです。
Pineconeのキーコンセプトは以下の通りです。
| キーコンセプト | 詳細 |
|---|---|
| ベクトル検索 | 類似ベクトルの高速検索 |
| ベクトル埋め込み | ベクトルの意味的類似性を表した情報 |
| ベクトルデータベース | 効率的なデータ管理と検索のための、ベクトル化と保存を実現するデータベース |
まず、Pineconeの公式ページに移動しましょう。そして、「Sign Up for Free」をクリックして登録します。
Pineconeを利用するためにはAPIキーが必要なので、登録が完了したら、左サイドバーから「API Keys」へと進んでください。
すると、以下のように「Environment」と「Value(API Key)」があります。2つともひかえておきましょう。

PineconeのHybrid Searchとは?
Pineconeでは、基本的なキーワード検索に加えて、セマンティック検索を行えます。セマンティック検索とは、文字よりもその意味を解釈して検索する機能です。
この「基本的なキーワード検索」と「セマンティック検索」を組み合わせたのが「Hybrid Search」です。文の意味の類似性を図る手法は、下記の種類があります。。
- TF-IDF
- BM25
- word2vec/doc2vec
- BERT
- USE
より詳細な内容は、Pineconeの公式ページに記事があるので、気になる方はぜひ読んでみてください。これ以降では、PineconeのHybrid Searchを使っていこうと思います。
Pineconeを使ってみた
早速Pineconeを、以下の順で試してみます。
- Pineconeのインストールやインデックス作成
- 簡単なクエリ処理
- Hybrid Searchでクエリ処理
公式ページにGoogle Colaboratoryが用意されているので、基本的には、その通りに実行していけば試せます。
クイックスタート
ここでは、Pineconeのインストールや、簡単なクエリ処理の実装から始めてみましょう。まずは必要なパッケージのインストールです。
# パッケージのインストール !pip install pinecone-client以下のような画面が出れば、インストール完了です。
次にPineconeの初期化を行います。先ほど取得した「Environment」と「Value(API Key)」を入力しましょう。
# インデックスの生成 pinecone.create_index( "quickstart", dimension=8, metric="euclidean", pod_type="p1" )次に、インデックスを作成します。ここで設定できる引数の詳細は、以下の通りです。
| 引数 | 意味 | 詳細 |
|---|---|---|
| dimension | ベクトルの次元 | 整数を入力 |
| metric | 類似度の指標 | euclidean: ユークリッド距離cosine: コサイン類似度dotproduct: ドット積 |
| pod_type | コストタイプ | s1: 低コストp1: 適度なコストp2: 高コスト |
また、一番上にインデックスの名前を付けましょう。ここでは「quickstart」と名付けています。
# インデックスの生成 pinecone.create_index( "quickstart", dimension=8, metric="euclidean", pod_type="p1" )無料版ではインデックスは1つしか作れません。ちなみに、以下のコードを実行すれば、作ったインデックス名を全て参照できます。
# インデックスのリストを取得 pinecone.list_indexes()また、Pineconeのマイページでも、インデックスが作成されたことを確認できます。

次に、クエリ処理をするために、作ったインデックスに接続します。
# インデックスに接続 index = pinecone.Index("quickstart")次に、データベースにデータを挿入しましょう。ここでは「A」~「E」までが各データの名前で、[0.1, ~ , 0.1]などは、8次元のベクトルを表します。
# データの挿入 index.upsert([ ("A", [0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1]), ("B", [0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2]), ("C", [0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3]), ("D", [0.4, 0.4, 0.4, 0.4, 0.4, 0.4, 0.4, 0.4]), ("E", [0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5]) ])ちなみに、このベクトルの部分は本来自分で入力するのではなく、深層学習技術などを用いて生データから変換したベクトルを入力してください。例えば、単語のデータベースを作りたい場合、Word2Vecなどで単語をベクトル化します。3次元のベクトルにする場合、以下のように入力することになるでしょう。
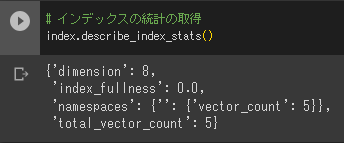
# データの挿入 index.upsert([ ("りんご", [0.3, 0.1, 0.2]), ("ごりら", [1.2, 1.2, 1.2]), ("ラッパ", [0.3, 3.3, 2.3]), ("パセリ", [1.4, 0.8, 0.4]), ("リング", [5.5, 10.5, 3.5]) ])この場合、単語とベクトルのセットになります。インデックスの統計情報を参照したい場合は、以下のコードを実行してください。
# インデックスの統計の取得 index.describe_index_stats()以下のように表示されるはずです。
そして、いよいよクエリ検索です。適当なベクトルを入力して、データベースに対して検索をかけてみましょう。
下記のコードの「vector」の部分が、検索にかけるベクトルです。このベクトルに近い「データベース内のベクトル」の情報を何個か表示してくれます。何個表示するかは「top_k」で決めます。
# 類似のベクトルの取得 index.query( vector=[0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3], top_k=3, include_values=True )以下のように返ってきました。
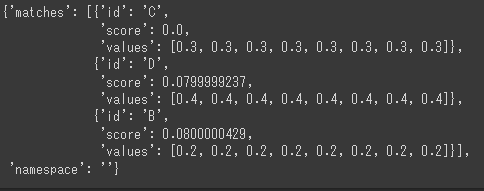
ここでは、ベクトル[0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3]に対して、ベクトルC, D, Bが返ってきました。「score」はユークリッド距離を表します。
「距離が小さい=似ている」なので、「scoreが小さい=似ている」です。そのため、ベクトルCはまったく同じデータであることが分かります。
また、ベクトルD, Bともある程度似ています。最後に、インデックスを削除したい場合は、以下のコードを実行してください。また、「quickstart」のところには、消したいインデックスの名前を入れてください。
# インデックスの削除 pinecone.delete_index("quickstart")次の実装のために、削除しておきましょう。ここまでの方法は、一般的な使い方でした。
次に、Hybrid Searchという方法で、クエリ処理をする方法を見ていきましょう。
Hybrid Searchでクエリ処理
ここでは、文章データをデータベースに格納し、Hybrid Searchを使って文章に対するクエリ処理を行っていきます。まずは、サンプルデータとして以下の10個の文章を用意しましょう。
all_sentences = [ "purple is the best city in the forest", "No way chimps go bananas for snacks!", "it is not often you find soggy bananas on the street", "green should have smelled more tranquil but somehow it just tasted rotten", "joyce enjoyed eating pancakes with ketchup", "throwing bananas on to the street is not art", "as the asteroid hurtled toward earth becky was upset her dentist appointment had been canceled", "I'm getting way too old. I don't even buy green bananas anymore.", "to get your way you must not bombard the road with yellow fruit", "Time flies like an arrow; fruit flies like a banana" ]次に、「Sentence Transformers」というライブラリをインストールします。このライブラリを使うことで、文章の意味を表す「意味ベクトル」への変換が可能です。
# Sentence Transformersのインストール !pip install sentence_transformersインストールできたら、先ほどのサンプルデータを、実際に「意味ベクトル」に変換します。
from sentence_transformers import SentenceTransformer model = SentenceTransformer('flax-sentence-embeddings/all_datasets_v3_mpnet-base') all_embeddings = model.encode(all_sentences) all_embeddings.shape最終行の「all_embeddings.shape」の出力結果から、all_sentencesは埋め込みが10、次元は768ということが分かりました。この情報は、後のインデックス作成時に、ベクトルの次元を決めるために使います。
続いて、HuggingFaceのライブラリ「transfo-xl-wt103」を用いて、サンプルデータ文をトークン化します。まずは、以下のインストールを実行してください。
!pip install sacremosesインストールが完了したら、一度ランタイムを再起動しましょう。その後、もう一度これまでのセルを実行してください。
次に、以下のコードを実行して、トークン化を行います。
from transformers import AutoTokenizer # transfo-xl tokenizer uses word-level encodings tokenizer = AutoTokenizer.from_pretrained('transfo-xl-wt103') all_tokens = [tokenizer.tokenize(sentence.lower()) for sentence in all_sentences] all_tokens[0]これを実行すると、サンプルデータの1文目の以下の文、
"purple is the best city in the forest"が、次のように単語に区切られるのです。
['purple', 'is', 'the', 'best', 'city', 'in', 'the', 'forest']これは「基本的なキーワード検索」に必要なので、このようにトークン化します。ここまで来たら、次にインデックス作成です。
import pinecone pinecone.init(api_key="<Pinecone_APIキー>", environment="<Pinecone Environment>") pinecone.list_indexes() # check if keyword-search index already exists pinecone.create_index(name='keyword-search', dimension=all_embeddings.shape[1]) index = pinecone.Index('keyword-search')次に、作成したIndexに対して、先ほど作成した以下の2つのデータをDBに格納します。
- all_embeddings
- all_tokens
upserts = [] for i, (embedding, tokens) in enumerate(zip(all_embeddings, all_tokens)): upserts.append((str(i), embedding.tolist(), {'tokens': tokens})) # then we upsert index.upsert(vectors=upserts)格納が完了したので、さっそくクエリ処理をしていきましょう。まずはセマンティック検索単体で試してみます。
以下の文章をクエリ文として引数に渡し、この文と「意味的に類似した文章」の上位5文を表示させます。
“there is an art to getting your way and throwing bananas on to the street is not it”
以下のコードを実行してください。
query_sentence = "there is an art to getting your way and throwing bananas on to the street is not it" xq = model.encode([query_sentence]).tolist() result = index.query(xq, top_k=5, includeMetadata=True) result結果は以下の通り。意味的に似ている文が、高い順に5つ並んでいます。
{'matches': [{'id': '5', 'metadata': {'tokens': ['throwing', 'bananas', 'on', 'to', 'the', 'street', 'is', 'not', 'art']}, 'score': 0.732851684, 'values': []}, {'id': '8', 'metadata': {'tokens': ['to', 'get', 'your', 'way', 'you', 'must', 'not', 'bombard', 'the', 'road', 'with', 'yellow', 'fruit']}, 'score': 0.57442683, 'values': []}, {'id': '2', 'metadata': {'tokens': ['it', 'is', 'not', 'often', 'you', 'find', 'soggy', 'bananas', 'on', 'the', 'street']}, 'score': 0.500876725, 'values': []}, {'id': '1', 'metadata': {'tokens': ['no', 'way', 'chimps', 'go', 'bananas', 'for', 'snacks', '!']}, 'score': 0.376693577, 'values': []}, {'id': '9', 'metadata': {'tokens': ['time', 'flies', 'like', 'an', 'arrow', ';', 'fruit', 'flies', 'like', 'a', 'banana']}, 'score': 0.338697404, 'values': []}], 'namespace': ''}
次に、キーワード検索も絡めた「Hybrid Search」を実行してみます。クエリを実行する際に「bananas」というトークンが含まれているデータのみを検索するように指定します。要は以下の条件のもと、フィルタリングをかけているのと同じです。
- “there is an art to getting your way and throwing bananas on to the street is not it”という文章と意味的に似ている
- 「bananas」というトークンが含まれている
result = index.query(xq, top_k=10, filter={'tokens': 'bananas'}) for i in result['matches']: print(all_sentences[int(i["id"])])結果、4行がヒットしました。
throwing bananas on to the street is not art it is not often you find soggy bananas on the street No way chimps go bananas for snacks! I’m getting way too old. I don’t even buy green bananas anymore.
所感ですが、データをベクトルとして保管し、ベクトルとしてすぐに取り出せるのは便利だなと思いました。自然言語処理の解析をする際にも、単語や文章はベクトルで扱います。
非構造されたデータを、生データのまま保管して取り出しベクトル化するのではなく、ベクトル化された状態で取り出せるので、スムーズに自然言語の分析が行えそうです。
Weaviate
Weaviateは、 Weaviate社が提供しているオープンソースのベクトルデータベースです。MLモデルをモジュールとして組み込むことで、データベースの内部でオブジェクトのベクトル化ができる仕組みを採用しています。
また、さまざまなモジュールが用意されており、拡張性が高いのもポイント。ベクトル化やバックアップもオプションのモジュールによって実現できます。
Chroma
Chromaは、AIアプリケーション開発のために設計されたオープンソースのベクトルデータベースです。自然言語をベクトル表現で格納できるほか、高精度かつ高速な類似性検索を実現するベクトル検索ができます。
なお、PythonやJavaScriptでAIアプリケーションを構築できるだけでなく、簡単なAPI統合も可能。オープンソースのため、誰でも無料で利用できるのが魅力です。
Oracle
Oracle社が提供しているOracle Databaseは、堅牢性と機能の豊富さが魅力のサービスです。リレーショナルデータベースとして有名な同サービスですが、ベクトルデータベースを活用した検索機能「Oracle AI Vector Search」も提供しています。
Oracle AI Vector Searchを使用すれば、検索した値の意味や意義に基づいて、構造化データと非構造化データをそれぞれ検索できるのが特徴。大規模言語モデル(LLM)なら、検索拡張生成(RAG)を使用して高精度な回答結果を提供できるようになるのが魅力です。
ベクトルデータベース導入時の注意点
ベクトルデータベース導入時は、以下3点に注意する必要があります。
- データの前処理が必要
- システム設計時はスケーラビリティや処理能力を考慮する
- パフォーマンスの最適化が必要
以下でそれぞれ解説するので、ベクトルデータベース導入前に確認しておいてください。
データの前処理が必要
ベクトルデータベースを効果的に活用するには、事前のデータ処理が不可欠です。ベクトル化の前に、データのクリーニングや正規化を実施することで、検索の精度を向上できます。
例えば、テキストデータは不要な単語の除去や単語の形の統一をすると、より意味のあるベクトル表現を作成できます。
また、ベクトルの次元数も考慮すべき要素です。次元が多すぎると計算コストが増大し、逆に少なすぎると十分な情報を保持できない可能性があります。そのため、次元削減技術を活用して適切なバランスを見つけることが重要です。
システム設計時はスケーラビリティや処理能力を考慮する
ベクトルデータベースをシステムに組み込む際には、データ量の増加に対応できる設計が求められます。とくに、大規模なデータセットを扱う場合、データの分散管理やクエリ処理の負荷分散を適切に行うことが重要です。
また、リアルタイム検索が求められる環境では、インデックスの更新頻度や検索遅延の最小化にも注意を払う必要があります。バッチ処理とリアルタイム処理を組み合わせることで、システム全体の効率を最適化できます。
パフォーマンスの最適化が必要
データ量や検索頻度に応じたパフォーマンスチューニングも欠かせません。例えば、頻繁に使用される検索結果をキャッシュすることで、応答時間を短縮できます。
また、インデックスのパラメータ(クラスタ数やツリーの深さなど)を適切に調整することで、検索精度と処理速度のバランスを最適化できます。
さらに、大規模データの検索や更新を高速化するために、GPUを活用する方法もあります。ただし、GPUの導入にはコストがかかるほか、システム管理が複雑になる可能性があるため、事前に十分な検討が必要です。
ベクトルデータベースの課題と将来性
最後に、ベクトルデータベースが抱える主要な課題と将来性について説明します。
ベクトルデータベースが抱える課題
- スケーラビリティの問題:大量のデータや高次元ベクトルを効率的に管理し、処理することは技術的に困難です。これは、特にビッグデータを取り扱う環境でのスケーラビリティに影響を与えます。
- 複雑なクエリ処理:ベクトルデータベースは、類似性検索に特化しているため、従来のリレーショナルデータベースのような複雑なクエリ処理や集計機能には制限があります。
- 専門知識の必要性:ベクトルデータベースの運用や最適化には、専門的な知識や技術が必要です。これにより、一部の組織では導入や管理が難しい場合もあります。
ベクトルデータベースは、高次元データの類似性検索に優れた強力なツールですが、上記のような課題も抱えています。導入を検討する際は、システムの要件やデータの特性を踏まえ、適切な設計と運用方針を策定することが重要です。
ベクトルデータベースの将来性
- AIと機械学習の進化に伴う需要増:AIと機械学習の分野が進化するにつれて、非構造化データや高次元データの処理がより重要になります。ベクトルデータベースは、これらのデータを効率的に扱うことができるため、需要が高まると予想されます。
- 新しい技術の統合:進化する技術との統合により、ベクトルデータベースの性能や機能が向上する可能性は高いです。これには、クラウドコンピューティング、分散処理、AIの最適化技術などが含まれます。
- 多様な応用分野への適用:類似性検索やパターン認識などの機能は、医療、金融、リテール、エンターテイメントなど多岐にわたる分野で応用される可能性があります。
ベクトルデータベースは、AI社会における重要なデータ管理ツールとしての地位を確立しつつあり、今後の技術進化によりその役割と影響力はさらに増すことが予想されます。
理解を深め、しっかりと活用していきたいですね。
なお、AIエージェントの開発方法が知りたい方は、以下の記事をご覧ください。

ベクトルデータベースでデータを保管しよう!
ベクトルデータベースは、高次元データをベクトルとして扱うデータベースのことです。
従来のデータベースで類似データの検索を行う場合は、
- インデックス
- クラスタリング
- カーネル法
などの手法によって、実現していました。
これらは、データの検索や処理が制限される場合がありましたが、ベクトルデータベースにより、高速に処理することが可能になりました。なお、PineconeやWeaviateのように、オープンソースで使える無料のベクトルデータベースも提供されています。アプリケーション開発などでデータの処理速度を向上させたい方は、ぜひ利用してみてください。
最後に
いかがだったでしょうか?
ベクトルデータベースの導入により、高速な類似検索や非構造化データの活用が可能になります。貴社のデータ管理やAI活用の最適な方法を検討してみませんか?
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
 ︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。
︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。
「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。