
アメリカのコロラド大学ボルダー校(CU Boulder)で行われた最新の研究によって、近年急速に増え続けている「略奪的ジャーナル(ハゲタカジャーナル)」の問題に対し、AI(人工知能)を使った新しい解決方法が示されました。
「略奪的ジャーナル」とは、高額な掲載料を要求する一方で、論文の内容を専門家が十分にチェック(査読)せず、質の低い論文でも掲載してしまう学術誌のことを指します。
このような雑誌の増加は科学の信頼性を脅かす大きな問題になっていますが、人手でひとつひとつ確認する作業には限界がありました。
そこで今回、研究チームは雑誌のウェブサイトの構成や論文の引用パターンをAIに学習させ約15,000誌の中から1000誌以上もの「あやしい雑誌」を高い精度で効率的に見つけ出すことに成功したのです。
果たして、AIの活躍によって「略奪的ジャーナル」の脅威から科学を守ることができるのでしょうか?
研究内容の詳細は2025年8月27日に『Science Advances』にて発表されました。
目次
- 増え続ける「あやしい科学雑誌」にどう対応するか?
- AIはどうやって『怪しい雑誌』を見破った?
- AIの判定はどこまで信用できる?
増え続ける「あやしい科学雑誌」にどう対応するか?

インターネットが広く普及したことで、学術誌と呼ばれる専門的な研究成果の発表の場も大きく変わりました。
かつては高価な本や雑誌を手に入れないと読むことができなかった最先端の研究も、今では「オープンアクセス誌」を通じて、世界中どこにいても無料で読めるようになりました。
この「オープンアクセス」は、多くの研究者たちが「知識はみんなのもの」という理想を叶えるために進めてきた運動で、途上国や研究費が限られている環境でも最新の知見にアクセスできる点で、学術の未来に大きな希望をもたらしてきました。
ところが、この“誰でも読める”というオープンな仕組みは、科学の世界に新しい落とし穴も作りました。
実際、オープンアクセス誌が増えるのと同じスピードで、あやしい雑誌――つまり本来の目的をゆがめて、「掲載料だけを集めようとする」雑誌も急増してしまったのです。
こうした雑誌は、メールやウェブサイトなどを通じて「すぐに掲載しますよ」と研究者に近づき、時には数万円から十数万円といった高額な掲載料を請求します。
一方で、本来とても大切な「査読」(専門家が論文の内容を詳しくチェックする仕組み)は名ばかりで、形だけの簡単な確認だけで済ませてしまう例が後を絶ちません。
このような悪質な雑誌は「略奪的ジャーナル」や「ハゲタカジャーナル」と呼ばれています。
研究者の世界では「成果を出さなければ評価されない」というプレッシャーが年々高まっています。
とくに大学院生や若い研究者は、論文の発表歴がキャリアの出発点になるため、時には少しでも早く論文を“どこか”に出したいと焦ってしまうこともあります。
略奪的ジャーナルは、こうした研究者たちの弱みに巧みに付け込みます。
特に、アジアやアフリカなどの新興国では、大学や研究機関のサポートが十分でない場合も多く、経験の浅い研究者や研究費に余裕のない人たちが狙われやすいことも世界中の調査で明らかになってきました。
略奪的ジャーナルの存在は、学術の健全性を根本から揺るがす問題です。
なぜなら、質のチェックがされていない論文が増えれば増えるほど、本当に信頼できる研究成果と、そうでないものがごちゃ混ぜになってしまうからです。
たとえば、医療や気候変動など、私たちの暮らしや社会の判断に関わる分野で“質の悪い論文”が参考にされてしまえば、間違った治療法や政策が広まる危険もあります。
科学の世界で「みんなが信じる根拠」となる論文の質が保証されないまま膨れ上がってしまうと、長い時間をかけて築き上げてきた“科学の信用”そのものが崩れかねません。
こうした問題を解決するために、世界の学術界はさまざまな方法を試してきました。
たとえば、2000年代からはDOAJ(ディーオーエージェー:Directory of Open Access Journals)という国際的なボランティア組織が登場しました。
この団体は、「信頼できるオープンアクセス誌」を登録リストで公開し、その基準に合格した雑誌だけを掲載しています。
DOAJの審査は「編集委員会の顔ぶれや連絡先がきちんと明記されているか」「論文の査読方法や倫理方針が公開されているか」といった明確なチェックリストに基づいています。
しかし実際には、このような審査を人力だけで行うのは限界があり、世界中で増え続ける雑誌の動きに追いつくのは非常に困難です。
特に、巧妙に姿を変えて現れる新しい怪しい雑誌や、見かけだけは立派に作られたウェブサイトを持つ雑誌を見分けるのは至難の業です。
このような現状を受けて、今回の研究チームが注目したのが「AI(人工知能)」の活用です。
AIとは、人間のように“経験から学び、パターンを見つけて判断する”ことができるコンピューター技術のことです。
研究チームは、DOAJが採用しているチェックリストや、ウェブサイトの構造、論文の引用パターンなど多様な特徴をAIに覚えさせ、雑誌ごとの「あやしさ」の兆候を自動で分析できるシステムを目指しました。
ある意味でAIは雑誌の性格を学ぶことで「あやしさ」を見抜くのです。
さらに、今回のAIは「なぜ怪しいと判断したのか」を人間があとから説明できるように設計されているのが大きな特徴です。
たとえば「編集委員の名前や経歴が公開されていない」「同じ著者の論文ばかりが頻繁に引用されている」「雑誌のウェブサイトの作りが他と違って不自然」といった具体的な理由を、AIがピックアップして説明できるようになっています。
これによって、ただ単に結果だけが“ブラックボックス”のように出てくるAIではなく、人間の専門家が後からしっかり根拠をたどれる透明性の高い仕組みになりました。
従来はモグラ叩きのように個別対応しかできなかった雑誌のチェック作業も、AIの力を借りることで世界中の雑誌を一気にふるいにかけ、怪しいものを効率よくリストアップすることが可能になります。
AIはどうやって『怪しい雑誌』を見破った?
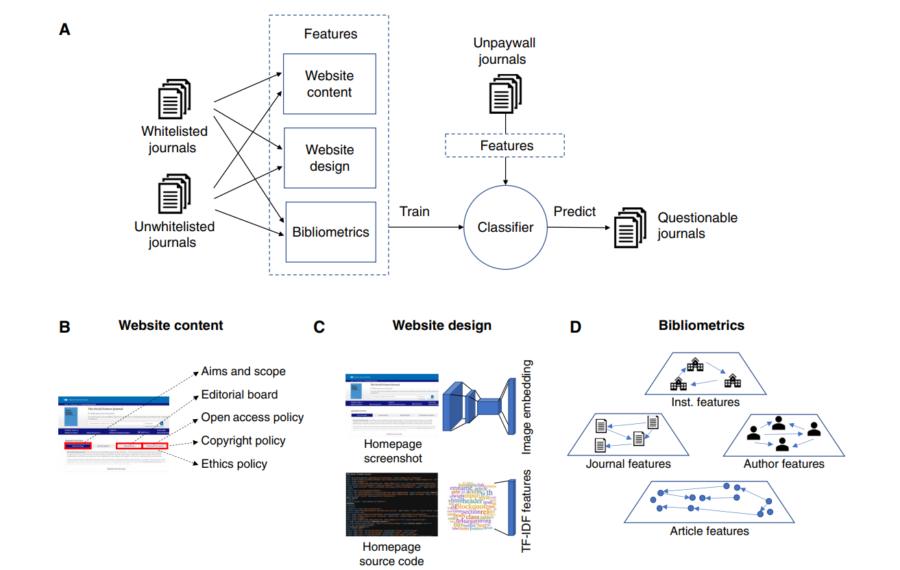
では、今回のAI(人工知能)は、どのようにして「あやしい雑誌」を見分けたのでしょうか。
まず最初に、AIが雑誌の「あやしさ」を判断するために、2つのタイプの雑誌データを用意しました。
1つは、しっかりした基準でチェックされ、品質が保証されている「信頼できる雑誌」のリストです。
もう1つは、以前は信頼されていたものの、品質の問題があったためリストから外された「疑わしい雑誌」です。
ここで重要なのは、「疑わしい雑誌」といっても、リストから除外された理由には必ずしも悪意や悪質性があるわけではないという点です。
雑誌が休刊になったり、自主的にリストから削除を依頼した場合などもありますが、それらもすべて「疑わしい雑誌」として分類されることに注意が必要です。
AIはこれら2種類の雑誌データを学習し、それぞれの雑誌がどんな特徴を持っているのかを分析しました。
具体的には、雑誌のウェブサイト上に掲載されている「編集方針」や「編集委員リスト」、「倫理規定」などの情報や、そのサイトの文章の読みやすさ(可読性:文章がわかりやすく、誤解なく読めること)を調べました。
また、サイトのデザインや構造、例えばトップページのレイアウトやウェブページを作るためのコード(HTML)のパターンなども分析対象になりました。
さらに、AIは雑誌に掲載される論文の引用パターンにも注目しました。
論文というのは、過去の研究を引用し、その上に自分の新しい研究結果を積み上げる仕組みになっています。
質の高い雑誌では、幅広くいろいろな論文を引用していますが、疑わしい雑誌では、自分たちの過去の論文ばかりを引用し、他の研究者の論文をあまり引用しない傾向があります(自己引用と言います)。
AIは、このような引用パターンも「あやしさ」の重要な手がかりとして学習しました。
こうした様々な特徴をAIに学習させ、どのような特徴が「疑わしい雑誌」に多く見られるかを教え込んでいきます。
AIが完成すると研究者たちは、実際にインターネット上で公開されている15,191の雑誌を調べてもらいました。
ここで重要となったのは2つの指標です。
1つ目の指標が「適中率(precision)」で、これはAIが「あやしい」と判断した雑誌の中で実際に本当に怪しかった割合で、高ければ高いほど優秀となります。
もう1つが「再現率(recall)」で、これはAIが本当に存在する「あやしい雑誌」全体のうち、どのくらい見逃さずに発見できたかを表し、こちらも高いほど優秀(見逃しが少ない)です。
しきい値(どのくらい厳しく判定するかの基準、あやしさへの敏感さとも言える)をちょうど中間の50%に設定した場合、AIは15,191誌のうち1,437誌を「あやしい」と判定しました。
その後、人間によってチェックを行ったところ、AIの適中率は約76%であることが判明しました。
これは「AIがあやしいと指摘した雑誌のうち、およそ4分の3にあたり1000誌以上が実際に怪しい可能性が高い」ということを示しています。
一方で再現率は約38%で、これは「実際にあやしい雑誌の4割弱をみつけられたものの、約6割を見逃している」ということを示しています。
ここで「じゃあ、もっと厳しくしたらいいのでは?」と思うかもしれませんが、そう単純ではありませんでした。
判定をゆるくして広く拾う設定にすると、無害な雑誌まで間違って疑われる確率(誤判定)が増えてしまい、チェックする人間の負担が大きくなってしまいます。
逆にしきい値を高くして本当に怪しいものだけを報告するように設定すると、報告数が減って人間の負担も減り、高精度であやしい雑誌を指定してきますが、問題のある雑誌をたくさん見逃してしまうことがわかりました。
このような、適中率と再現率の関係を「トレードオフ」(どちらかを良くするともう一方が悪くなる関係)と呼びます。
そのため研究者たちは目的にあわせて厳しさを変更する方法を提案しています。
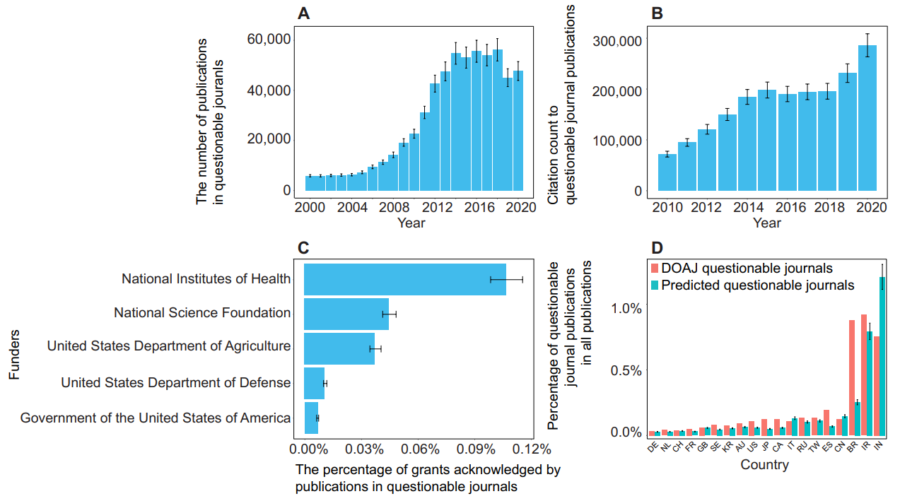
さらに、このAIによって「あやしい」と判断された雑誌を細かく調べてみると、興味深い特徴が見えてきました。
これらの雑誌では、掲載される論文の数は全体的に年々増えていましたが、2019年から2020年にかけて一時的に少し減少しました。
しかし、他の論文に引用される数(被引用数)は逆に増えており、疑わしいとされた雑誌でも論文が多く出回っていることが明らかになりました。
また、これらの雑誌に掲載された論文では、自分たちの過去の論文を頻繁に引用する「自己引用」の割合が高く、他の研究者が書いた論文の引用が少ないことも特徴でした。
さらに、その論文を書いている研究者自身も、信頼されている雑誌に掲載されている研究者に比べて平均的に業績や経験が少ない傾向がありました。
このようにして、AIは雑誌のウェブサイトの見た目だけでなく、論文の引用パターンや著者の経歴まで含めて詳しく分析することで、「疑わしい雑誌」を見分ける新しい方法を生み出したのです。
AIの判定はどこまで信用できる?
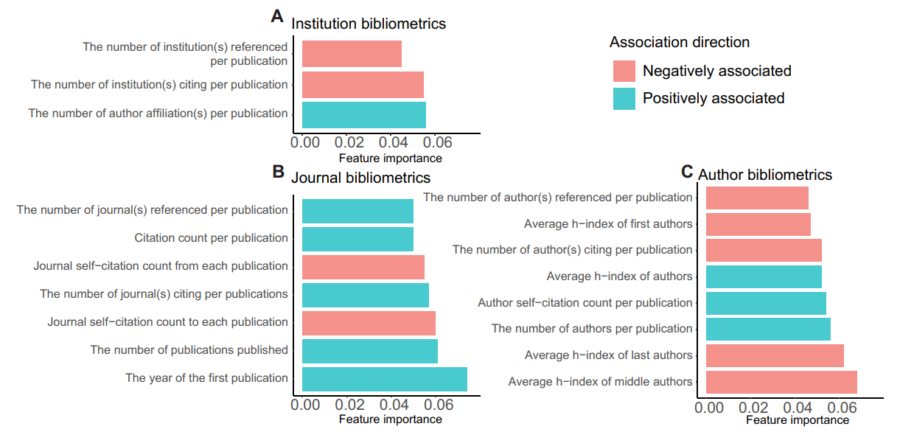
ここまで、AI(人工知能)を使って疑わしい学術雑誌を見つけ出す研究について説明してきましたが、「AIの判定は本当に信頼できるの?」という疑問が湧いてくるかもしれません。
実際にAIが「あやしい」と判定した雑誌を詳しく調べると、必ずしも悪意があるとは言えない雑誌も含まれていました。
例えば、ウェブサイトが一時的に停止したり、雑誌の発行が休止しているなど、単に運営上の問題で「あやしい」と判断されてしまった雑誌もあります。
また、本来は雑誌ではない書籍のシリーズや、学術会議の発表資料(会議録)などが誤って雑誌として扱われ、「怪しい雑誌」として判定されるケースもありました。
さらに、小さな学会が真面目に運営している雑誌でも、ウェブサイトが簡素だったり、あまり目立たないだけで、誤って疑われてしまった例もありました。
こうした状況を見ると、AIの判定結果をそのまま完全に信じることには問題があると言えます。
一方で、AIは「実際にあやしい雑誌」を見逃してしまうこともあります。
AIが正しく見抜ける割合は完全ではなく、実際に存在する怪しい雑誌のうち、6割近くを見逃していることが分かりました。
つまり、このAIは万能の道具ではなく、雑誌のチェックを始めるための最初の段階(一次ふるい)として考えるべきです。
研究チーム自身も、最終的に雑誌が本当に問題かどうかを判断するのは、人間の専門家(例えば雑誌の編集者や、研究費を出す機関など)の仕事だと強調しています。
実際に、このAIが「あやしい」と判断した雑誌を人間の専門家がランダムに取り出して確認してみたところ、AIが指摘した雑誌のうち約4分の1は問題がないと判明しました。
しかし、それ以外の約4分の3はやはり「あやしい雑誌」であることが分かり、AIの判定と人間の専門家の意見がほぼ一致したのです。
この結果は、AIが一定の精度で「あやしい雑誌」を見つける能力を持っていることを示していますが、同時に、AIの判定だけに頼るのではなく、専門家が必ず確認を行う必要があることも明らかにしています。
ここまで説明してきたように、このAIはまだ完璧ではありません。
しかし、人間がすべての雑誌を一つ一つ確認して「あやしいかどうか」を判断するのは、現実的に不可能です。
世界中には膨大な数の学術雑誌があり、それらを人の手だけでチェックするのは時間と労力がかかりすぎます。
そのため、AIを活用することで、多くの雑誌の中から「あやしいかもしれない雑誌」をある程度の正確さで素早く見つけ出し、その後に専門家がじっくりと検討すればよいのです。
AIが雑誌のチェック作業を最初に引き受けることで、限られた人間の専門家が本当に精査すべき重要な雑誌に力を注ぐことができるようになります。
今回の研究チームは、このAIを「科学の防火壁(ファイアウォール)」と表現しました。
防火壁とは、もともと建物で火災が広がるのを防ぐ壁のことで、コンピューターの世界では、外部からの危険な侵入を防ぐためのシステムのことを指します。
つまり、このAIは怪しい雑誌が科学界に入り込んで信頼性を壊してしまうのを防ぐ、最初の防御ラインとして機能するというわけです。
研究チームは、大学や出版社がこのAIを手軽に利用できるようにすることを検討しており、このシステムが普及すれば、怪しい雑誌による科学への被害を防ぐことが期待されます。
もちろん、それはあくまで専門家が最後のチェックを行うという前提のもとですが、AIを上手に使うことで、科学の信頼性を守る新しい仕組みが生まれることになるでしょう。
元論文
Estimating the predictability of questionable open-access journals
https://doi.org/10.1126/sciadv.adt2792
ライター
川勝康弘: ナゾロジー副編集長。 大学で研究生活を送ること10年と少し。 小説家としての活動履歴あり。 専門は生物学ですが、量子力学・社会学・医学・薬学なども担当します。 日々の記事作成は可能な限り、一次資料たる論文を元にするよう心がけています。 夢は最新科学をまとめて小学生用に本にすること。
編集者
ナゾロジー 編集部

