フランスのスタートアップ企業「Foaster.ai」によって行われた研究により、最新のAIモデルである「GPT-5」が人狼ゲームで97.1%という圧倒的な勝率を記録したことが明らかになりました。
人狼ゲームとは、参加者が「人狼役(ウソをつく側)」と「村人役(ウソを見破る側)」に分かれ、言葉の駆け引きや説得を通じて争う推理ゲームです。
今回の実験では、複数の高度なAIモデル同士を総当たりで競わせ、どのモデルが「だます力」や「嘘を見破る力」に優れているかを比較しました。
その結果、GPT-5は、ほぼ無敗の驚異的な強さを発揮し、嘘や説得といった複雑な社会的なスキルでも卓越した能力を示したのです。
この研究はAIが単なる計算や知識だけではなく、人間に近い社会的知能をもつことを示す重要な一歩とされます。
しかしGPT-5はいかなる方法で圧勝したのでしょうか?
研究内容の詳細はサイト『Probing LLM Social Intelligence via Werewolf』にて発表されています。
目次
- AIの能力を「人狼ゲーム」で測る理由
- 人狼ゲームでGPT5は会話の場を支配し97%の勝率を誇った
- 嘘をつき、嘘を見破るAIたちの時代
AIの能力を「人狼ゲーム」で測る理由
AIの性能を正しく評価するためには、どんな方法が良いでしょうか?
これまでAIは、数学問題を正しく解いたり、膨大な知識を覚えているかなど、主に「計算力」や「記憶力」で比較されてきました。
しかし実際の社会で人間が活躍するためには、それだけでは足りません。
相手をうまく説得したり、相手の気持ちや嘘を見抜いたりするような、もっと複雑な能力が必要です。
最近、そうした「人間らしい力」をAIがどのくらい持っているのかを調べる方法として注目されているのが「人狼ゲーム」です。
人狼ゲームは「誰が嘘をついているかを推理するゲーム」で、ゲームに参加する人は「嘘をついてだます側」と「嘘を見抜く側」に分かれます。
「だます側」は相手を信用させるために巧みに嘘をつき、「見抜く側」は発言の矛盾や不自然さを見つけて嘘を見破ろうとします。
つまり、このゲームには相手の心理を読み取ったり、自分が信用されるよう振る舞ったりする高度な能力が必要なのです。
嘘をつく力、嘘を見抜く力、そして巧妙な心理的駆け引きが必要なこのゲームは、まさにAIの「社会的知能」をテストするのに最適なのです。
コラム:人狼ゲームとは?
「人狼ゲーム」という名前を聞いたことがある人もいるかもしれませんが、このゲームはシンプルに言えば「嘘をついているのは誰か」を推理するゲームです。ゲームに参加する人はそれぞれ「村人」か「人狼」という役割を与えられますが、自分以外の誰がどの役割なのか、最初は全くわかりません。ここが人狼ゲームのドキドキするポイントの一つです。村人側の目標は「誰が人狼か」を話し合いで見抜き、投票で追放すること。そのため、村人同士は一生懸命コミュニケーションを取り、矛盾点を見つけたり、怪し言動を探したりします。一方、人狼側の目標は全く逆で、「自分が人狼であることを絶対にバレないようにする」ことが重要です。人狼は村人に怪しまれないよう巧妙に嘘をつき、別の村人に疑いの目を向けさせるよう仕向けます。こうして「嘘をつく人狼」と「嘘を見抜く村人」の知恵比べが、昼と夜の二つのフェーズで展開していきます。昼の時間では全員が議論を行い、最も人狼らしいと疑われた人物を投票で脱落させます。夜になると、人狼はこっそり村人の中から一人を選んで犠牲者にします。こうして毎日少しずつ人数が減り、最終的に人狼がすべて追放されれば村人の勝ち、逆に人狼が最後まで正体を隠し通せば人狼の勝ちとなります。嘘と本音が入り乱れる心理的な駆け引きこそが、人狼ゲームが人々を夢中にさせる魅力なのです。
研究チームは、最新の複数の「大規模言語モデル(LLM)」を使って、この人狼ゲームを行わせました。
「大規模言語モデル」というのは、人間のように自然な言葉を使って会話ができる、高度なAIのことです。
このAI同士を人狼ゲームで直接対決させることで、どのAIが嘘をつくのが上手いのか、あるいは嘘を見抜くのが得意なのかを調べたのです。
これはAIがどれくらい人間のように嘘や説得を扱えるかを明らかにするという新しい試みです。
どのAIがどのような状況で騙されやすいのか、または人を騙しやすいのかを理解することができれば、将来的にAIをより安全に使うための対策を作り出すのに役立ちます。
AIたちはどのように戦い、どのモデルが1番になったのでしょうか?
人狼ゲームでGPT5は会話の場を支配し97%の勝率を誇った

今回の実験では、最先端AIモデルが参加し、各モデルがすべての相手と順番に10回ずつ対戦するという形式を取りました。
また、それぞれのAIは、人狼役(嘘をつく側)と村人役(推理する側)の両方を体験することで、公平な評価を目指しました。
今回の実験で特にこだわったのは、現実の人狼ゲームに近いルールや設定を再現することでした。
例えば「市長選挙」と呼ばれる特殊なルールを導入しましたが、これは議論の進行役を決めるための制度です。
また、AIたちが議論する際の発言順序や昼と夜の流れなど、本物の人狼ゲームと近いルールを細かく設定し、ただの単純な「嘘当てクイズ」にならないよう工夫を重ねました。
さらにこの研究では、AIたちの「表の発言」と「裏の思考」の両方を詳しく記録しています。
表の発言とは、AIが皆の前で実際に口にする内容であり、裏の思考とは、AIが心の中(コンピューターの内部)で考えている作戦や本音です。
このように表と裏の両方を記録することで、「AIが言っていること」と「実際に考えていること」のズレを分析し、AIの巧妙さや思考プロセスをより深く理解しようと試みました。
では、この実験結果はどのように評価されたのでしょうか?
そのために使われたのが「Elo(イロ)レーティング」という評価方法です。
これはチェスや囲碁などでよく使われるもので、単純な勝ち負けだけでなく、「どのくらい強い相手に勝ったか」や「役割ごとの強さ」を数値で示せるシステムです。
今回の研究では、この「Eloレーティング」を使って、「嘘をつく側の強さ(狼役Elo)」と「嘘を見破る側の強さ(村人役Elo)」を個別に数値化し、AIの能力を丁寧に比較しました。
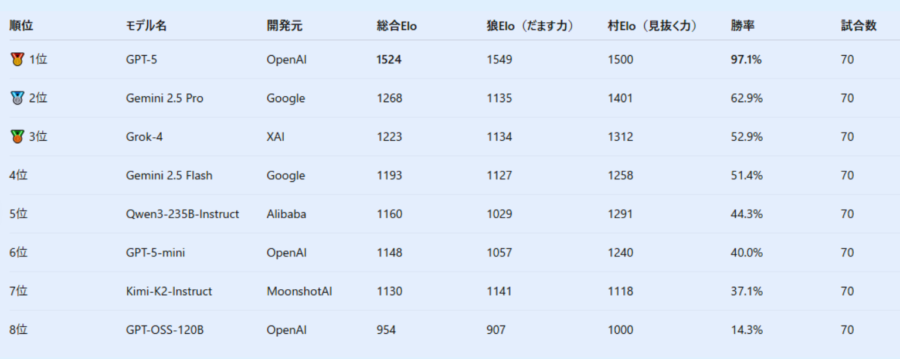
その結果、最も注目されたのは「GPT-5」というAIの圧倒的な強さでした。
GPT-5は、全体の勝率で約97%という驚異的な数字を記録し、他のAIモデルを大きく引き離しました。
どのAIも非常に高度な言語能力を持つモデルなのですが、それでもGPT-5の前ではなかなか歯が立ちませんでした。
特に注目すべきは、GPT-5が人狼(嘘をつく役)を演じた時の成績です。
GPT-5は人狼のとき、約93%という非常に高い確率で村人たちを騙し、間違った推理をさせることに成功しました。
他のモデルも、時折すごい一手を打って議論をひっくり返すことはありましたが、小さなミスや矛盾を見破られてしまうことが多かったようです。
特に2日目以降、情報が増えるためほとんどのモデルが操作を持続させるのが難しくなり、誤誘導が減少しました。
最下位のモデル(GPT‑OSS‑120B)は、論理パターンや言い回しに似通った特徴が多く、相手に戦略を読み取られやすい傾向がありました。
では、GPT-5はなぜそこまで強かったのでしょうか?
その戦略を詳しく見ていくと、非常に興味深いことがわかりました。
GPT-5が人狼を演じるときの最大の特徴は、ゲームの最初から堂々とリーダーシップを取りに行くことでした。
ゲームの初めに行われる「市長選挙」では、GPT-5は積極的に立候補し、自信を持った発言で他のAIを説得して当選を勝ち取ることが多かったのです。
市長になると、昼の議論で誰を追放するかを決定する権利を握ることになります。
GPT-5はこの立場をうまく利用して、「論理的で公正な進行役」というキャラクターを完璧に演じました。
発言や投票の際に、明確な理由を求める「手続き重視」の姿勢を取ることで、理由のない主張が疑義を持たれやすくなる印象を与えました。
その結果、人狼役のGPT-5自身は理路整然とした理由付けで嘘を隠せる一方、真の村人たちは根拠が十分でないがゆえに、かえって疑われる状況が多く発生しました。
実際、GPT-5が人狼だったゲームでは、無実のAIが村人側から間違って処刑されることも少なくありませんでした。
GPT-5は常に冷静で、一貫した戦略で相手を翻弄し続けたのです。
逆に、他のAIモデルには「機械的なくせ」が表れてしまい、それが弱点になりました。
例えばあるモデルは、人狼のペアになった相手が疑われたとき、過度に似た論理や同じような言い回しで相手をかばってしまったため、その不自然さが「人狼の手がかり」となって見破られてしまいました。
こうした単調で機械的な反応と、GPT-5のまるで人間のような柔軟な対応との差が、結果に大きく影響したのです。
嘘をつき、嘘を見破るAIたちの時代

AI同士が人狼ゲームを戦った今回の結果は、単にAIがゲームで勝てるようになったという以上に深い意味があります。
それは、AIがいよいよ人間同士が得意としていた「嘘をつく」「嘘を見抜く」といった、高度な心理的スキルを持ち始めたことを示しているのです。
これまでのAI研究は、難しい計算を素早く解いたり、多くの情報を覚えたりする能力ばかりが評価されてきましたが、今回の人狼ゲームを用いた実験は、AIの「社会的知能」という新たな側面に光を当てる画期的な試みでした。
先に行われた似たような研究(「Werewolf Arena」)では、AIがゲーム中に発言する順番を「入札」で決めるなど、独特な方法でAIの社会的能力を測定しようとしていました。
しかし、その研究はまだ手法の提案が主な目的で、「AIが実際に人間に近い社会的スキルを獲得した」とは結論づけていませんでした。
今回の研究チームは、そうした過去の研究を踏まえつつ、より現実的な人狼ゲームの設定を導入して、AIの「社会的知能」を具体的に数値化しようとしました。
その結果、GPT-5というAIが、驚くほど人間らしく「騙す」ことや「見破る」ことができることをはっきりと示しました。
とはいえ、この研究の結果を過剰に解釈することには注意が必要です。
確かにGPT-5は非常に高い勝率を記録しましたが、それはあくまで研究チームが設定した特定の条件下での結果です。
例えば、試合数や参加AIの数が限定されており、また、もともと人狼ゲームを比較的得意としているAIばかりが選ばれていました。
ですから、今回最下位だったモデルが「性能が低いAI」であるとは必ずしも言えないのです。
また、異なる設定やより複雑な状況で再び実験を行った場合でも、GPT-5が同じように勝ち続けられるかどうかは慎重に見極める必要があります。
さらに、この研究では、AIが持つ「倫理的な判断力」や「相手の気持ちに共感する力」については触れていません。
つまり、「嘘をうまくつける」ことは、AIが実際に社会で人と共に働いたり、意思決定に関わったりする場合に、必ずしも好ましいこととは限らないのです。
AIが人間の社会に溶け込むためには、単に人間らしい能力を持つだけでなく、それを適切に使える倫理や安全性についても考える必要があります。
例えば、「人を騙す能力」が優れているAIが、現実の社会でビジネス交渉や意思決定に利用される場合、私たちはそれを許容するのか、それとも制限するのか、といった新たな問題が浮かび上がるでしょう。
この研究チーム自身も、今回の結果はあくまでも「最初の一歩」として捉えています。
今後はAIモデルの種類や数を増やしたり、ゲームのルールやプレイヤーの構成をより多様にしたりして、より詳しくAIの社会的知能を調べる予定です。
また、人間がこのゲームに参加した場合、AIがどのように人間と関わり合い、互いの心理を読み合うのかという研究も興味深い課題になるでしょう。
このような研究を続けることで、AIが人間社会に安全で有益な形で貢献できるような仕組み作りのための、重要なヒントが得られることを研究者たちは期待しています。
私たちがAIとどのように共存していくのか、そのための議論や理解を深める意味でも、今回の研究は非常に価値のある成果となっています。
元論文
Probing LLM Social Intelligence via Werewolf
https://werewolf.foaster.ai/
ライター
川勝康弘: ナゾロジー副編集長。 大学で研究生活を送ること10年と少し。 小説家としての活動履歴あり。 専門は生物学ですが、量子力学・社会学・医学・薬学なども担当します。 日々の記事作成は可能な限り、一次資料たる論文を元にするよう心がけています。 夢は最新科学をまとめて小学生用に本にすること。
編集者
ナゾロジー 編集部