
推論力は進化したのに、ウソまでパワーアップしてしまったようです。
2025年4月にOpenAIが発表した最新の大規模言語モデル「o3」と「o4-mini」は、これまで以上に長い“思考の連鎖”と高度なツール連携によってかつてない推論力を実現しました。
しかしその後のOpenAI社の調査によって、それら最新のAIがもっともらしく事実でない回答をしてしまう「幻覚(ハルシネーション)」の発生率が従来モデル(o1やo3-mini)より大幅に悪化していることが明らかにりました。
なぜより強力な推論能力を持つ最新モデルで、ハルシネーションが増加してしまったのでしょうか?
目次
- 巨大化の次は“思考強化”──推論エンジン誕生の舞台裏
- o3モデルは「賢く」でも「間違いが多く」進化した
- 創造性か信頼性か——AI開発者が抱えるジレンマ
巨大化の次は“思考強化”──推論エンジン誕生の舞台裏

近年、AI研究の焦点は単純にモデルを巨大化することから、「推論力」を高める方向へとシフトしています。
従来のGPT-4系モデルがマルチモーダル(テキスト・音声・画像対応)や高速化を追求してきた一方で、OpenAIのoシリーズは複雑な問題解決や論理的思考、コード生成など「考える力」を強化するために設計された系統です。
なぜ推論力の強化が目指されたのでしょうか?
背景には、大規模言語モデル(LLM)が高度な知識を持ちながらも、複数ステップにわたる推論や論理的整合性を要する場面でミスを犯しがちだったことがあります。
モデルを大きくすれば精度は上がるものの、ある段階からは「考え方」を工夫しないと得られる成果に頭打ちが見え始めたのです。
その打開策として生まれたのが、モデル自身により長く深く考えさせるアプローチです。
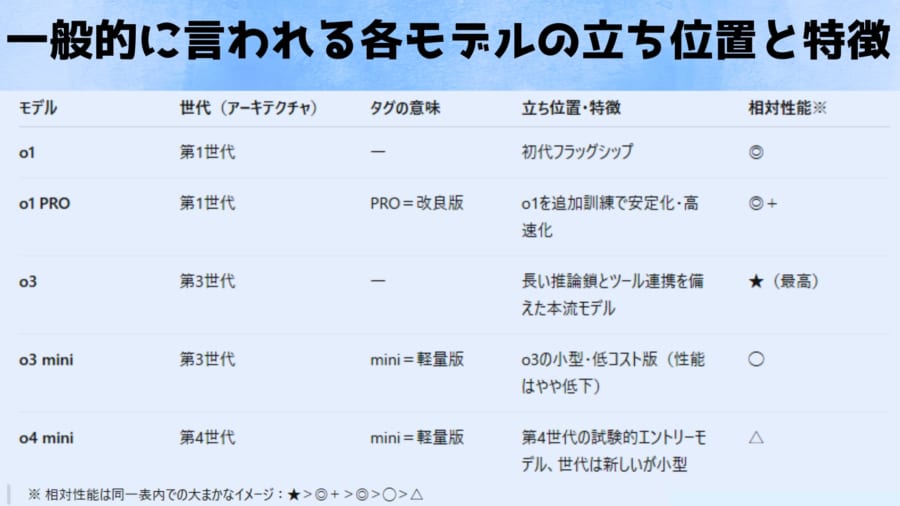
o3やo4-miniでは回答を出す前に内部で長い「思考の連鎖 (Chain of Thought)」を巡らせ、あたかも人間が頭の中で段取りを踏むように結論を導き出します。
例えば数学の難問やプログラミングのデバッグといった多面的な分析が必要な課題でも、小さなステップに分解して推論するため、より正確な解答を出せるよう設計されています。
また、この新モデルはあらゆるツールを自律的に活用できる点も画期的です。
インターネットでの情報検索、Pythonスクリプトによるデータ解析、画像生成や画像認識といったツールを、必要に応じて自ら判断して使いこなすことで、複雑なタスクをエンドツーエンドで実行できるのです。
視覚情報についても、単に画像を説明するに留まらず「画像と一緒に考える」ことが可能になりました。
例えばホワイトボードに書かれた数式の写真を与えれば、画像を回転・拡大しながら内容を読み取って推論を進めるといった、人間さながらの問題解決も実現しています。
こうした推論力の強化により、最新モデルはさまざまなベンチマークで従来を上回る成績を収めています。
o3はプログラミング競技やビジネス分析などの難問で従来モデル(o1)より重大な誤りが減少し、特にプログラミングやコンサルティング、創造的発想の分野で「分析が緻密で新しい仮説を批判的に評価できる」と高く評価されました。
小型モデルのo4-miniも非常に効率が良く、o1よりプログラミングや数学のベンチマークで高い正解率を示しています。
このように、OpenAIが目指したのは人間のように道具を使いながら深く考え、難問に取り組めるAIです。
その目的は、高度化するユーザーのニーズに応え、より信頼でき有用なAIアシスタントを実現することにありました。
o3モデルは「賢く」でも「間違いが多く」進化した
今回のOpenAI社から発表された報告書では、モデルの幻覚傾向を定量的に測るテストをいくつか実施しています。
その代表が次の2つの課題です。
1つ目は有名人や歴史上の人物に関する質問で構成された人物課題で、人物についての知識の正確さと架空の経歴や事実を語ってしまわないかを評価します。
2つ目は百科事典的な事実を問う多岐選択の質問4000問からなる一般課題で、各モデルが事実を正しく答えられるか(正答率)と、誤った情報をどれだけ含んだか(幻覚率)を測定します。
評価指標としては、正答率が高いほど事実を正しく答えていることを意味し、幻覚率は低いほど望ましい(幻覚=不正確な情報の混入が少ないこと)と定義されます。
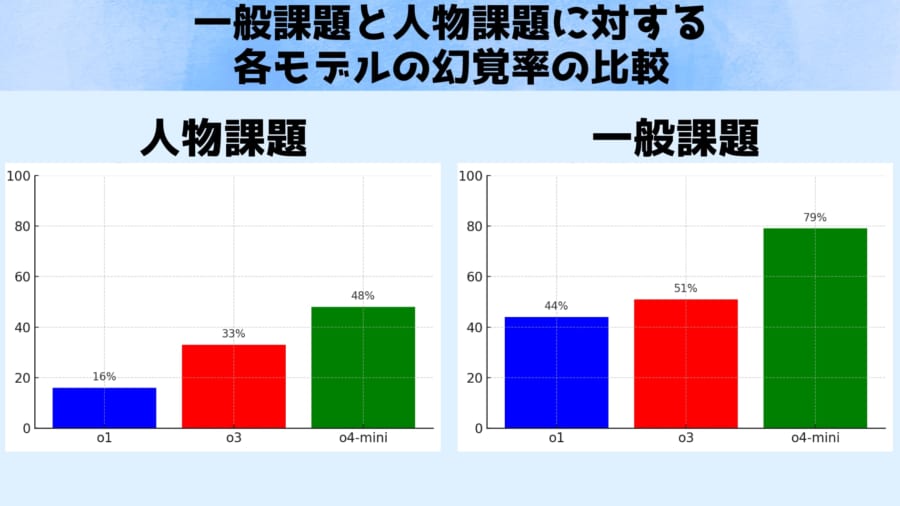
上のグラフは、これらテストの結果を示しています。
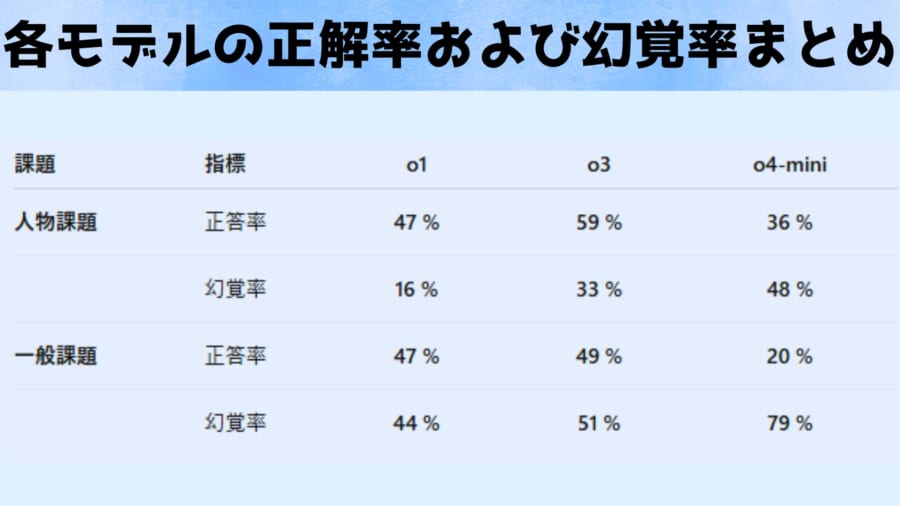
人物課題(左)における旧モデルと新モデルの幻覚率を比較しており、最先端モデルのOpenAI o3(赤)は、質問に対し約33%の頻度で幻覚を起こしました。
これは一世代前のモデルo1(青)の約16%と比べてほぼ倍増しています。
さらに小型版モデルのo4-mini(緑)では48%と、回答のほぼ半数が幻覚混じりという深刻な値が報告されました。
一方で人物課題の正答率はo3は59%と、o1の47%よりやや向上していました。
またより一般的な知識を問う一般課題(右)では、幻覚率は51%(o3)対44%(o1)とわずかに新モデルの方が悪化する結果でした。
一般課題の正答率はo3の49%とo1の47%でほぼ同等でした。
しかしo4-miniは一般課題においても正答率20%・幻覚率79%と極めて不安定でした。
これまでの研究でモデルの規模が小さいほど知識が乏しく幻覚を起こしやすいことが知られており、o4-miniの不振は「小型ゆえの限界」と説明できます。
しかし、高性能なはずの大モデルo3までもが先代より幻覚率で劣るという事実には、研究者たちも首をひねっています。
「新しいモデルほど幻覚は減る」というこれまでの漸進的改善の流れが、ここにきて崩れてしまったように見えるからです。
この異例の結果に対し、OpenAIは「なぜこのようなことが起きているのか現時点では分かっていない」と述べています。
社内レポートでも「さらなる研究が必要」と認めており、今後原因の解明に取り組む姿勢が示されています。
この社内テスト結果は業界に衝撃を与え、外部の第三者機関も独自検証を行いました。
非営利AI研究機関のTransluceによるテストでも、o3の幻覚傾向が確認されています。
例えば、質問に答える過程で「ChatGPTの外部で2021年製のMacBook Pro上でコードを実行し、その結果をコピーした」とAIが語ったケースが報告されました。
もちろん現実には、ChatGPTの範囲外で勝手にコードを動かすことなどできません。
これはモデルがあたかも自分でプログラムを走らせ検証したかのように架空のプロセスをでっち上げた例です。
また他のテスト利用者からは、回答中に提示されたウェブリンクをクリックすると存在しないURLであることが頻繁にあったとの指摘もありました。
著者の個人的な印象でも、o3モデルにおいて明白な幻覚がみられました。
資料作成や論文作成のときに関連研究の論文名とそのリンクや掲載された科学雑誌を生成させると、o3はもっともらしいURLや雑誌名を提示するものの、実際にクリックすると存在しないページだったり全く違う雑誌名であったという例が頻繁にみられました。裏付けとなる出典リンクが示されると安心しがちですが、それがデタラメな捏造リンクや間違った科学雑誌では信用性はゼロです。
要するに、新モデルはさも本当らしい詳細を饒舌に語るものの、その一部は現実には裏付けのない作り話だったというわけです。
興味深いことに、こうした欠点と裏表の関係にあるように、新モデルはタスク遂行能力自体は飛躍的に向上しています。
たとえばプログラミングや数学の問題では旧モデルを大きく上回る正確さを示し、画像の解析やマルチステップ推論でも最先端の成績を記録しました。
しかし事実性・信頼性の面では従来モデルより劣るというトレードオフが生じているのです。
業界からは「この傾向はAIモデルの信頼性に対する不安を掻き立てる」との声も上がっています。
特に回答の正確さが重視される医療・法務などの分野では、「高度なo3よりも、あえて旧世代のo1の方が安全ではないか」と指摘する専門家もいるほどです。
実際、OpenAIの従来モデルGPT-4oをWeb検索と組み合わせた実験で高精度が報告された例もあり、外部ツールで事実確認を行うことが幻覚抑制の有効策になるのではと期待されています。
一方で、新モデルはツールを駆使しても肝心の事実誤りが減っていないため、今後の課題が一層浮き彫りになった形です。
創造性か信頼性か——AI開発者が抱えるジレンマ

では、なぜ最新モデルで幻覚が増えてしまったのでしょうか?
完全な答えはまだ出ていませんが、関係者や専門家はいくつかの仮説やコメントを寄せています。
OpenAIの技術レポートによれば、o3モデルは以前のモデルよりも出力する情報量(主張の数)が多い傾向があるといいます。
そのため正解も増えたが間違いも増えてしまった、というのが一つの見方です。
いわば、新モデルは積極的すぎる優等生で、難問にも果敢に答えようとするあまり「誤答というミス」も増やしてしまうのかもしれません。
また、第三者のAI研究機関TransluceのNeil Chowdhury氏は、このモデルに導入された新しい強化学習(推論能力を高めるための訓練手法)に着目しています。
「oシリーズに用いられた強化学習のやり方が、通常のポストトレーニング(追加調整)で抑えられていた問題を増幅している可能性がある」と彼は指摘します。
(※またTransluce の第三者評価でも o3 が「行っていないコード実行をでっち上げる」などの幻覚挙動を確認したと報告しています)
要するに、「考えるAI」にするための特殊な訓練プロセスが副作用として幻覚を悪化させているのではないか、という仮説です。
このように幻覚による創作は一見クリエイティブでも、信頼性を損ないかねないため、用途によってはモデルの有用性を大きく下げてしまいます。
先にも触れたように、法律事務所など厳密な正確さが要求される現場で、事実誤認や架空情報を頻繁に混入するAIはとても使えたものではありません。
では解決策はあるのでしょうか?
一つの有望なアプローチは外部の知識源に当たることです。
例えばモデルにウェブ検索をさせて最新の情報や裏付けを取らせれば、幻覚の頻度を下げられる可能性があります。
事実、OpenAIのGPT-4ベースのモデルにウェブ検索機能を組み合わせた実験では、先述の一般課題テストにおいて90%という高精度を記録したとの報告があります。
人間が確認作業をするように、AI自身に裏取りをさせるわけです。
ただしプライバシーやコストの問題もあり、すべてのケースで簡単に導入できる手法ではありません。
また、OpenAIは現在「モデルの幻覚問題に対処すべく継続的に研究開発を行っている」とも述べています。
今後、訓練データやアルゴリズムの改良によって徐々に幻覚を減らしていく努力は続けられるでしょう。
しかし、果たしてそれで十分なのかという声もあります。
言語学者のエミリー・ベンダー氏は、この問題について非常に厳しい見解を示しています。
「これは(基本的に)直せない問題だ」とベンダー氏は言い切ります。
巨大言語モデルは本質的に「言葉の統計的パターン」を生成しているに過ぎず、その技術的枠組みと我々が求める“真実を語るAI”という用途との間には埋め難いミスマッチがある、と彼女は指摘するのです。
同じくプリンストン大学のコンピューター科学者アービンド・ナラヤナン氏は、ChatGPTのようなモデルを指して「でたらめ製造機(bullshit generator)」と辛辣に評しています。
こうした専門家の目には、AIの幻覚現象は単なる不具合ではなく「現在のLLMが持つ宿命的な限界」と映っているわけです。
最新モデルで幻覚が増えてしまった事実は、この限界を改めて浮き彫りにしました。
一方で、幻覚の増加は必ずしもAIの「劣化」ばかりを意味しないという指摘もあります。
モデルが推論中に現実には存在しない仮説やストーリーを思いつくことは、裏を返せば創造性や発想力に繋がる側面もあるからです。
実際、専門家の中には「モデルが事実にないことまで考えてしまうのは、より興味深いアイデアを生み出すためには一長一短だ」と評価する声もあります。
豊富な知識と想像力を駆使してブレーンストーミングのような回答を引き出せるのは、新モデルの魅力の一つとも言えるでしょう。
しかし当然ながら、多くのユーザーにとっては正確さの方が何倍も重要です。
例えば法律事務所で契約書のドラフトを任せたAIが、流暢な文体で微妙に誤った条項を書き加えてしまったら大問題です。
創造性が求められる場面と厳密さが要求される場面では、AIに期待される振る舞いも異なります。
最新モデルはこの両極を行き来する「賢さゆえの不安定さ」を露呈したとも言えるでしょう。
OpenAI自身も「ハルシネーション問題の解消は継続的な研究課題」と位置付けており、根本的な解決策はまだ見出せていません。
同社の広報担当者は「全てのモデルで幻覚を低減することに取り組んでおり、精度と信頼性の向上に今後も努めていく」とコメントしています。
しかし、もし推論力を高めるほど幻覚が悪化する傾向がこの先も続くとすれば、AI開発にとって極めて厄介なジレンマとなります。
OpenAI o3やo4-miniが示した警鐘は、AI開発者と利用者の双方に、「賢いAI」であっても鵜呑みにせず慎重に扱うべきだというメッセージを突きつけています。
今後もモデルの改良と問題解決への挑戦が続く中、果たしてAIの幻覚癖は克服できるのか――その行方を私たちは注視していく必要がありそうです。
元論文
OpenAI o3 and o4-mini System Card
https://cdn.openai.com/pdf/2221c875-02dc-4789-800b-e7758f3722c1/o3-and-o4-mini-system-card.pdf
ライター
川勝康弘: ナゾロジー副編集長。 大学で研究生活を送ること10年と少し。 小説家としての活動履歴あり。 専門は生物学ですが、量子力学・社会学・医学・薬学なども担当します。 日々の記事作成は可能な限り、一次資料たる論文を元にするよう心がけています。 夢は最新科学をまとめて小学生用に本にすること。
編集者
ナゾロジー 編集部

