

2022年末にOpenAIから生成AI(Generative AI)のChatGPTがリリースされ、翌年の2023年は生成AIが世界的なトレンドになりました。2025年になった現在、生成AIブームはいったん落ち着きましたが、それでもなお、もっとも注目されている技術なのは変わりありません。
しかし、生成AIをビジネスに導入するためには、表面的な知識だけではなく根幹的な仕組みを理解しておく必要があります。
そこで本記事では、AI(人工知能)の学習方法の一つである「強化学習(Reinforcement Learning)」について、初心者にも分かりやすく解説していきます。
AGI(汎用人工知能)の実現も間近ともいわれている昨今、もはやAIはビジネスに欠かせない必須技術です。本記事を参考に、AIの仕組みを正しく理解し、ビジネスに活用していきましょう!
目次
強化学習とは?

AI(人工知能)の学習方法にはさまざまなものがあります。その中の一つが「強化学習(Reinforcement Learning)」です。
ここではまず、強化学習の簡単な概要と間違えやすい用語を整理していきましょう。
関連記事:生成AIとは?AIやLLMとの違いから4つの種類、有名サービス7選と活用事例を紹介!
機械学習の一分野で、エージェント(AI)が最適な行動を学ぶ手法
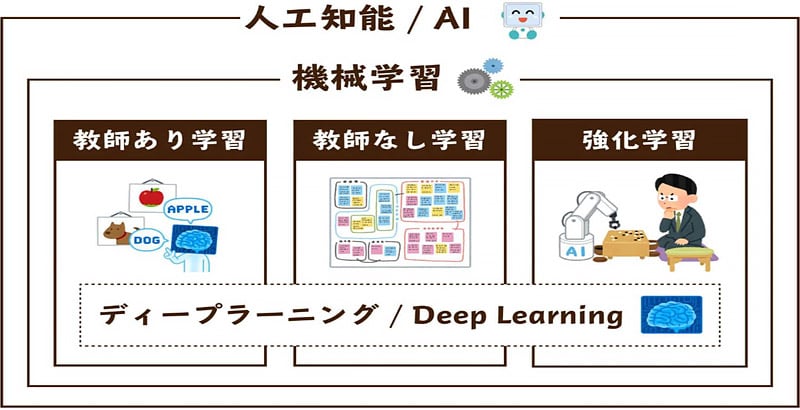
強化学習とは、機械学習の一分野で、エージェント(AI)が最適な行動を学ぶ手法のことです。
簡単にいえば、今までよりも「強化」されたAIの「学習」方法になります。
強化学習以前のAIの学習方法は、大きく分けて「教師あり学習」と「教師なし学習」の2つが主流でした。しかし、これらの方法では、AIが「どう行動すべきか」という一連の意思決定プロセスを学ぶのが難しかったのです。
そこで登場したのが強化学習です。
強化学習では、AIエージェントがある環境内で行動し、その結果として得られる「報酬(Reward)」を最大化するために試行錯誤を繰り返します。
このアプローチは、人間が何か新しいスキルや知識を習得するときの学習プロセスに非常によく似ています。
例えば、自転車に乗れるようになる過程を考えると、最初は転んでばかりですが、成功体験(転ばずに進める)を繰り返すことで、次第にうまくなっていくはずです。
これと同じように強化学習では、AIエージェントも「試行錯誤」を通じて学習していきます。
つまり、強化学習はAIが環境と相互作用しながら自ら学ぶことで、より柔軟で人間らしい意思決定ができるようになる画期的な手法なのです。
ディープラーニング(深層学習)・機械学習との違い
| 学習方法 | 機械学習 | ディープラーニング(深層学習) | 強化学習 |
|---|---|---|---|
| 概要 | コンピュータがデータからパターンを学び、予測や判断を行う技術の総称 | ニューラルネットワークを活用し、複雑な問題を解決する機械学習の一種 | 環境との相互作用を通じて、最適な行動を学ぶ機械学習の一種 |
| データの種類 | 構造化データ(表形式のデータ)が多い | 画像、音声、テキストなどの非構造化データ | シミュレーション環境や実世界での相互作用から得られるデータ |
| 主なアルゴリズム | 決定木、SVM、線形回帰、ロジスティック回帰など | CNN(畳み込みニューラルネットワーク)、RNN(リカレントニューラルネットワーク)など | Q学習、SARSA、ディープQネットワーク(DQN) |
| 特徴 | 比較的単純なモデルで効率的に学習が可能 | 大量のデータと計算リソースが必要、パラメータ調整が難しい | 試行錯誤の過程で失敗が許容されるシナリオに強い |
AIの学習方法には、似たような名前のものがたくさんあります。そのため、ディープラーニング(深層学習)や機械学習などと混同してしまう人も少なくありません。
まず、機械学習とは、コンピュータがデータを使って自らパターンを学習し、予測や判断を行う技術のことです。
機械学習は、統計学や数学を基盤とし、主に「教師あり学習」「教師なし学習」「強化学習」の3つの方法に分類されます。
次に、ディープラーニング(深層学習)は、機械学習の中でも特に「ニューラルネットワーク」というアルゴリズムを活用した手法です。
通常の機械学習が比較的単純なモデルを使うのに対し、ディープラーニングでは多層構造を持つネットワークを使い、画像認識や自然言語処理など複雑な問題に対処できるようになります。
したがって、強化学習は機械学習のカテゴリの一つであり、ディープラーニング(深層学習)はより複雑なデータを扱うために考案された手法です。
教師あり学習・教師なし学習について
| 学習方法 | 教師あり学習 | 教師なし学習 | 強化学習 |
|---|---|---|---|
| 概要 | 正解(ラベル)が付いたデータを使って学習する方法 | 正解(ラベル)がないデータからパターンや構造を見つける方法 | 環境内で試行錯誤しながら「報酬」を最大化するための行動を学ぶ方法 |
| 学習の仕組み | 「入力」と「正解」のセットをもとに、答えを予測できるように学ぶ | データの特徴やグループを自動的に発見する | 行動を選択し、その結果得られる報酬に基づいて学習する |
| 分かりやすい例え | 先生が問題と答えを教えてくれる授業 | 自分でパズルを解いて、隠れたルールを見つける | ゲームを繰り返し遊びながら勝つ方法を学んでいく |
| メリット | 精度が高い予測が可能 | ラベル付けが不要で大量のデータを活用可能 | 自律的な意思決定や行動計画ができる |
| デメリット | ラベル付きデータの作成に手間がかかる | 結果の解釈が難しい場合がある | 試行錯誤の過程で失敗を繰り返すため、時間やリソースが必要 |
| 主な用途 | 画像認識(猫か犬かを判定)、スパムメール検出、価格予測 | 顧客の分類(似た特徴を持つグループの特定)、ニュースのテーマ分析 | ゲームAI(囲碁やチェス)、ロボット制御、自動運転 |
強化学習をより深く理解するためには、「教師あり学習」と「教師なし学習」についても知っておいたほうがよいでしょう。
教師あり学習とは、正解が分かっているデータ(ラベル付きデータ)を用いてモデルを訓練する方法です。
簡単にいえば、「入力データ」と「それに対応する正しい答え(ラベル)」をセットで与え、モデルがその対応関係を学習します。
例えば、メールが「スパム」か「スパムではないか」を判断するモデルを作る場合、スパムメールとスパムではないメールの例をたくさん用意し、それぞれにラベルを付けてモデルを訓練します。訓練が進むと、未知のメールに対してもスパムかどうかの予測が可能です。
それに対し、教師なし学習は、ラベルが付いていないデータを使い、そのデータのパターンや構造を見つける方法です。
ここでは「正解」、つまり教師に当たるようなデータが存在しないため、モデルがデータの隠れた構造や関連性を自動的に学習します。
例えば、顧客データをもとに「似たような特徴を持つ顧客グループ」を特定したり、大量のニュース記事からテーマごとのトピックを抽出したりするのが教師なし学習の典型例です。
このように、教師あり学習と教師なし学習は「データ」を基盤としてモデルを構築しますが、強化学習は「試行錯誤」を通じて行動方針を学ぶという点で、根本的に異なるアプローチをとっています。
深層強化学習でより複雑な学習が可能に
近年では、深層強化学習という、従来の強化学習とディープラーニング(深層学習)の2つを組み合わせた手法も注目され始めました。
深層強化学習(Deep Reinforcement Learning)とは、強化学習の枠組みにディープラーニングの技術を統合した手法です。
従来の強化学習では、エージェントが環境の「状態(State)」を直接理解し、次の行動を選択するためには、状態空間(エージェントが認識する世界)が単純である必要がありました。
しかし、現実世界や複雑なシミュレーション環境では、状態空間が非常に大きく複雑で、従来の手法では扱いきれないことが多かったのです。
ここで、ディープラーニング(深層学習)が役立ちます。
ディープラーニングの「特徴抽出」という能力を活用することで、膨大で複雑な状態空間を効率的に処理し、強化学習の枠組み内で利用可能にします。
これにより、従来では解決が難しかった高次元の問題にも対応できるようになったのです。昨今では、画像生成AIや動画生成AIの進化が著しいですが、これは深層強化学習の進化による部分も大きいといえます。
特にデジタルツイン・シミュレーションの分野での活用に期待
深層強化学習が現実的になったことにより、活用が期待されている分野が「デジタルツイン」などのシミュレーション分野です。
デジタルツインとは、現実世界の物理システムやプロセスをデジタル空間に忠実に再現した仮想モデルのことです。
以前からデジタルツインにはAIが導入されていましたが、「複雑な環境の制御」や「高次元のデータ処理」が課題として残っていました。
従来のAI技術では、複雑なシステムの全体を十分に理解して最適な行動を導き出すことが難しかったのです。しかし、深層強化学習を利用すれば、これらの課題を解決できる可能性があります。その理由は以下の5点です。
- 安全性の確保:仮想環境内で試行錯誤が可能で、現実世界へのリスクがない
- 複雑な環境の対応力:高次元で複雑な状態空間を処理する能力がある
- リアルタイムに対応:シミュレーションを高速に動作させることで、迅速な学習と最適化が可能
- 費用対効果が向上:実環境での試行錯誤を省略し、コストと時間を大幅に削減
- 汎用性の高さ:製造業、交通、エネルギー管理、宇宙開発など、多岐にわたる分野で応用可能
これにより、例えばスマートシティなどの都市計画や、製造業などの生産ライン、航空や宇宙シミュレーションなど、さまざまな実世界の用途に応用が期待されています。
関連記事:デジタルツインを企業事例とともに分かりやすく解説!メリット・将来性についても
強化学習の基本的な仕組み
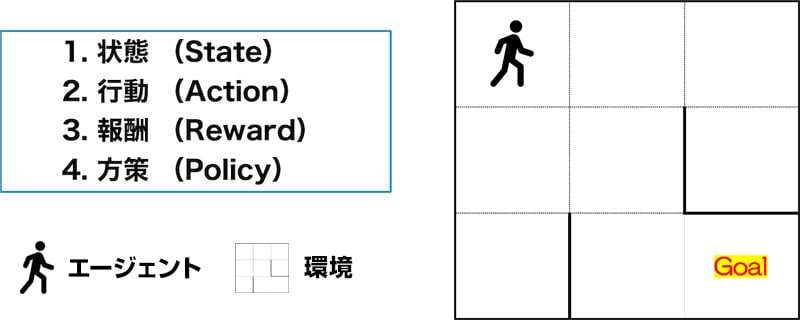
強化学習の仕組みは非常にシンプルです。強化学習は、基本的に下記4つを繰り返して学習していきます。分かりやすいように迷路を例にとって解説していきます。
- 状態(State)
- 行動(Action)
- 報酬(Reward)
- 方策(Policy)
①状態(State)

強化学習において、出発点といえるのが「状態(State)」です。
状態(State)とは、簡単にいえば「エージェント(AIやプログラム)が現在置かれている環境や状況」を指します。
つまり、エージェントが次に何をすべきか判断するための情報基盤です。
人間に例えると、「今、自分がどこにいて、何をすべきかを把握するための視覚や感覚の情報」に相当します。
上記画像の迷路を例に考えてみましょう。迷路では、エージェントが現在どのマスにいるかが「状態」として表現されています。
画像では迷路は9つのマス(S1〜S9)に分割されており、エージェントは「S1」というマスにいて、エージェントの状態は「S1」として定義されます。その後、エージェントが行動(例えば、右へ移動)を選択すると、現在の状態(S1)から新しい状態(S2)へと変化します。
このように、状態(State)はエージェントが行動するたびに変わり、次の行動の判断材料となるデータです。
②行動(Action)
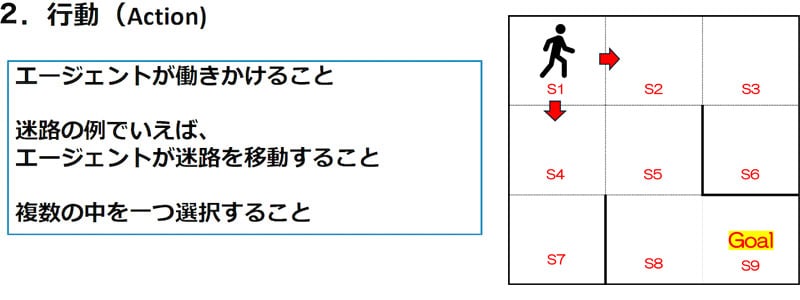
エージェントが状態(State)を把握すると、次に行動(Action)へ移行します。
行動(Action)とは、簡単にいえば「エージェントが現在の状態に基づいて環境に働きかけるための選択」です。この行動によって、エージェントは環境に変化をもたらし、目標に近づいたり、新たな状態へ移行したりします。
人間に例えると、「今の状況を踏まえて自分が次に何をするか決めること」に該当します。
上記画像を例に考えてみましょう。この迷路では、エージェントが「Start」の位置にいます。この状態からエージェントが次にとる行動(Action)として、以下の選択肢があります。
- 右へ移動する(矢印で示されるように隣のマスへ進む)
- 下へ移動する(別の矢印で示されるように下のマスへ進む)
これらの行動のいずれかを選択することで、エージェントは新しい状態(State)に遷移します。
1を選択した場合
右へ移動すると、エージェントは次に進む道が1つしかなく(行動の自由度が低い状態)、いずれ行き止まりになってしまいます。この経験からエージェントは、「1を選択すると目標(Goal)にたどり着けない」ということを学習します。
2を選択した場合
下へ移動すると、エージェントは次の状態で選択肢が2つに広がります(行動の自由度が高い状態)。この状態において、エージェントは「目標(Goal)に近づける可能性がある行動を試行錯誤する」ことを繰り返し、最終的に正しい経路を学習します。
このように、エージェントは何度も行動(Action)を繰り返すことで、目標(Goal)への到達方法を学習していくのです。
③報酬(Reward)
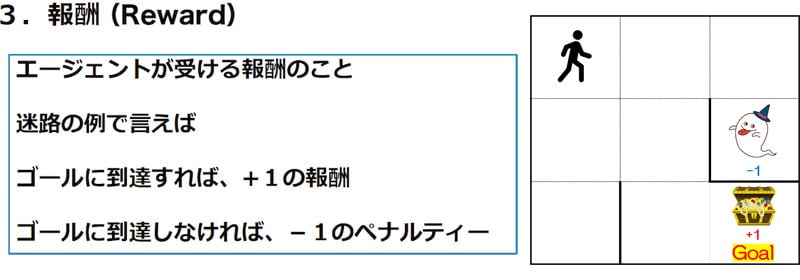
エージェントが行動(Action)をした後、行動した先の状態(State)が目標(Goal)に近づいているかどうかを判断させる必要があります。そこで登場するのが「報酬(Reward)」という考え方です。
報酬(Reward) とは、簡単にいえば「エージェントの行動がよかったか悪かったかを数値で評価する仕組み」です。
人間に例えると、「子どもがよいことをしたときは褒めて、悪いことをしたときには叱って学習させる」という教育方法に似ています。
上記画像の迷路を例にとって考えてみましょう。この迷路では、以下のように報酬が与えられます。
ゴール(Goal)に到達した場合
エージェントがゴール(右下のマス)にたどり着いた場合、報酬として「+1」が与えられます。これで、エージェントは「目標を達成した」という行動の正しさを評価し、学習します。
失敗した場合
もしエージェントが「ゴールに到達できない」あるいは「行き止まりに進む」といった行動をとった場合、「-1」のペナルティが与えられます。このペナルティは、エージェントが望ましくない行動をとったことを示し、次回以降に同じミスを繰り返さないよう学習を促します。
このように、報酬(Reward)によってエージェントは自分の行動が正しいものか評価できるようになるのです。
④方策(Policy)

報酬(Reward)によって、エージェントは正しい選択肢を見つけることができますが、同じような選択肢を与えられた際に、次は必ず正解の選択肢を選ばせる必要があります。そこで登場するのが「方策(Policy)」という考え方です。
方策(Policy)とは、エージェントが現在の状態(State)に基づいて「次にどの行動(Action)を選択すべきか」を決めるためのルールまたは行動指針のことです。
人間に例えると、「間違ったことをしたときに叱られて、次から同じ間違いを犯さないようになる」現象と似ています。
上記画像の迷路を例に考えてみましょう。この迷路では、エージェントが「Start」から「Goal」を目指します。しかし、エージェントがどの道を選ぶかには以下のシナリオがあります。
- Startの位置で右に進む:ゴールに近づけない方向であり、失敗(幽霊に到達)する可能性が高い
- Startの位置で下に進む:ゴール(Goal)に向かうために、選択肢が広がる正しい行動
方策(Policy)は、このような状況で「どの行動を選ぶべきか」をエージェントに教えるルールです。例えば、この場合の方策は、「Startの位置では下に進むことを優先する」といった形で学習されます。
このように、方策(Policy)が適切に学習されると、エージェントは別のシチュエーションでもGoalに近づくような最適な行動をとり始めるのです。
強化学習の代表的なアルゴリズム一覧
| アルゴリズム | 特徴 | ポリシー | 更新タイミング | 適用例 |
|---|---|---|---|---|
| Q学習 | 最大Q値に基づいて更新する | オフポリシー | 各ステップ | 離散的な状態・行動空間 |
| SARSA | 実際にとった行動に基づいて更新する | オンポリシー | 各ステップ | ノイズの多い環境 |
| モンテカルロ法 | エピソード全体を通じて累積報酬を考慮する | オンポリシー | エピソード終了後 | ゲームや完結するタスク |
| DQN | Q学習+ニューラルネットワーク | オフポリシー | 各ステップ(経験再生) | ゲームAI、大規模な環境 |
状態(State)、行動(Action)、報酬(Reward)、方策(Policy)の4つのサイクルを回すためには、エージェントに具体的なアルゴリズム、つまりルールを与える必要があります。
しかし、アルゴリズムには非常に多くの種類があり、それぞれできる処理も変わってくるので注意が必要です。
そこでここからは、現在の強化学習アルゴリズムにおいてもっとも代表的な「Q学習」、「SARSA」、「モンテカルロ法」、「DQN」という4つのアルゴリズムについて、分かりやすく解説していきます。
Q学習
Q学習(Q-learning)とは、簡単にいえば「ゲームの攻略法を試行錯誤して覚えるように、環境の中で行動を選び、どうすればよい結果を得られるかを学ぶアルゴリズム」です。
強化学習において、もっとも基本的で有名な方法の一つになります。なお、前項の迷路の画像はQ学習をイメージしたものです。
前項の画像でいうと、ロボットはゴールまでの道順を最初は知りませんが、何度も迷路を進むうちに「この方向に進むとよい結果になる」と学んでいきます。この学びの過程で使うのが「Q値」という数字です。
Q値は「その場面(状態)で、ある行動をとった場合に将来どれくらいよい結果(報酬)が期待できるか」を表します。
Q値が高いほど「その行動を選ぶ価値がある」と判断されますが、新しい可能性を探るためにランダムに行動すること(探索)も重要です。この「探索と活用のバランス」を調整することで、エージェントは徐々に最適な行動を学びます。
このように、Q学習は非常にシンプルなアルゴリズムなので、多くのアルゴリズムのベースになっています。
SARSA(時間差分学習)
SARSA(時間差分学習)とは、簡単にいえば「ある行動をとった結果を次の行動まで含めて考えながら、最適な行動を学んでいくアルゴリズム」です。
なお、SARSAという名前の由来は、アルゴリズムでよく使われる以下の5つの要素の頭文字から来ています。
- S:現在の状態(State)
- A:現在選択した行動(Action)
- R:行動の結果得た報酬(Reward)
- S':次の状態(Next State)
- A':次に選択した行動(Next Action)
SARSAとQ学習は非常によく似た仕組みをしていますが、SARSAは「実際にとった行動(A')」に基づいてQ値を更新します。一方、Q学習は「次の状態での最大Q値」に基づいて更新します。
また、SARSAがエージェントが現在使っている方策(Policy)に基づいて学ぶ「オンポリシー」なアルゴリズムであるのに対し、Q学習は方策(Policy)に依存しない「オフポリシー」なアルゴリズムです。
このように、SARSAは現在の方策(Policy)に基づいて学習するため、環境が変化してもその時点での現実的な行動方針を学習しやすい特徴があります。
つまり、SARSAは現実世界のようにノイズや変化が多い環境の学習に適したアルゴリズムです。
モンテカルロ法
モンテカルロ法とは、簡単にいえば「たくさんの試行を繰り返して、その結果を平均することで、最適な行動や状態の価値を推定するアルゴリズム」です。
モンテカルロ法の最大の特徴は、エピソードの終了後に価値を更新することです。
ここでの「エピソード」とは、ある状態からスタートしてゴール(または終了条件)に到達するまでの一連の流れを指します。各エピソードの報酬をもとに、状態や行動の価値を計算していきます。
エピソード終了後にまとめてアルゴリズムを更新するため、途中の状態や行動にあまり依存しません。これにより、学習が直感的でシンプルになります。
また、ゴールに到達するまでの全体的な流れを考慮するため、短期的な判断ではなく長期的な利益を学ぶのに適しているアルゴリズムです。しかし、価値を更新するにはエピソード全体の情報が必要です。そのため、無限に続くようなタスクには適していません。
DQN(Deep Q-Network)
DQN(Deep Q-Network)は、簡単にいえば「Q学習にディープラーニング(深層学習)を組み合わせたアルゴリズム」です。
DQNでは、Q学習の弱点である「状態や行動が多すぎると学習が難しくなる(次元の呪い)」という問題を解決するために、ディープニューラルネットワーク(DNN)を使ってQ値を近似します。これにより、現実世界のような複雑な状態空間でも、効率的に最適な行動を学ぶことが可能です。
ニューラルネットワークの仕組みを説明すると非常に専門的になるので割愛しますが、DQNではDNNを活用して「状態を入力すると、その状態で各行動をとった場合の価値(Q値)を出力する」という形で、膨大な状態空間の情報をコンパクトに表現します。
そのため、Q学習ではテーブルとして管理しきれなかった複雑な状況にも対応できるようになるのです。2015年にDeepMind社がNature誌に掲載した論文によると、DQNを利用したAIがゲーム攻略において人間のパフォーマンスを超えたともされています。
これ以降、DQNを基盤にしたアルゴリズムも多数開発されており、その意味では、DQNは現在の強化学習アルゴリズムの基盤といえるかもしれません。
強化学習で何ができる?活用事例5選を紹介!
では、強化学習を活用すると具体的に何ができるようになるのでしょうか?
ここからは、下記5つの分野における強化学習の活用事例をご紹介します。
- ゲーム×AI
- 自動運転
- 自律移動ロボット(ロボティクス)
- 金融・経済
- 医療
①ゲーム×AI
強化学習により、AIを組み合わせたゲームの開発が可能になります。従来のゲームで使用されるAIは、あらかじめ決められた行動パターンに基づいて動くことが一般的でした。
しかし、強化学習を活用することで、AIはプレイヤーの行動に応じて柔軟に対応できるようになります。例えば、以下のようなAIゲームを実現できます。
- プレイヤーの戦略や行動パターンを学習し、より賢く、より挑戦的なプレイ体験を提供するNPC(ノンプレイヤーキャラクター)
- ゲームプレイヤーのスキルに応じて、リアルタイムでゲームの難易度を調整するシステム
- プレイヤーと対等、もしくはそれ以上に競争力のあるAIプレイヤーを作成
- プレイヤーの選択や行動を学習し、もっとも楽しめるストーリーを個々に展開
このように、従来のルールベースのAIでは実現が難しかったダイナミックなゲーム体験を提供できます。
②自動運転
自動運転の分野では、強化学習による複雑な環境での意思決定の最適化が非常に役立ちます。
自動運転においてもっとも重要なのは、安全性の確保と効率的な走行といえますが、強化学習を活用することで、以下のような技術的課題を克服できます。
- 交通信号、ほかの車両、歩行者などの動的な要素をリアルタイムで認識し、それに応じて適切な判断を行う
- 都市部や高速道路などの異なる環境において、燃費や走行時間を最適化したルートを自律的に選択する
- 突然の飛び出しなどの予測困難な状況においても即時対応を行う
すでに、GoogleのWaymoやTeslaなどの企業が開発している自動運転システムにも応用されており、今後は強化学習でトレーニングされた自動運転車が多く登場することになるでしょう。
③自律移動ロボット(ロボティクス)
自律移動ロボットなどのロボティクスの分野においても、強化学習でトレーニングされたAIモデルが役立ちます。
自律移動ロボットにおいて、効率的な経路探索や障害物回避能力は非常に重要です。強化学習を活用することで、ロボットが以下のようなタスクを高精度に実行できるようになります。
- センサーから得た情報をもとにリアルタイムで最適なルートを見つける
- 移動中に突然現れる障害物や動的に動く対象(ほかのロボットや人間など)を素早く検知し、安全に回避
- 倉庫内での商品のピッキングや搬送作業など、複雑なタスクを効率的に実行
- 各ロボットが互いの動きを学習しながら効率的に協働
例えば、Amazonの物流倉庫で使用されているロボットは、強化学習を活用して商品を迅速かつ正確にピッキングし、倉庫内を移動します。ロボティクスは日本がもっとも得意とする技術分野でもあるので、特に日本市場での活用に期待がかかっています。
④金融・経済
金融・経済の分野において、強化学習は効率的な資産運用や市場予測の最適化に大きな役割を果たしています。
金融の世界では膨大なデータがリアルタイムで生成され、価格変動や市場のトレンドを予測しなければなりません。従来のルールベースのアルゴリズムでは対応しきれない複雑な状況下でも、強化学習を活用することで以下のようなタスクを実現できます。
- 異なる資産クラス(株式、債券、暗号通貨など)の間でリスクとリターンをリバランスさせ、最適なポートフォリオを構築
- ミリ秒単位で価格変動を分析し、最適な売買タイミングを決定
- 取引戦略を自律的に改善し、動的な市場変化に適応させる
- 市場での異常なパターンや潜在的なリスク要因を早期に検出
例えば、JPモルガンでは強化学習を活用した量子コンピューティング技術により、市場予測やリスク管理の精度を向上させています。このように、強化学習を導入することで、金融機関や投資家は人間の直感では難しいほど多様で複雑な市場パターンを理解できるようになります。
⑤医療
医療の分野において、強化学習は診断の精度向上や治療計画の最適化など、多岐にわたる用途で革新をもたらしています。
医療は患者ごとに状況が異なるため、従来の静的なアルゴリズムでは対応が難しい場面が多いのが課題でした。しかし、強化学習を活用することで、動的かつ個別最適化された医療サービスを提供することが可能になります。
- 患者の病歴や現在の状態をもとに、最適な治療プランを提案
- 強化学習を導入した外科手術ロボットが、手術中に状況を判断しながら医師を補助
- 患者の健康データを分析し、生活習慣病や慢性疾患のリスクを予測
- 腫瘍に対する放射線の照射量や照射角度を最適化し、副作用を最小限に抑える
例えば、富士フイルムでは「SYNAPSE VINCENT」という医療用の3D画像解析技術がすでに開発されています。このように、医療分野での強化学習の活用は、患者のQOL(生活の質)の向上に大きく寄与する技術として注目されており、未来のヘルスケアに革新的な進展をもたらすでしょう。
強化学習の効率化を実現するOmniverseとIsaac Sim
強化学習でAIエージェントをトレーニングするには、大量の計算リソースやGPUを活用する必要があります。そこでおすすめなのが、NVIDIA社の提供する「Omniverse(オムニバース)」と「Isaac Sim」です。
分かりやすく例えるとするならば、Omniverse(オムニバース)はAIエージェントが活動するための仮想的な世界を提供するプラットフォームであり、Isaac Simはその中でロボティクスシミュレーションを実行するための特化アプリです。
仮想空間プラットフォーム「Omniverse(オムニバース)」
Omniverse(オムニバース)は、NVIDIA社が提供する仮想空間プラットフォームです。
強化学習をビジネスに導入するためには、特定の状態(State)において何度も試行錯誤を繰り返してデータを蓄積しないといけません。しかし、これを物理的な環境で実施するには、時間やコスト、安全性などの面から困難といわざるを得ません。特に、製造ラインの最適化や自動運転のトレーニングなど、複雑なタスクではその影響が顕著です。
Omniverse(オムニバース)では、仮想空間内で現実とほぼ同等のシミュレーションを実施できるため、こうした制約を大幅に軽減できます。
3Dモデリングや物理演算を活用し、センサーデータや実験データをもとにしたシナリオで何度でも安全かつ効率的に学習プロセスを実行可能です。例えば、製品設計のプロセスやロボットの動作計画を仮想空間内で試験することで、リスクを最小限に抑えつつ、精度の高い成果を得ることができます。
なお、Omniverseについては以下の記事でも詳しく解説しているので、ぜひ併せてお読みください。
関連記事:Omniverse(オムニバース)とは?特徴やできること・活用事例、ライセンス形態を解説!
ロボットシミュレーションアプリ「Isaac Sim(アイザックシム)」
Isaac Sim(アイザック シム)は、Omniverse上で動作するロボットシミュレーション専用のアプリです。
Omniverseと同様に、仮想環境内のシミュレーションのために利用されますが、Isaac Simはロボットシミュレーションに特化しています。例えば、LiDAR、RGBカメラ、深度センサー、IMU(慣性計測装置)などのロボットに搭載されるセンサー類も高度に再現できます。
また、ロボット開発で広く使われるROS(ロボティクス用のOS)と直接連携し、仮想環境でROSベースのソフトウェアをテスト可能です。
Isaac Simについては、以下の記事で詳しく解説しているので、ぜひ併せてお読みください。
関連記事:Isaac Simとは?特徴・活用事例・始めるのに必要なツールを紹介!
現実のロボットに適用するなら「Sim2Real」を活用しよう!
Omniverse(オムニバース)とIsaac Simを活用すれば、強化学習によってトレーニングされたAIロボットを開発できます。しかし、その際には「Sim2Real(Simulation to Real)」という手法を一般的には取り入れます。
Sim2Realとは、シミュレーション環境で学習したAIモデルを現実のロボットにスムーズに適用するための技術やプロセスのことです。
さらに噛み砕いて説明すると、仮想世界と現実のギャップ(リアル・ギャップ)を埋める技術です。仮想空間では、環境条件や物理法則を完璧に再現しているように見えても、現実とは細かな違いが存在します。例えば、床の摩擦、物体の質感、照明条件などが異なる場合、ロボットの挙動が変わることがあります。
Omniverse(オムニバース)とIsaac Simは、両方ともSim2Realの考え方を忠実に再現しているので、リアル・ギャップを最小限に抑えることが可能です。
【まとめ】強化学習でAIビジネスを加速できる!
本記事では、強化学習の基本的な仕組み、代表的なアルゴリズム、活用事例、そしてNVIDIA社の「Omniverse」や「Isaac Sim」を活用した最先端の技術について解説しました。
強化学習は、AIエージェントが試行錯誤を通じて最適な行動を学ぶ仕組みであり、ゲームや自動運転、ロボティクス、さらには金融や医療分野に至るまで幅広く応用されています。
強化学習の可能性をビジネスで最大限に引き出すには、仮想空間やシミュレーション環境の活用が鍵となります。今後、強化学習はより多くの業界で導入され、ビジネスや生活に革命をもたらすでしょう。
本記事が、強化学習を取り入れたAI活用を検討している方々の一助となり、ビジネスの効率化や革新の実現に役立てば幸いです。
監修者:麻生哲
明治大学理工学部物理学科を卒業後、ITベンチャーにて多数のプロジェクトを成功に導く。子会社を立ち上げる際には責任者として一から会社を作り上げ、1年で年商1億円規模の会社へと成長させることに成功。現在は経験を活かし、フリーランスとしてコンテンツ制作・WEBデザイン・システム構築などをAIやRPAツールを活用して活動中。
※ 本記事は執筆時の情報に基づいており、販売が既に終了している製品や、最新の情報と異なる場合がありますのでご了承ください。

