沖縄科学技術大学院大学(OIST)による研究によって、ロボットがブロックで遊びながら「赤ちゃんのように」言葉を学習する取り組みが注目を集めています。
私たち人間は、熱いものに触れて「熱い」と感じたり、転んで痛い思いをしたりする中で言葉と世界を結びつけて理解していきます。
ところが従来のAIは、大量のテキストデータこそ扱えるものの、実際に体験を通じて学ぶわけではありませんでした。
今回の研究では、ロボットアームがカメラを使って物体を見ながら自らブロックを動かし、その動作と指示文(「赤いブロックを左へ移動」など)を同時に学習することで、より人間に近い“言葉の意味”の理解に到達しつつあります。
では、このように「赤ちゃんのように学ぶAI」は、果たして本当に“言葉の意味”をわかるようになるのでしょうか?
研究内容の詳細は『Science Robotics』にて発表されました。
目次
- なぜ赤ちゃんは意味を知り、AIは知らない? 発達心理学から読み解く背景
- なぜ赤ちゃんのようにAIを学習させると「想像力」がつくのか?
なぜ赤ちゃんは意味を知り、AIは知らない? 発達心理学から読み解く背景
近年、ChatGPTのように膨大な文章データをもとに言語処理を行う大規模言語モデルが注目を集めています。
これらのモデルは非常に流暢に文章を生成できますが、実際には「意味を体験的に理解する」という点が十分でないという指摘があります。
たとえば「熱い」「軽い」といった言葉を、人間は直接触れたり持ち上げたりする経験を通じて感覚と結びつけます。
しかし、大規模言語モデルは文字情報だけで学習しているため、実際にものを触る体験や行動の試行錯誤を含まないのです。
一方で、人間の赤ちゃんは自分の体験を通じて言葉を覚えます。
たとえば赤ちゃんは、転んで痛い思いをしながら「痛い」という言葉を学び、熱いお湯に触れて「熱い」を知るように、行動と感覚を重ね合わせながら言語を身につけていきます。
こうした「身体を通した学習」は、ただ単に単語を記憶するだけでなく、その背後にある現実の状況や行為を理解するうえで欠かせないプロセスです。
今回の沖縄科学技術大学院大学(OIST)の研究は、ロボットに「赤ちゃんが言語を覚えるようなプロセス」を取り入れることで、言葉と行動を同時に学習できるAIをめざしています。
これまでは「ロボットは指示どおりに動くが、その言葉の意味を本当に理解しているわけではない」というイメージが強かったかもしれません。
しかし、実際にブロックをつかんだり動かしたりする経験から、言葉と動作が密接に結びつくならば、AIも「赤ちゃんのように」意味をつかめる可能性があるのです。
これは従来のテキストベースの学習だけでは得られない、人間に近い理解の仕組みを作り出すうえで大きな一歩といえます。
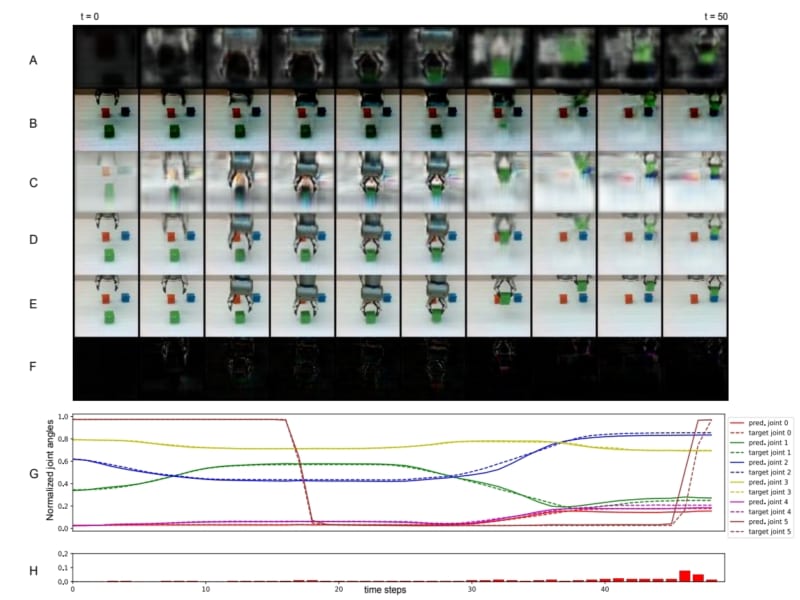
研究では、まずロボットアームにカメラを取り付け、白いテーブルの上に置かれた複数の色のブロックを見せながら「赤いブロックを左へ動かして」「緑のブロックを青の上に載せて」などの指令を与えました。
ブロックは赤・緑・青・黄・紫の5色で、それぞれの色を表す単語(名詞)と、“つかむ”“動かす”“上に置く”など合計8種類の動作(動詞)を組み合わせて学習させたのです。
学習自体は、ロボットが実際にブロックをつかんで動かし、カメラ映像やアームの動きを見比べながら「言葉と行動」を同時に覚えていくという仕組みで進められました。
(※この研究では、人間が脳内で行っていると考えられる「予測と誤差修正」のメカニズムをAIモデルにも取り入れている。
専門的には「予測コーディング(Predictive Coding)」や「自由エネルギー原理(Free-Energy Principle)」と呼ばれ、赤ちゃんが体験を通じて世界を理解する過程の理論的モデルを応用している。)
驚くべきは、このようにして言葉を身につけたロボットが、学んだことのない単語の組み合わせでも“正しく”動作を推測できるようになった点です。
たとえば「move red left(赤いブロックを左へ動かす)」と「put green on blue(緑色のブロックを青色の上に置く)」を別々に学習していたロボットが、まだ聞いたことのない「put red on blue(赤色を青色の上に置く)」という指令を受けても、その意味を理解してブロックを積めるようになったのです。
この結果は、単に音声やテキストとして“言葉”を覚えるだけでなく、実際の動作と結びつけることで、ロボットが人間に近い柔軟な理解の仕組みを獲得し始めていることを示唆しています。
実際には64×64ピクセルという低解像度の映像しか見えないロボットにとって、ブロックの位置や色を見分け、正しく動かすのは簡単ではありません。
それでもこの方法で訓練されたAIは、物体の特徴や動き、さらに言語表現を関連づけて考えられるようになりました。
結果として、人間が新たに与えた指令文に対しても、それを“再利用”して自分なりの行動プランを立てられるというわけです。
こうした汎化(一般化)の力こそが、今回の実験で最大の注目点と言えるでしょう。
なぜ赤ちゃんのようにAIを学習させると「想像力」がつくのか?

人間の赤ちゃんは「熱いものに触ったら手を引っ込める」「転んだら痛い」といった日々の体験を通じて、言葉と行動、さらに感覚を結びつけています。
これは単に「熱い=Hot」という単語を暗記するのではなく、実際の身体や周りの世界を五感で感じながら「何が起こったか」を学ぶからこそ可能になるのです。
そして、言葉を一つずつ覚える段階を経て、やがては「熱いスープをこぼしたら大変だ」といったまったく新しい状況にも応用できる“想像力”を働かせるようになります。
同じことをAIに取り入れようとしたのが、今回のロボットによる学習方法です。
ロボットが実際にブロックをつかんで動かし、「赤いブロックを置く」「緑のブロックを積む」といった動作を繰り返すうちに、単語(名詞や動詞)と実際の動作シーンとが深く紐づきはじめます。
すると、すでに学んだパーツ(たとえば「赤いブロック」「上に置く」など)を組み合わせて、見たことのない新しい指令にも自分なりに対応できるようになるのです。
これが“コンポジショナリティ(構成能力)”と呼ばれる仕組みで、「知っている動作」と「知っている名詞」を組み合わせて、まったく新しい指令文も“想像”して実行できるようになります。
つまり、赤ちゃんが「ママ」「抱っこ」「熱い」「冷たい」といった言葉を覚えた後に、「ママが熱いスープを抱っこする」という状況を想像できるようになるのと同じで、AIも自分の動きや視覚情報を通じて「言葉の組み合わせ」を応用できるというわけです。
これはテキストだけで学んだAIには難しい、人間らしい柔軟性や想像力を育む大きなカギだといえます。
今回の研究の最大の意義は、AIに「身体を使って学習させる」という発想を取り入れたことで、単なる言葉の暗記ではなく、言葉と行動・映像認識が一体となった理解を実現しつつある点にあります。
ロボットが自分の目でブロックを見て、アームを動かして触れ、そしてその一連の経験を言語表現と合わせて学習する――これはまさに赤ちゃんが世界を認識し、言葉を覚えていく過程を模倣しようとする試みです。
結果として、未学習の指令でも“応用力”を発揮できるようになったことは、コンピュータがただ指示どおりに動くだけの存在から一歩進み、より柔軟で人間に近い思考プロセスを獲得し始めていることを示唆します。
今後、こうした手法がさらに発展すれば、高齢者や子どもの世話をする介護・教育ロボット、さらには災害救助や宇宙探査など、未知の環境に柔軟に対応しなければならない分野への応用が期待されます。
また、多くの種類の物体や動作を学習することで、より複雑な指令にも対応できるようになるかもしれません。
これは、大規模言語モデルがテキスト情報の理解を深めるのとは別のアプローチであり、両者を組み合わせることで、さらに高度なAIが誕生する可能性もあります。
一方で、まだ解決すべき課題もあります。
たとえば視覚の解像度が低いロボットを実世界で運用する際には、環境のノイズや複雑さに対してどこまで対応できるのか、継続的な学習をどう設計するのか、といった問題が残っています。
それでも、人間の赤ちゃんが体験の積み重ねを通じて成長していくように、AIが「試行錯誤しながら世界を知る」道筋を示したことは大きな前進です。
今後の研究を通じて、このアプローチがどのようにロボットの“理解”と“創造力”を高め、私たちの社会を豊かに変えていくのか、ますます目が離せないでしょう。
元論文
Development of compositionality through interactive learning of language and action of robots
https://doi.org/10.1126/scirobotics.adp0751
ライター
川勝康弘: ナゾロジー副編集長。 大学で研究生活を送ること10年と少し。 小説家としての活動履歴あり。 専門は生物学ですが、量子力学・社会学・医学・薬学なども担当します。 日々の記事作成は可能な限り、一次資料たる論文を元にするよう心がけています。 夢は最新科学をまとめて小学生用に本にすること。
編集者
ナゾロジー 編集部

