

- AIがもっともらしく誤情報を生成する「ハルシネーション」は企業リスクに直結
- 原因は学習データの曖昧さ・文脈重視の設計・評価方法の問題
- 完全防止は困難なため、検証体制とAIリテラシー強化が重要
生成AIに潜む「ハルシネーション」というリスクをご存知でしょうか?
ハルシネーションとは、AIがもっともらしく虚偽の情報を出力してしまう現象のことです。なんと企業が訴訟される問題にまで発展しています。
また、訴訟に至らなくても、ハルシネーションを理解せずにAIを利用し続けると、企業や個人の信頼を損なうおそれがあります。
今回の記事では、こうした最新動向を踏まえながら、ハルシネーションの概要や原因、対策方法、検知する方法について詳しく解説します。この記事を最後まで読めば、ハルシネーションの仕組みと対策を深く理解し、安全に生成AIを活用できるようになるでしょう。
\生成AIを活用して業務プロセスを自動化/
ハルシネーションとは
ハルシネーションとは、AIが事実に基づかない情報を、もっともらしく生成してしまう現象を指します。本来は「幻覚」という意味の言葉ですが、生成AIがまるで幻を見ているかのように誤った情報を出力するため、この名称が使われています。
この現象は特に大規模言語モデル(LLM)によるテキスト生成や、画像生成AIにおいて顕著です。たとえば、存在しない論文を引用したり、歴史上存在しない出来事を語ったり、画像に実在しない人物やオブジェクトを描き出すことがあります。
ハルシネーションは単なる誤答にとどまらず、ビジネスや教育、医療などでの利用は深刻なリスクに直結しかねません。実際に、誤情報の拡散や名誉毀損、意思決定の誤りに発展した事例も報告されています。
そのため、生成AIを利用する際には「AIの出力は常に正しいとは限らない」という前提を持ち、受け取る側が確認・検証する姿勢が重要です。
さらに、2025年9月にOpenAIが発表した最新の論文では、GPT-5においてもハルシネーションを完全に防ぐことは困難であると明らかにされました。※5
原因としては、学習データの曖昧さ、「次の単語を予測する」という仕組み、現行の評価方法が誤出力を助長している点が挙げられます。解決策としては、評価指標を見直し、不正解にはペナルティを課す一方で「わかりません」といった不確実性を表明する回答に部分点を与えるなど、モデルが誠実に振る舞える仕組みが提案されています。
なお、その他の生成AIのリスクと対策方法について詳しく知りたい方は、下記の記事を合わせてご確認ください。

ハルシネーションの種類
AIのハルシネーションには、異なるタイプがあり、それぞれが異なる形で誤った情報を生成する仕組みを持っています。主なハルシネーションの種類には、以下のようなものがあります。
事実ハルシネーション
AIが実際には存在しない情報を事実として提示する現象です。例えば、歴史的な人物やイベントについての質問に対して、実在しない出来事や架空の人物を作り出すことがあります。
これは、モデルが学習データから誤った関連付けを行い、信憑性のない情報を生成することが原因です。
文脈ハルシネーション
質問の意図や前後の流れを誤って解釈し、文脈にそぐわない回答を返す現象です。たとえば「AIの医療利用」に関する質問に対して、「画像生成AIの活用事例」など別の分野の回答をしてしまう場合があります。これは、ユーザーの意図を正しく把握できず、関連性の低い知識を結びつけてしまうことが原因です。
構造ハルシネーション
正しい質問に対しても、AIが誤った構造やフォーマットで回答を生成する現象です。例えば、リスト形式で答えるべき質問に対して、AIが段落形式で応答したり、期待される数値やデータをテキストの形で提供してしまう場合です。
これは、AIが適切な回答形式を誤認した場合に発生します。
創造的ハルシネーション
完全に架空の情報や新しい概念をAIが生成する現象です。たとえば、科学的な質問に対して、現実に存在しない理論や用語を作り出すことがあります。
これは、AIが「創造的」な思考を行う際に事実を無視して、独自の回答を生成することにより生じます。


ハルシネーションが原因で訴訟になった事例
実は、ハルシネーションが原因で訴訟にまで発展した事例が存在します。特にChatGPTを開発したOpenAIに関わる事例は、世界的に大きな注目を集めました。マーク・ウォルターズ氏の例
訴訟を起こしたのは、「アームド・アメリカ・ラジオ」というラジオ番組の司会者を行なっているマーク・ウォルターズ氏。こちらの男性が係争中の実際の訴訟について説明を求めたところ、「ウォルターズがセカンド・アメンドメント財団から資金をだまし取り、不法に自分のものにした」とありもしない事実を、なんと虚偽の告訴状まで作って回答されたとのことです。
マーク・ウォルターズ氏は詐欺や横領を働いていないので、名誉を毀損されたとして訴訟を起こしています。※1
スティーブン・シュワルツ氏の例
アメリカの弁護士スティーブン・シュワルツ氏は、クライアントの訴訟のためにChatGPTを使用して法的調査を行いました。シュワルツ弁護士は、ChatGPTが提供した6件の裁判例をもとに法廷での主張を展開しましたが、後にその裁判例が実在しないものであることが判明しました。
ChatGPTは実際には存在しない判決を捏造し、それらを本物の裁判例として引用したのです。このことで、シュワルツ弁護士と彼の法律事務所は裁判所から5,000ドルの罰金を科されることになりました。※2
他の事例と共通点
これらのケースはいずれも「事実ハルシネーション」に分類され、AIが実在しない事実を本物のように提示したことが原因です。近年は、教育現場や研究分野でも「存在しない論文を生成した」という類似トラブルが報告されており、法律分野に限らず幅広い領域でリスクが拡大しています。
ハルシネーションが起こる原因
ハルシネーションが起こるのは、主に以下の4点が原因として考えられています。
- 学習データの誤り
- 文脈を重視した回答
- 情報が古い
- 情報の推測
それぞれの原因を詳しく見ていきましょう。
学習データの誤り
AIは、インターネット上に存在する大量のデータを学習源としています。インターネット上には、不正確な情報も多く存在するので、これらを学習してしまった結果、ハルシネーションを起こしてしまうという仕組みです。
とくに、問題視されるのが、偏った見解やフィクションも学習の対象になるということです。誤った学習データを基に生成された情報は、もちろん誤った情報になるので注意しなければなりません。
文脈を重視した回答
AIは、情報の正確性よりも文脈を重視して回答を生成することがあります。これは、入力されたプロンプト(指示文)に対し、自然な形で回答しようとしているからです。
しかし、文章を最適化する過程で情報の内容が変化してしまうことがあるため、正確ではない情報が出力されます。
情報が古い
時代が変化することによって、昔の常識が現代では通用しないということがよくあります。最新の情報に関しては、AIの学習データに含まれていない可能性があるので、ハルシネーションが発生します。
GPT-3.5やGPT-4などのモデルには、それぞれ学習データを取得した最終日付、いわゆる「知識のカットオフ」があります。GPT-5 の主要モデルでは 2024年10月1日頃が知識のカットオフとされており、それ以降の出来事や最新研究は反映されていない可能性があります。
情報の推測
AIは、学習データを基に、推測した情報を出力することがあります。これは、ユーザーが求める情報を提供しようと、無理やり回答を生成してしまうためです。
推測で出力された情報は、あくまで予想に過ぎないので、正確な情報とはいえません。出力された文脈だけでは、推測で出力されていることを見極めにくい場合もあるので注意しましょう。
アルゴリズムの限界
大規模言語モデル(LLM)は、与えられた文脈に基づいて次に来る単語を予測するように設計されていますが、この予測が必ずしも事実に基づいていないことがあります。
特に外部のデータベースにアクセスせず、訓練データだけをもとに判断を行うため、誤った情報を生成することがあるのです。
また、LLMは大量のデータからパターンを学習するものの、データの偏りや不十分さによって間違った関連付けを行い、架空の事実や文脈を作り出すことが多いです。この設計上の限界が、AIが現実には存在しない情報を生成する要因となっています。
最新研究による指摘
OpenAIが2025年9月に公開した論文では、ハルシネーションが残る原因として「学習データの曖昧さ」に加え、「評価方法の問題」が挙げられました。現在の評価基準では「わからない」と答えると不利になるため、AIは不確実でも推測して答える傾向があります。※5
ハルシネーションの具体例
ここでは、実際にChatGPT-3.5(無料版)を使用して、どのようにハルシネーションが起きるのかを紹介します。ハルシネーションは、事実ではないことを本当のことのかのように出力するため注意が必要です。以下を参考に、ハルシネーションがどのように起きるかを参考にしてください。
架空のアニメに関する質問
架空のアニメ「綺麗なクレヨンしんちゃん」について聞いてみました。
ChatGPTの回答はこちらです。
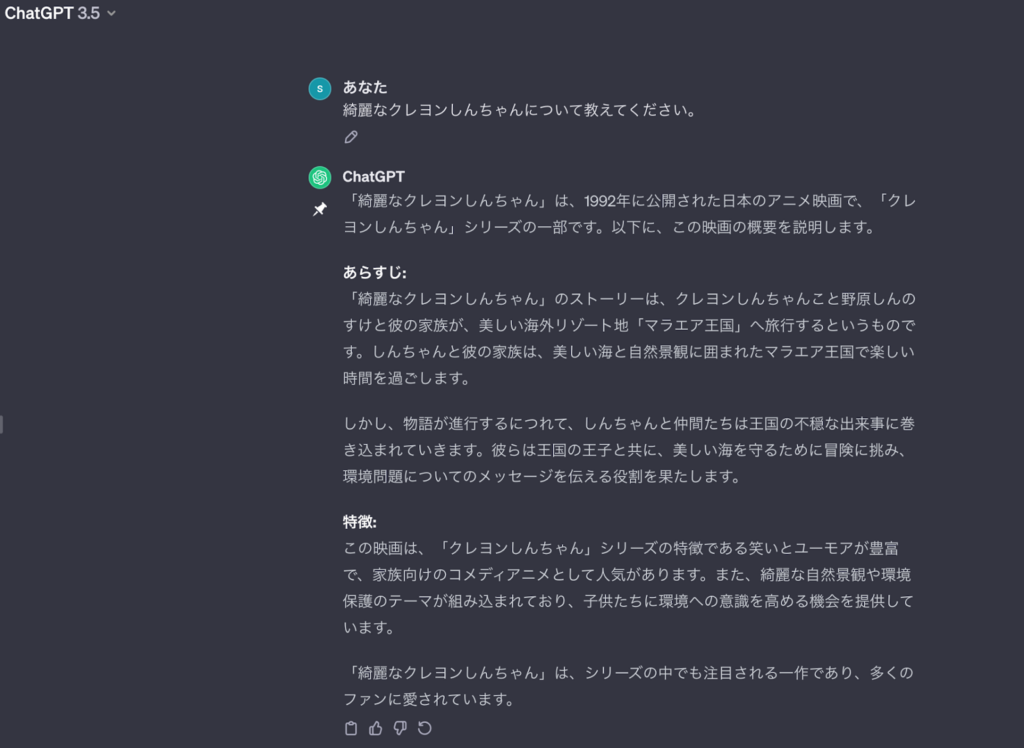
本当にこの映画が公開されているのか調べると、1992年にクレヨンしんちゃんはテレビアニメの放送が開始されていました!そして、1993年に最初の映画が公開されました。そのため、1992年に公開された「綺麗なクレヨンしんちゃん」という映画はありません。
しかし、ChatGPTは「綺麗なクレヨンしんちゃん」についてあらすじから特徴まで詳しく説明しています。ここまで具体的に出力されていると、騙されてしまいそうですね。
湖に関する質問
「日本で2番目に大きい湖」について聞きました。
回答はこちらです。

まさかの「琵琶湖」が2番目に大きい湖として出力されました。日本で1番目に大きい湖は「琵琶湖」です。そのため、ChatGPTは間違った情報を出力しています。
2番目に大きい湖で「琵琶湖」が出たので、1番目に大きい湖も聞いたところ「琵琶湖」が出力されました。これでは、ChatGPTが出力する情報を信用することは危険ですね。
地理に関する質問
「日本で2番目に広い都道府県」について聞きました。

ChatGPTは、2番目に広い都道府県は「青森県」と出力しました。実際に調べたところ、2番目に広い都道府県は「岩手県」でした!ChatGPTが回答した「青森県」は、8番目に広い都道府県です。
ついでに、1番広い都道府県を聞いたところ「北海道」と回答し正しい情報でした。ChatGPTは、間違った情報を出力したり、正しい情報を出力したり全ての情報を信じることはできませんね。
歴史上の人物についての質問
歴史上の人物「加藤清正」について聞きました。
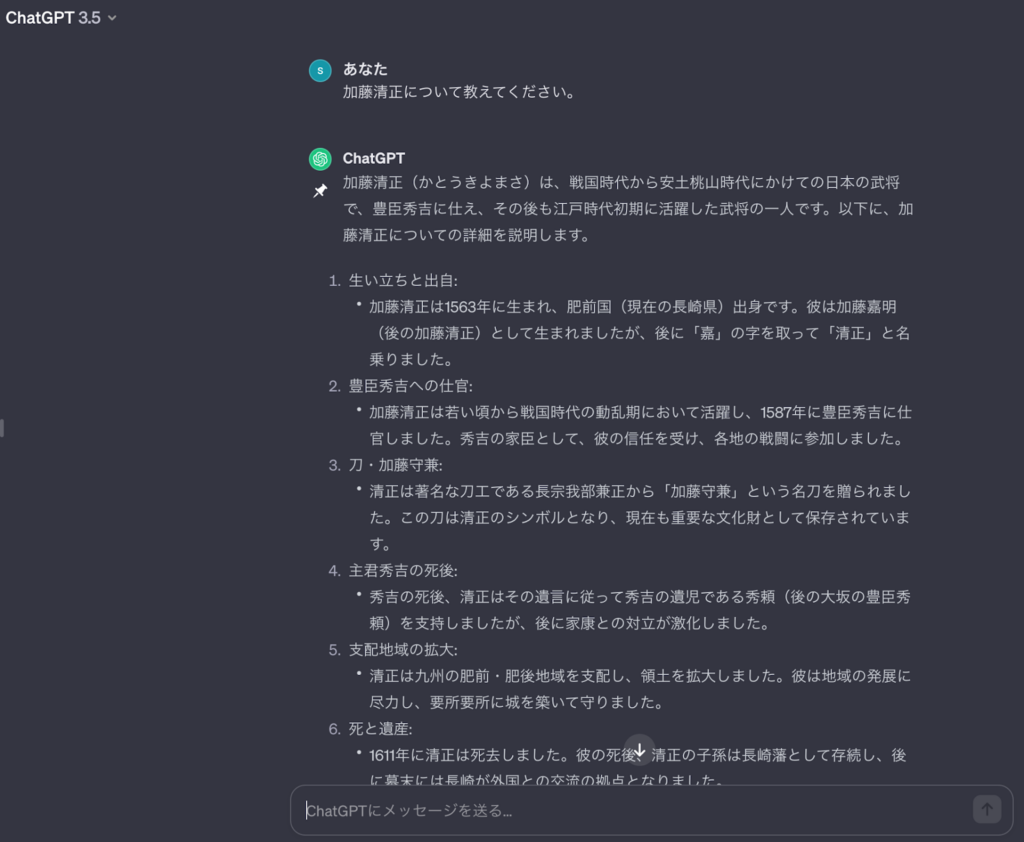
加藤清正の生涯について詳しく出力されていますが、間違った情報が出力されています。加藤清正は1563年生まれではなく、1562年生まれです。また、肥前国(現在の長崎県)出身ではなく、尾張中村(現在の愛知県名古屋市)出身です。
しかし、全て間違っている情報ではなく、1611年に加藤清正は亡くなっています。
架空の戦いについての質問
実際に存在しない「御所浦の戦い」について聞きました。
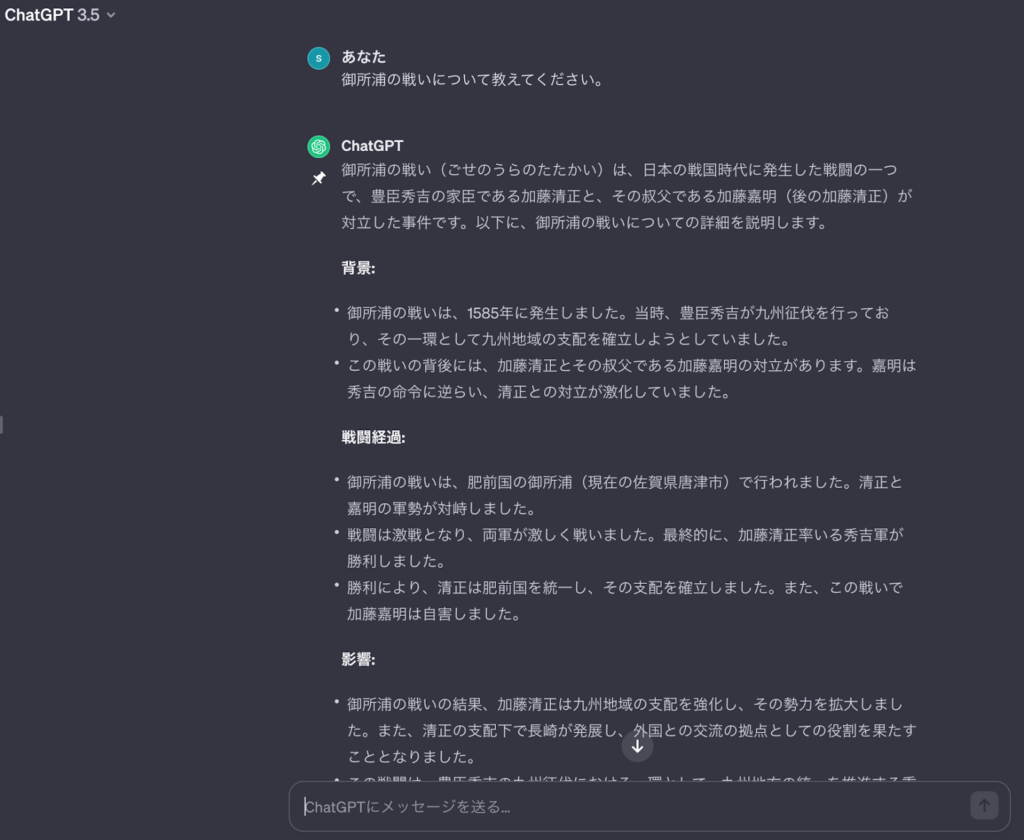
存在しない戦いなのに、詳しく説明されています。加藤清正について聞いた時に出力されていた「肥前国」がまた出力されています。しかも、今回は佐賀県の唐津市と回答しています。
先ほどの回答では、長崎県と出力していたのに嘘の情報です。ハルシネーションは、このような形で出力されるので必ず正しい情報か確認することが重要です。
ハルシネーションが起きやすい質問の仕方
生成AIは万能ではなく、質問の仕方によって誤情報を出力する確率が高まります。特に以下のようなケースでは、ハルシネーションが発生しやすいので注意が必要です。
プロンプトに嘘の情報が入っている場合
| 原因 | AIは入力を事実確認せずに「前提」として扱うため |
|---|---|
| 対策 | この人物や理論は実在しますか?」と存在確認を先に促すと誤りを減らせる |
質問文に存在しない人物名や研究名を含めると、AIはそれを前提に回答を作り出します。例えば「○○大学の△△教授が提唱した理論を教えて」といった質問をすると、実在しない教授や理論をもっともらしく説明してしまうことがあります。
架空のことに関する質問
| 原因 | 事実が存在しない場合でも「整合性のある物語」を優先する設計になっているため |
|---|---|
| 対策 | 「存在しない場合は存在しないと答えて」とプロンプトで明示する |
存在しないアニメや歴史的な出来事を聞いても、AIは想像であらすじや背景を生成してしまいます。
先ほどの「綺麗なクレヨンしんちゃん」や「御所浦の戦い」の例が典型で、詳細な設定まで作られてしまうため、本当らしく見える点がリスクです。
歴史や時事問題に関する質問
| 原因 | 知識のカットオフ(学習範囲の限界)+曖昧な記憶の補完がある |
|---|---|
| 対策 | 最新の情報は公式サイトや一次ソースで必ず確認 |
歴史上の人物の生年月日や出身地などは、微妙に誤った情報が出やすい分野です。また、時事問題ではAIの学習データに限界があるため、古い情報を最新のように答えることがあります。
ハルシネーションを防ぐための質問のコツ
ハルシネーションのリスクを減らすには、質問の工夫も重要です。
- 存在確認を最初に指示する(「存在するかどうか教えて」)
- 出典やURLを一緒に提示するよう要求する
- 年代や数値は「表形式で」「根拠付きで」と指定する
- 「わからない場合はその旨を答えて」と条件を加える
これらを組み合わせることで、AIが無理に答えを作らず、不確実性を表明するよう誘導できます。
なお、リスクを避けるために身に付けるべきAIリテラシーについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

生成AIを社内で利用する際のハルシネーション対策
生成AIを社内で利用する際は、ハルシネーション対策を事前に講じておくことが大切です。具体的には、以下6つの対策を行いましょう。
- アルゴリズムの改善
- データ品質の向上
- 偽情報や不正確な情報を回答することを念頭におく
- ガイドラインを作成する
- 回答結果の確認プロセスを構築する
- Gemini(旧Google Bard)を利用する
それぞれ具体的な対策を以下で解説していくので、ぜひ参考にしてみてください。
アルゴリズムの改善
生成AIの出力精度を高めるには、モデルそのものの設計改善が不可欠です。
- 強化学習(RLHF)による人間からのフィードバック
- より高度なアテンションメカニズムの導入
- 外部知識を取り込む「RAG(検索拡張生成)」
これらにより、文脈理解の精度を高め、誤推論を減らすことが可能になります。
データ品質の向上
AIの精度は学習データの質に直結します。
- 信頼できる一次情報に基づくデータセットを利用
- 誤情報やノイズを除外
- 偏りを防ぐために多様なソースをバランスよく収集
こうした工夫により、生成結果の信頼性が大きく向上します。
偽情報や不正確な情報を回答することを念頭におく
まずは、AIが偽情報や不正確な情報を回答する可能性があることを念頭におきましょう。あらかじめ予測ができていれば、ハルシネーションによる被害を防ぐことができます。
とくに危険なのが、「AIが出力する情報はすべて正しい」という思い込みです。文脈が整理されており、どこか説得力のある文章に見えてしまいますが、まずは疑うところから始めてみてください。
ガイドラインを作成する
社内で生成AIを利用する際のルールや注意点をまとめたガイドラインを作成し、従業員に周知しましょう。
- メールや社内ポータルで配布
- ポスターや研修での啓蒙
- 行政機関(文部科学省・総務省)が公表しているAI利用ガイドラインの参照
組織全体で共通認識を持つことが、リスク低減の第一歩です。
また、文部科学省や総務省など行政機関からも生成AIの取り扱いに関するガイドラインが発表されています。そちらを活用するのも有効な対策となります。※3
回答結果の確認プロセスを構築する
生成AIで情報を出力した後は、必ず回答された情報の整合性をチェックすることが大切です。毎回確認するようにプロセスを構築しておけば、自然とハルシネーションによる被害が減っていきます。
情報の正誤を判断する際は、以下を参照するのがおすすめです。
- 公的機関や行政のサイト
- 専門家が運営しているサイト
- 企業のサイト
- 新聞記事
- 論文や学術記事
基本的には、信頼できる1次情報から内容を確認し、AIが出力された情報が事実に基づいていることを確かめましょう。
Gemini(旧Google Bard)を利用する
Gemini(旧Google Bard)が2023年9月のアップデートで、「ダブルチェック」という機能を実装しました。これは、生成した内容をGoogle検索し、生成した文章のどの部分が正しい情報で、どの部分がAIによるハルシネーションなのかを識別できる機能です。
これにより、AIによる生成内容をAI自身が検知できるようになりました。


生成AIを開発する際のハルシネーション対策
生成AIを自社で開発する際もハルシネーション対策を行う必要があります。有効な対策法を以下にまとめました。
- 学習データの質の向上
- 出力の結果にフィルターをかける
- RLHF
- グラウンディング
以下でそれぞれ、詳しい対策方法を解説していきますね!
学習データの質の向上
AIは学習データに依存して知識を獲得するため、データ品質が低ければ誤情報もそのまま出力されてしまいます。
- 誤情報やノイズを極力排除したデータセットを構築する
- 偏りを防ぐために多様な分野・信頼できるソースを取り入れる
- 継続的に最新情報をアップデートする仕組みを導入する
ただし、大量データの検証には膨大な労力が必要で、完全に誤情報を排除することは困難です。
出力の結果にフィルターをかける
モデルが生成したテキストに対し、外部システムで誤情報や不正確な記述を除去・修正する仕組みを導入します。
- 単純な禁止ワードフィルター
- ファクトチェックAPIや検索エンジンとの連携
- リスクの高い領域(医療・法律・金融)に限定した制御
ただし、AI自身は事実判断が苦手なため、フィルターも補助的対策に留まります。
RLHF
RLHFは、Reinforcement Learning from Human Feedbackの略です。「人間のフィードバックからの強化学習」という意味の通り、人間の価値基準に合うように言語モデルをチューニングすることを指しています。
OpenAIのInstructGPTやChatGPTにもこの手法が取り入れられており、同社がリリースしていたGPT-3と比較して、大幅にハルシネーションの発生を抑えることに成功しています。※4
グラウンディング
グラウンディングとは、AIを活用するユーザーが指定した情報源だけに基づいて、AIに回答を生成させることを指しています。
通常は、AIが事前に学習した大量のデータに基づいて回答を生成しますが、グラウンディングでは事前に学習した情報は使いません。そのため、誤った情報を学習した結果、ハルシネーションが起きるというリスクを軽減できるというわけです。
GoogleCloudが提供している「Vertex AI Search and Conversation」では、すでにグラウンディングをAIチャットボットに実装する仕組みが搭載されています。
なお、ChatGPTを企業利用するリスクと対策方法について詳しく知りたい方は、下記の記事を合わせてご確認ください。

生成AIを開発する際にハルシネーションを防ぐためには
生成AIを自社開発する際にハルシネーションを抑えるためには、モデルの学習方法や生成過程に対策を組み込むことが重要です。代表的な方法として、以下のアプローチが有効です。
エンベディング(Embeddings)の活用
エンベディングとは、テキストを数値ベクトルに変換し、意味的な類似度を検索できるようにする仕組みです。
- 独自のドメインデータをベクトルデータベースに格納
- ユーザーの質問と類似度の高いデータを検索し、生成の根拠として活用
これにより、学習時点の知識だけに依存せず、常に最新かつ正確な社内データに基づいた回答 が可能になります。
学習データの精査と拡張
事前学習の段階で誤情報やノイズを含まないようにデータを取捨選択することが基本です。
- データソースの信頼性を確認
- 偏りを抑えるために多角的な情報を収集
- 定期的にアップデートして最新情報を反映
これにより「古い情報」や「誤学習」が原因のハルシネーションを軽減できます。
アルゴリズム改善(強化学習の導入)
AIの出力に対して人間が評価を行い、正しい回答に報酬を与える RLHF(Reinforcement Learning from Human Feedback) を組み込むことで、誤情報の生成を減らすことが可能です。
また、ドメイン固有のルールや制約を生成過程に反映させることで、業務要件に即した回答を得やすくなります。
グラウンディング(Grounding)の実装
グラウンディングは、AIが回答を生成する際に外部の信頼できるデータソースのみを参照させる仕組みです。
- FAQデータベースや社内ナレッジベースを指定
- 公的データや公式サイトのみを根拠として利用
Google Cloudの「Vertex AI Search and Conversation」など、実際にグラウンディングを導入できるサービスも登場しています。これにより「存在しない情報の捏造」を防止しやすくなります。
ハルシネーションの完全な対策は困難
ハルシネーションは、企業や個人の信頼を一瞬で損なう可能性がある深刻な課題です。しかし、生成AIの仕組みそのものに起因するため、完全に防止することは現状の技術では不可能といわれています。
OpenAIが2025年9月に発表した最新の研究でも、GPT-5を含む大規模言語モデルでは、学習データの曖昧さや自己予測に依存する仕組みから、ハルシネーションをゼロにするのは難しいです。評価基準そのものが「不確実でも回答することを促す設計」になっている点も、根本的な要因とされています。※5
そのため、企業や個人が生成AIを利用する際は「ハルシネーションは一定確率で必ず起きる」という前提を持ち、リスクを低減する仕組みを導入することが重要です。
- 出力内容のファクトチェックを徹底する
- AIリテラシーを社内外で浸透させる
- ガイドラインやレビュー体制を整備する
こうした対策を重ねれば、ハルシネーションによる被害を最小限に抑えつつ、生成AIの利便性を活かせます。逆に、ハルシネーションがほぼ解消されれば、AIは人間に代わって膨大な情報収集・整理を担い、業務効率や知識活用が大きく進化するでしょう。
なお、ハルシネーションの問題を調査するために行われた研究結果について詳しく知りたい方は、下記の記事を合わせてご確認ください。

AIを使ったハルシネーション対策AIの開発
弊社では、ハルシネーション対策ができるAIの開発実績があります。
生成AIには、”ハルシネーション“という「嘘の情報を本当のことのように話す」振る舞いが問題視されています。
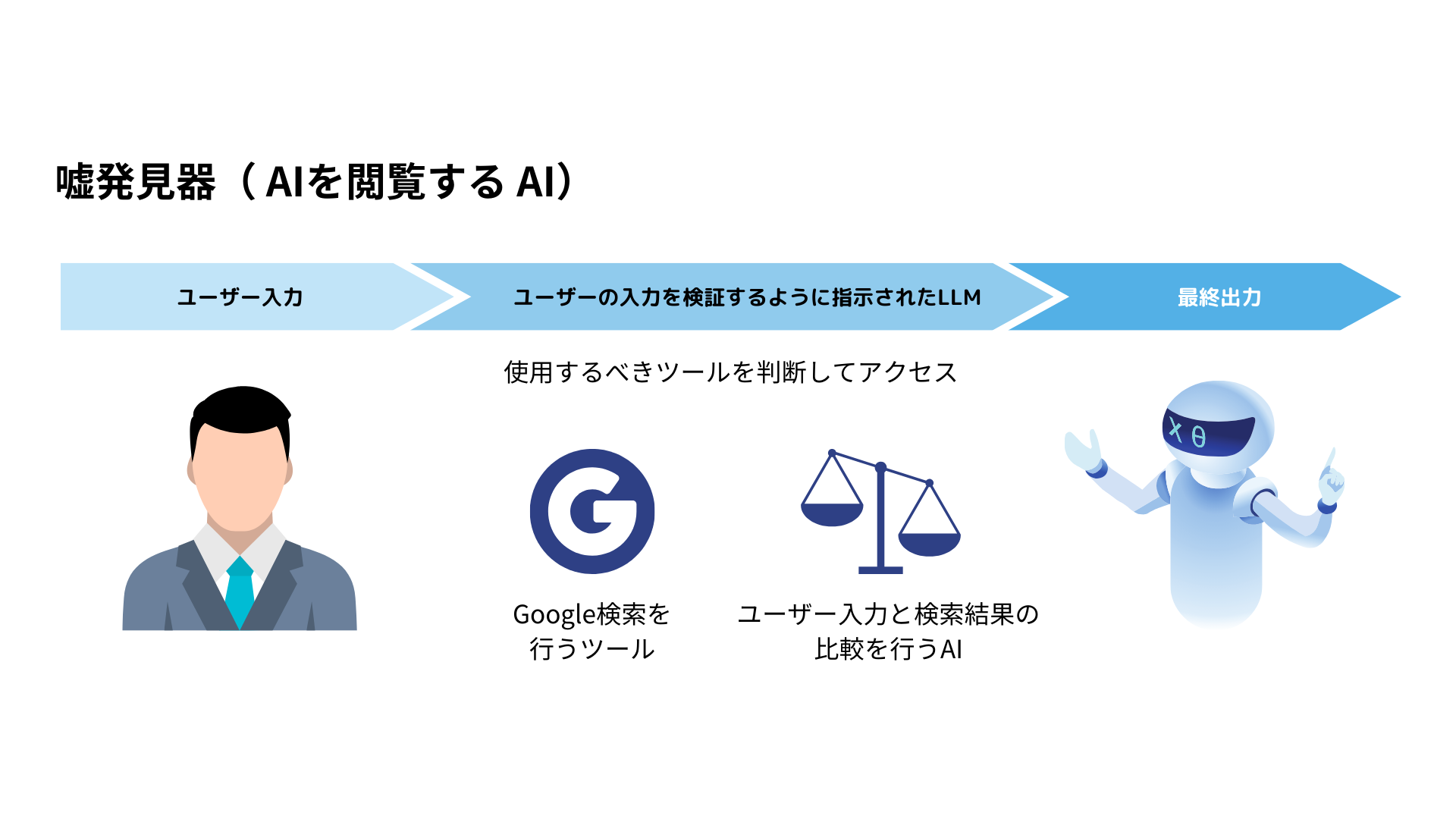
弊社では、様々な手法でこの問題の対処に取り組んでいますが、1つの手法として「AIを検閲するAI」の開発を行っています。
この例では、AIが生成した回答が正しいのかどうか、Google検索などので取得したデータソースにアクセスし、本当の情報であるかどうか検証しています。
他にも、論文データベースや自社の正しい情報のみが載っているデータにアクセスすることで、より高度な検閲機能の実装が可能です。
AIを使ったハルシネーション対策AIの開発に興味がある方には、まずは1時間の無料相談をご用意しております。
こちらからご連絡ください。
ハルシネーションリスクを抑えて生成AIで業務を効率化しよう
ハルシネーションとは、AIが虚偽の情報をもっともらしい形で生成してしまう現象のことです。ハルシネーションが起こる原因をまとめました。
- 学習データの誤り
- 文脈を重視した回答
- 情報が古い
- 情報の推測
AIは、インターネット上に存在する大量のデータを学習源としています。インターネット上には、誤った情報が数多く存在するので、それらを学習してしまうことで虚偽の情報が生成されてしまうというわけです。
技術的な工夫を組み合わせれば、ハルシネーションの発生を大幅に抑制できます。完全防止は難しいものの、利用者のリテラシーと開発者の設計努力によって、リスクを最小限に抑えることが可能です。自社で取り得る最大限の対策を講じることで、生成AIは業務効率化や知識共有に大きく貢献します。ハルシネーションを正しく理解し、リスクを管理しながら積極的に活用していきましょう。

最後に
いかがだったでしょうか?
生成AIの導入は、正しいリスク理解と運用設計が鍵です。自社の業務に最適なAI活用戦略を構築し、ハルシネーションを防ぎながら生産性を最大化する方法を紹介します。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。 ︎株式会社WEELのサービスを詳しく見る。
︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

【監修者】田村 洋樹
株式会社WEELの代表取締役として、AI導入支援や生成AIを活用した業務改革を中心に、アドバイザリー・プロジェクトマネジメント・講演活動など多面的な立場で企業を支援している。
これまでに累計25社以上のAIアドバイザリーを担当し、企業向けセミナーや大学講義を通じて、のべ10,000人を超える受講者に対して実践的な知見を提供。上場企業や国立大学などでの登壇実績も多く、日本HP主催「HP Future Ready AI Conference 2024」や、インテル主催「Intel Connection Japan 2024」など、業界を代表するカンファレンスにも登壇している。

