Google DeepMindが開発した「Dreamer」と呼ばれる新しい強化学習アルゴリズムによって、想像力に似た力を持つAIがマインクラフトでダイヤの採掘を行うことに成功しました。
これまでの技術でもオープンワールドゲームの世界で特定の目的を持って動き回るAIは存在していましたが、新たなAIは全てを人間の助けなしに0から学び、自分の力だけで探検や採掘、そしてクラフトを行いダイヤを獲得するのです。
「AIなんだからそれくらいできるでしょ?」と思うかもしれません。
しかしマインクラフトでダイヤを採取するには現実でダイヤを掘るのと同じく数多くの過程を消化しなければならず、また生存し続けるには危機を予測し回避することも必要になります。
そのような全てを統合し合理的に作業を行うことはこれまでのAIでは困難でした。
研究者たちはマインクラフトという仮想世界での成功は現実世界での「何でもこなすAI」の登場において重要なステップになると述べています。
普通なら挫折しかねない課題を「AIだけでやり遂げた」と聞くと、未来のロボットや自律システムの可能性さえ感じさせます。
いったいどのような仕組みが、この“大冒険”を支えているのでしょうか?
研究内容の詳細は『Nature』にて発表されました。
目次
- AIがオープンワールドで遊ぶとは何を意味するか?
- AIが想像力を働かせてマインクラフトでダイヤを掘る
- 世界を理解するAIの行く先
AIがオープンワールドで遊ぶとは何を意味するか?

強化学習という言葉を聞くと、難しそうな数式や専門的なアルゴリズムを連想するかもしれません。
しかしその本質は、まるで子どもが自転車に乗れるようになるまで何度も転んでは起き上がるように、「トライ&エラーを繰り返して少しずつ学習する」という仕組みです。
最初は失敗ばかりでも、成功に近づくたびに「ご褒美」を受け取り、そのご褒美を最大化しようと行動を改良していく──そんなシンプルなイメージが強化学習の原点です。
ところが、実際には大きな壁がありました。
多くの強化学習システムは「ゲームや環境によって細かいパラメータを変えないと、まともに学習できない」ことがしばしば起こります。
たとえば、難易度が高いゲームでは報酬を少し増やし、反対に報酬が簡単に取れすぎるゲームでは少し減らす、といった具合です。
これはちょうど、服のサイズが合わないたびに仕立て直しを繰り返しているようなもので、煩わしさが拭えません。
もし「着る人を選ばないフリーサイズのスーツ」が手に入るなら、そのほうが手間もかからず便利でしょう。
強化学習の研究コミュニティでは、こうした“調整なしでも多様なタスクをこなせるAI”を目指すアプローチが何年も議論されてきました。
そんな流れのなかでも、“マインクラフト”はとりわけ難しく、しかも魅力的な実験台です。
一言でいえば、“巨大な砂場”のような世界が広がっていて、プレイヤーはいろんなものを作れますし、どこへでも行けます。
資源を集め、道具を作り、道具を使ってさらに新しいものを作る、という果てしないサイクルが続きます。
自由度が高いぶん、「何から手をつけるかすら分からない」という問題も出てきます。
ゲーム上級者は攻略サイトで知識を仕入れたり、先人のミスを学んだりしながら少しずつ上手くなるのですが、それをAIがいきなり全部ひとりでやれと言われたら、相当骨が折れるのは容易に想像できます。
中でも“ダイヤモンドの入手”は多くのプレイヤーが「ひと苦労した」と口をそろえるハードルで、人間にとってもやり込み甲斐のある大目標です。
実際、これまでの研究では「AIがマインクラフトを上手にプレイする」ためには、人間が事前に教えるステップが不可欠なケースが大半でした。
たとえば、「まずは木を切り、それを使って道具を作り……」といった手順を人間のプレイデータから学ばせるとか、難易度を段階的に設定するカリキュラムを用意してあげるとか。
これは確かに効果的ですが、一方で「AIが本当にゼロから自力で学習しきった」とは言い難いのも事実です。
もし何の助けもなく、ただ試行錯誤するだけでダイヤモンドまでたどり着けるなら、それは「地図のない広大な島に放り出されても、AIがサバイバル術を自前で身につけられる」ということを意味します。
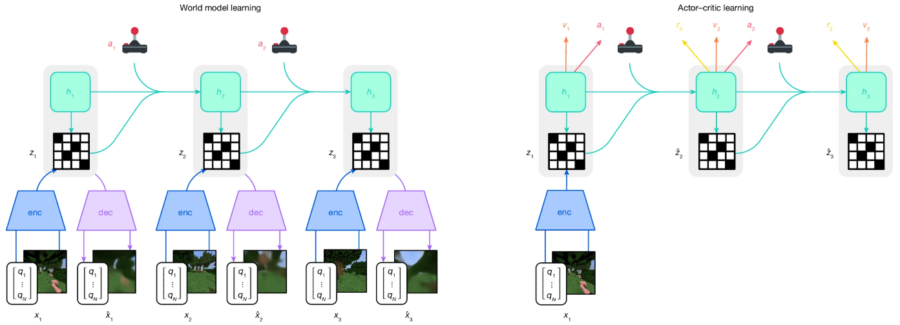
そこで重要になってくるのが、「世界モデル(World Model)」という考え方です。
AIが想像力を働かせてマインクラフトでダイヤを掘る
新たな研究は「世界モデル(World Model)」という概念をAIに用います。
これは「AIが頭の中に仮想的な環境を丸ごと構築し、その中で未来を予測して練習を繰り返す」という仕組みです。
まずAIは大量のデータを使って、現実世界やゲーム内の状況を抽象的に理解する「世界モデル」という内部の地図を作り上げます。
この世界モデルは、実際のマインクラフトの世界をまるで縮小版のシミュレーションとして再現しているようなものです。
AIは、この内部モデル上で、さまざまな行動を試し、その結果としてどんな状態になり、どれだけの報酬(ゲーム内ではたとえばダイヤモンドなどの貴重な資源)が得られるかを計算します。
言い換えれば、AIは自分の中で「もしこう動いたらどうなるだろう?」と無数の未来のシナリオを瞬時に描き、その中から最も良い結果が得られると予測される行動を選び出しているのです。
この一連のプロセスは、まるでチェスのプレイヤーが次の一手を考える時に、頭の中で何手先までシミュレーションするのと似ています。
たとえば囲碁の名手や将棋のプロが、いちいち盤を動かさなくても何手も先の展開を脳内シミュレーションして次の一手を導き出すように、AI自身が“頭の中のマインクラフト世界”を走らせて試してみるのです。
ある意味で人間のように世界を「理解」し「想像」を行っていると言えるかもしれません。
AIには心がなく純粋に計算によって将来を思い描いているだけですが、人間だって未来の想像に常に心情を伴っているわけではないでしょう。

研究では、AIの学習を進めるにあたり大きく分けて二つの手法がとられました。
まず一つ目は、「AIが多種多様なタスクにどの程度対応できるか」を確かめるための検証です。
具体的には、Atariゲームやロボット制御タスク、3D迷路、そしてマインクラフトなど、150を超える異なる環境を用意し、そのすべてで同じアルゴリズムを動かして性能を測定しました。
通常であれば、環境ごとにパラメータを入念に調整したり、特別な追加データを与えたりする必要があります。
しかしこの研究では、ほぼ固定の設定で一通り学習を行うという大胆な方法を選んだのです。
結果として、従来は「これ専用の手法でなければうまくいかない」と思われていたタスクでも、新しいAIアルゴリズム「Dreamer」が十分以上の成績を示すケースが多く見つかりました。
たとえば、あるタスクでは動作制御に特化した以前のアルゴリズムと同等かそれ以上の得点をマークし、また別のタスクでは画像を扱うゲーム環境でも高い適応力を示しました。
「ひとつのAIがさまざまな領域でそれなりにうまく立ち回れる」という事実は、これまでの“特化型AI”の常識を覆す重要な一歩といえるでしょう。
二つ目の柱として、とりわけ注目を集めたのが「マインクラフト」を舞台にした実験です。
ご存じの方も多いかもしれませんが、マインクラフトはプレイするたびにワールド(地形や資源配置)が自動生成されます。
つまり、一度うまくいった方法が必ずしも次回も通用するとは限りません。
しかも、最終的な目標のひとつであるダイヤモンドは地下深くにあって、「何をどう掘ればたどりつけるか」がさっぱりわからない状態からのスタートです。
そこで研究チームは、より挑戦的な条件として、人間のプレイデータや攻略のヒントをまったく与えない方式を選びました。
要するに、AIは文字どおり手探りの状態で行動し、あらゆる過程を自分で学んでいかなければならなかったのです。
その結果は、驚くほど画期的なものでした。
AIは最初、どうやって木を切るのかさえ分からない様子でしたが、試行錯誤を重ねるうちに少しずつ合理的な行動をとるようになります。
やがて自分で道具をクラフトし、地下を効率よく探索する方法を学習し、ついにはダイヤモンドの入手にまでこぎつけました。
さらに注目すべきは、同じ条件で繰り返し実験してもダイヤモンドの収集が再現性をもって確認されたという点です。
これは単なる“偶然の成功”ではなく、AIが「どのように動けば目的に近づくか」をしっかり理解し、応用している証拠と考えられます。
こうして「人間のプレイデータなしでダイヤモンド収集まで完了させた」という事実は、これまでの常識を覆すインパクトがあります。
なぜなら、従来の方法では大半の場合、攻略手順を段階的に教えたり、ゲームに合わせて専用のしくみを作ったりすることが“当たり前”でした。
つまり今回の成果は、AIの学習能力をより“純粋なかたち”で証明したといえます。
特定のゲームやタスクに合わせた特別な調整がなくても、幅広い環境で高いパフォーマンスを発揮できる。
それこそが、本研究の最大の革新点です。
これによって、「AIは自分の頭の中の仮想環境(世界モデル)を活用し、まるで何でもこなせる多才なアスリートのように成長できるのではないか」という期待が、現実のものに近づいたのです。
世界を理解するAIの行く先

今回の研究がもたらした最大のインパクトは、「AIが複雑な世界を自ら理解し、柔軟に行動を変えながら目的を達成できる」という点にあります。
たいていの強化学習システムは、特定のゲームやロボット操作に最適化されるよう作られており、別の環境に移ると“また一からチューニングし直し”になってしまうことがほとんどでした。
ところが、この研究で示されたアプローチは、一つの枠組みで多様なタスクや未知の状況を大きく包み込み、自在に学習を進めることができます。
たとえば、従来であれば「アーケードゲームの操作は得意だけれど、3D迷路はまるで歯が立たない」というケースが当たり前でした。
しかし今回の手法では、アーケードゲームも3D迷路もロボット制御も、さらにはマインクラフトのような自由度の高いサンドボックスゲームまで、ほぼ同じ仕組みで学習を進め、しかも実際に高いスコアや目標達成率を残せています。
これは例えるなら、“あらゆるスポーツをマルチにこなせる万能アスリート”のような存在が誕生しつつあるイメージです。
さらに興味深いのは、この研究の手法が人間のプレイデータや詳細な手取り足取りの指導を必要としないという事実です。
これは「まったく言葉を知らない赤ちゃんが、目の前の世界を試行錯誤で探検しながら言語や動作を学んでいく過程」にも近いかもしれません。
要するに、AIはゲームや実験環境の“真のルール”が何なのかを自ら推定し、どう行動すれば報酬(成果)が得られるかを段階的に見つけ出していくわけです。
この“自力で世界を把握する”力が大きく育てば、単にゲームを攻略するだけでなく、現実の様々な場面でも役立つ可能性が見えてきます。
たとえば、未知の作業現場や新しい機械を扱うロボットが、説明書なしでもすぐに方法を学び取り、最適な動きを見つけ出すことが夢ではなくなるでしょう。
もちろん、まだ課題も残っています。
世界モデルを大きくするほど学習にはより多くの計算資源が必要になりますし、“頭の中でシミュレーションしきれない”極端に複雑な環境に対しては、さらなる工夫も求められるはずです。
それでも、この研究が示した「複数のタスクやゲームを、“同じ設定”で攻略できるAI」の姿は、従来の“特化型AI”を超える新しい方向性を鮮明に打ち出しました。
これこそが今回の成果を革新的なものにしている理由です。
もし今後、さらに大規模なモデルや多種多様な学習データと組み合わせることができれば、AIは文字通り“なんでもできる”存在へと近づいていくかもしれません。
いわば、あらゆるスポーツ競技を制覇し、さらに新種目が追加されてもすぐに修得してしまうような驚異的アスリートが生まれる可能性があるのです。
こうした展望は、一見すると夢物語のように思えますが、すでに“マインクラフトでダイヤモンドを入手したAI”という具体的な成果があるだけに、決して荒唐無稽ではありません。
研究者たちは次の目的としてマインクラフトのボス的な存在と言える「エンダードラゴン」を倒すことを目指すと述べています。
現実の課題でも、同じように“世界を理解し、自律的に学び、応用し続けるAI”が大きな力を発揮するようになるでしょう。
たとえば工場の自動化、物流や輸送ルートの最適化、あるいは医療現場でのサポートまで、応用先は無数に広がっています。
本研究の一連の結果は「AIの汎用学習は可能なのか?」という長年の疑問に、一つの力強い“イエス”を示すものです。
しかも、その“イエス”をゲームの実績だけでなく、多彩なタスクで裏付けたという点が、今回の最も意義深いところだといえます。
元論文
Mastering diverse control tasks through world models
https://doi.org/10.1038/s41586-025-08744-2
ライター
川勝康弘: ナゾロジー副編集長。 大学で研究生活を送ること10年と少し。 小説家としての活動履歴あり。 専門は生物学ですが、量子力学・社会学・医学・薬学なども担当します。 日々の記事作成は可能な限り、一次資料たる論文を元にするよう心がけています。 夢は最新科学をまとめて小学生用に本にすること。
編集者
ナゾロジー 編集部

