

- ELYZAは東京大学発スタートアップによる日本語特化型LLMで、Llama 2をベースに開発
- 独自評価データセット「ELYZA-tasks-100」で日本語モデル中トップクラスの性能を記録
- GPT-4oには及ばないが、今後の大型モデル開発で性能向上が期待される
2023年8月29日に日本語版LLMの「ELYZA-japanese-Llama-2-7b」がリリースされました。
日々AIの最新情報にアンテナを張っている皆さんなら当然ご存知ですよね??
今回は、まだELYZA-japanese-Llama-2-7bを知らないという方のために、導入方法と実際に使ってみた様子を紹介します。「実際に使ってみた」パートでは、日本語検定一級を受験させてみたので、ぜひ最後までご覧ください!
\生成AIを活用して業務プロセスを自動化/
ELYZAとは?
東京大学・松尾研究室発のAIスタートアップのELYZA (イライザ) が日本語版大規模言語モデル「ELYZA-japanese-Llama-2-7b」をリリースしました。
リリースされたモデルは以下の4つです。
| モデル | 詳細 |
|---|---|
| ELYZA-japanese-Llama-2-7b | MetaのLlama-2-7b-chatに対して、約180億トークンの日本語テキストで追加事前学習を行ったモデルです。学習に用いたのは、OSCARやWikipedia等に含まれる日本語テキストデータです。 |
| ELYZA-japanese-Llama-2-7b-instruct | ユーザーからの指示に従い様々なタスクを解くことを目的として、ELYZA-japanese-Llama-2-7bに対して事後学習を行ったモデルです。 |
| ELYZA-japanese-Llama-2-7b-fast | Llama 2に日本語の語彙を追加して事前学習を行ったモデルです。 |
| ELYZA-japanese-Llama-2-7b-fast-instruct | ELYZA-japanese-Llama-2-7b-fastに対して事後学習を行ったモデルです。 |
このモデルはLlama-2-7b-chat-hfをベースとした70億パラメータの商用利用可能な日本語言語モデルです。
Llama-2-7b-chat-hfをベースにした理由は、SFT(Supervised Fine-Tuning)やRLHF(Reinforcement Learning with Human Feedback)が実施されているので、指示追従機能や出力の安全性が高いからです。
Llama 2は、超大規模な事前学習がなされており、優れた言語能力や知識を備えていることから、OSCARやWikipediaなどの日本語データを少量学習させるだけで、高性能な日本語LLMが開発できるというわけです!
ここで、いくつかのLLMと概要を比較してみましょう。
| ELYZA-japanese-Llama-2-7b-instruct | GPT4o | Llama 2 | Weblab-10b | |
|---|---|---|---|---|
| パラメーター数 | 7B | 不明 | 1.37T | 10B |
| 処理できるトークン数 | – | 不明 | 16,000(13,000文字) | – |
| 開発会社 | ELYZA | OpenAI | Meta | 東大松尾研究室 |
| 商用利用 | 可 | 可 | 可 | 可 |
| ライセンス | Llama 2 Community License | プロプライエタリソフトウェア | Llama 2 Community License | cc-by-nc-4.0 |
パラメータ数はLlama 2と比較するとやはり少なめでしょうか。
しかし、ELYZA-tasks-100という独自のモデル評価データセットで行ったテストでは、日本語モデルの中で最高水準を誇っています!
このデータセットには以下の特徴があります。
- 複雑な指示・タスクを含む100件の日本語データ
- 役に立つAIアシスタントとして、丁寧な出力が求められる
- 全てのデータに対して評価観点がアノテーションされており、評価の揺らぎを抑えることが期待される
一刻も早く使ってみたい!と思ったはず。ということで実際に導入していきましょう。
なお、その他の日本語LLMについて詳しく知りたい方は、以下の記事をご覧ください。

ELYZAの使い方
今回の実装ではgoogle colaboratoryを使用しました。
実装にはNVIDIAのGPUが必要です。今回はNVIDIA A100を使用しました。
LLMの使用にはLangChainを使用しています。
#環境構築
!pip install langchain-community langchain-core
!pip install transformers
from langchain import HuggingFacePipeline, PromptTemplate, LLMChain
from langchain.prompts import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
import torch
from transformers import LlamaForCausalLM, LlamaTokenizer次に、使用するモデル名の定義と実行するタスクの指定をします。
# 基本パラメータ
model_name = "elyza/ELYZA-japanese-Llama-2-7b-instruct"
task = "text-generation"GPU の確認をします。
# GPUの確認
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device
device(type='cuda')トークナイザとモデルの読み込み
# モデルのダウンロード
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name).to(device)テキスト生成のためのパイプラインをセットアップ
# LLMs: langchainで上記モデルを利用する
pipe = pipeline(
task,
model=model,
tokenizer=tokenizer,
device=0, # Number of GPU Device
framework='pt', # Use PyTorch
max_new_tokens=1024,
)
llm = HuggingFacePipeline(pipeline=pipe)これでモデルのダウンロード及びロードは完了です。早速プロンプトを入力して、実際に使っていきましょう!


ELYZAを実際に使ってみた
プロンプトテンプレートを作成します。
# Prompts: プロンプトを作成
template = "<s>[INST] <<SYS>>あなたはユーザの質問に回答する優秀なアシスタントです。
以下の質問に可能な限り丁寧に回答してください。 <</SYS>>\n\n{question}[/INST]"
prompt = PromptTemplate.from_template(template)プロンプトを入力します。
# Chains: llmを利用可能な状態にする
llm_chain = LLMChain(prompt=prompt, llm=llm, verbose=True)
question = "カレーライスとは何ですか?"
llm_chain.run({"question":question})出力結果

自然な日本語になっています。
導入が難しいという方は以下のデモからも使用できるので気軽に使ってみてください。
ELYZAの日本語能力を検証してみた
ELYZAは日本語特化型LLMなので日本語検定1級の問題を解かせてみます。他にもGPT-4o、Weblab-10bにも同じ問題を解かせて比較してみたいと思います。日本語検定一級に合格できるのはどのLLMでしょうか!
まず1問目として、以下の問題を解いてもらいました。
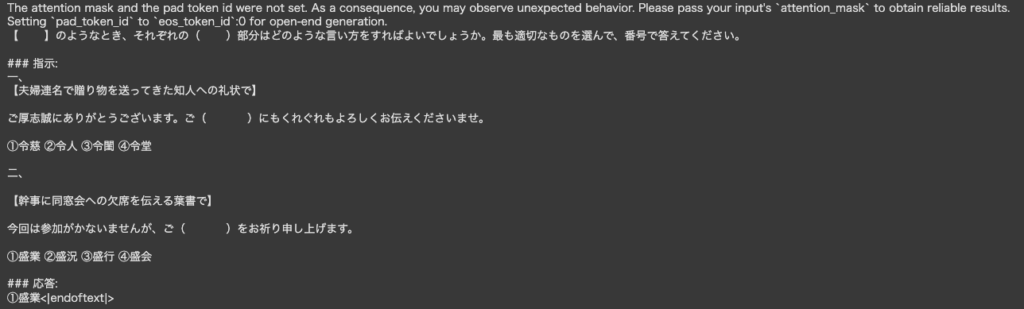
第1問
【 】のようなとき、それぞれの( )部分はどのような言い方をすればよいでしょうか。最も適切なものを選んで、番号で答えてください。
一、
【夫婦連名で贈り物を送ってきた知人への礼状で】
ご厚志誠にありがとうございます。ご( )にもくれぐれもよろしくお伝えくださいませ。
①令慈 ②令人 ③令閨 ④令堂
二、
【幹事に同窓会への欠席を伝える葉書で】
今回は参加がかないませんが、ご( )をお祈り申し上げます。
①盛業 ②盛況 ③盛行 ④盛会ちなみに、この問題の答えはそれぞれ以下の通りです。
答え
一、 ③令閨
二、 ④盛会では、順番に見ていきましょう。
ELYZA-japanese-Llama-2-7b-instructの回答

不正解…ですが、問題文は理解してくれているようです。
GPT-4oの回答

正解です!しっかりと解説もついていて、わかりやすいですね。
Weblab-10bの回答
こちらは不正解です。
これまでの結果を表にまとめてみました。
| 答え | ELYZA | GPT-4o | Weblab-10b | |
|---|---|---|---|---|
| 一 | ③ | × |  ︎ ︎ | × |
| 二 | ④ | × | ︎ | × |
問題が難しかったせいか、GPT-4o以外は不正解という結果になってしまいました…。Weblab-10bは回答しかありませんでしたが、ELYZAとGPT4oは問題文を理解して出力してくれていますね!
気を取り直して第2問にいきましょう!
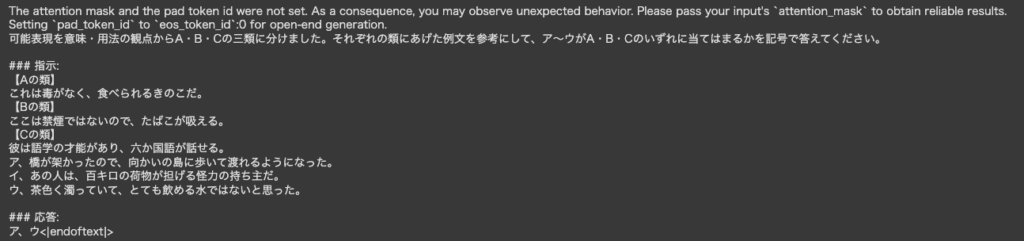
可能表現を意味・用法の観点からA・B・Cの三類に分けました。それぞれの類にあげた例文を参考にして、ア~ウがA・B・Cのいずれに当てはまるかを
記号で答えてください。
【Aの類】
これは毒がなく、食べられるきのこだ。
【Bの類】
ここは禁煙ではないので、たばこが吸える。
【Cの類】
彼は語学の才能があり、六か国語が話せる。
ア、橋が架かったので、向かいの島に歩いて渡れるようになった。
イ、あの人は、百キロの荷物が担げる怪力の持ち主だ。
ウ、茶色く濁っていて、とても飲める水ではないと思った。
答え
ア、 B
イ、 C
ウ、 AELYZA-japanese-Llama-2-7b-instructの回答

不正解ですね。
問題文を理解しているような感じで出力されましたが、よく読むとそれっぽい文章がならんでいるだけで、きちんと理解していないようでした。
GPT-4の回答

完璧ですね。言う事無しです!
Weblab-10bの答え
問題文が複雑すぎたのか、理解すらままなりませんでした。
結果は以下の通りです。
| 答え | ELYZA | GPT-4o | Weblab-10b | |
|---|---|---|---|---|
| ア | B | × | ︎ | × |
| イ | C | × | ︎ | × |
| ウ | A | × | ︎ | × |
GPT-4oの理解力がよく分かる結果になりました。ELYZAも文章を理解しようとしていることが出力結果から読み取れました。
続いて第3問です!
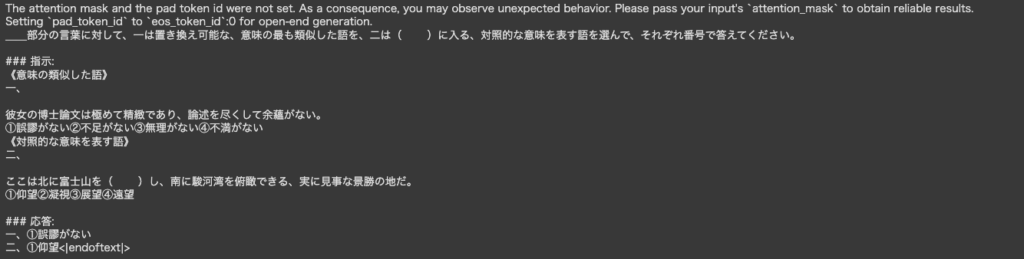
__部分の言葉に対して、一は置き換え可能な、意味の最も類似した語を、二は( )に入る、対照的な意味を表す語を選んで、それぞれ番号で答えてください。
《意味の類似した語》
一、
彼女の博士論文は極めて精緻であり、論述を尽くして余蘊がない。
①誤謬がない②不足がない③無理がない④不満がない
《対照的な意味を表す語》
二、
ここは北に富士山を( )し、南に駿河湾を俯瞰できる、実に見事な景勝の地だ。
①仰望 ②凝視 ③展望 ④遠望
答え
一、 ②不足がない
二、 ①仰望ELYZA-japanese-Llama-2-7b-instructの回答

こちらは少し難しかったせいか理解すらできていないようです。
GPT-4oの回答

正解です!すごいですね!
Weblab-10bの回答
こちらは不正解ですが、問題文は理解してくれています。
| 答え | ELYZA | GPT-4o | Weblab-10b | |
|---|---|---|---|---|
| 一 | ② | × | ︎ | × |
| 二 | ① | × | ︎ | × |
結果、GPT-4oのみ全問となりました!
さすが、GPT-4oといったところでしたが、ELYZAも問題を理解しようとしていることも見て取れたので、今後に期待です!
なお、今回比較対象にしたWeblab-10bについて詳しく知りたい方は、以下の記事をご覧ください。

ELYZAのこれからに期待!
ELYZA-japanese-Llama-2-7bは、ELYZA社がLlama2-7bをベースに開発した日本語大規模言語モデルで、Llama2の言語能力や知識を引き継ぐことで、少ない学習量で、高い日本語性能を獲得しました。
このモデルは、ELYZA-tasks-100という独自の評価データセットを使った評価で、日本語特化モデルの中では、最高水準の評価を得ています。
ただ、実際の日本語能力を検証してみた結果、日本語検定一級クラスの難しい問題は理解することができず、GPT-4oに比べ、日本語能力は劣る結果になりました。
現在、130億と700億パラメータのモデルの開発に着手しており、これらのモデルではさらに性能の向上が期待されるので、公開され次第また比較検証を行います!
期待して待ちましょう!

最後に
いかがだったでしょうか?
日本語特化LLMを自社業務に応用すれば、企画やサポートの生産性を飛躍的に向上できます。導入の最適解を一緒に見つけましょう。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。 ︎株式会社WEELのサービスを詳しく見る。
︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。
