

- GPTBotとは、ChatGPTの学習に必要なクローラー
- GPTBotに自社サイトをクローリングさせない方法がある
- ChatGPTに入力した情報を学習させないことで情報漏洩を防ぐ
2023年8月、ChatGPTの開発会社であるOpenAIが、GPTBotというOpenAIのWebクローラーについて明らかにしました。
GPTBotが自社サイトをクローリングしないように設定すると、サイト内のデータがChatGPTの学習に使われなくなるとのことです。
今回の記事では、GPTBotとは何か、その使い方を解説し、最後はOpenAIのデータ利用ポリシーについて説明します。
\生成AIを活用して業務プロセスを自動化/
OpenAIのGPTBotとは
今回、OpenAIがGPTBotについて明らかにした記事を一部抜粋すると「GPTBot is OpenAI’s web crawler and can be identified by the following user agent and string.」と記載されており、翻訳すると、「GPTBotとは、OpenAIのWebクローラーで、以下のユーザーエージェントと文字列を入力することで識別できます。」とのこと。※1
つまり、OpenAIは、GPTBotをWebページ上のサイト内コンテンツにクローリングさせることによって、現在のGPT-3.5やGPT-4を学習させていたということです。
クローリングとは、Webページの情報やデータを自動的に収集することを指します。Googleを例に出してみましょう。
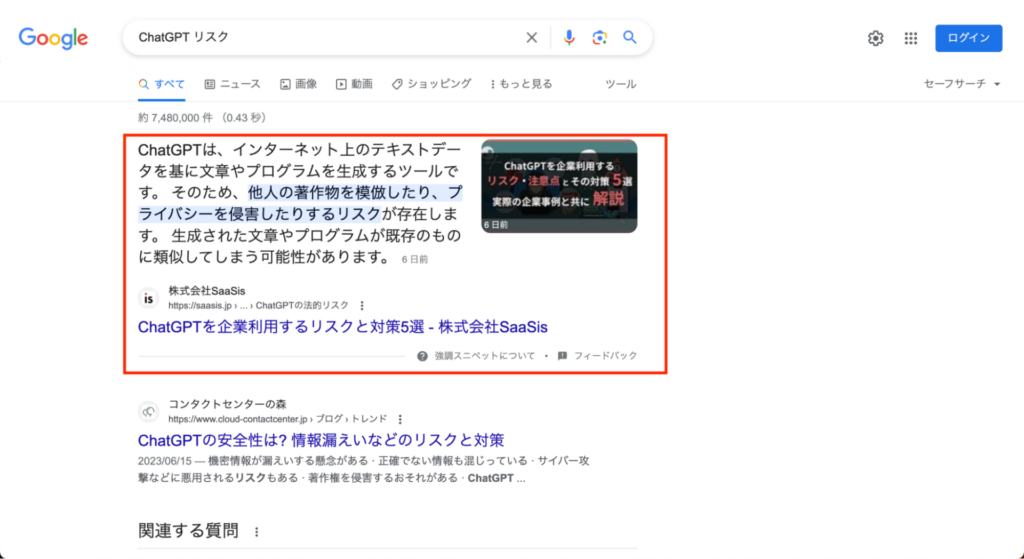
この検索した時の記事の順位はどのように決まっているのでしょうか?
Googleの目的は読者が検索したキーワードに対して、ぴったりな記事を出すことです。キーワードに最適な記事を出すには、記事の内容がどんなものか知る必要があります。
では、どのようにしてGoogle上にある膨大な記事の内容を確認するのでしょうか?
ここで、「クローリング」が登場します。
Googleはクローリングをして、記事の情報を取得することで、記事内容を把握します。そして、読者が検索したキーワードに対して適切な記事を表示させているのです。
OpenAIのGPTBotが行っていることも同様です。OpenAIが開発したChatGPTは、人間の質問に対して限りなく自然で適切な回答をすることを目的としています。
そのためには、大量のデータを使って学習する必要があり、GPTBotを使ってWeb上のコンテンツをクローリングさせることで、データを取得しています。
しかし、ChatGPTに自社サイトのコンテンツを学習してほしくない!という人もいるでしょう。次の章では、GPTBotに自社サイトをクローリングさせない方法を紹介します。
なお、ChatGPTを利用する際のリスクと注意点について知りたい方はこちらからご覧いただけます。

OpenAIのGPTBotに自社サイトをクローリングさせない方法
OpenAIの記事で自社サイトをクローリングさせない方法が紹介されていました。※2
GPTBotのクローリングを禁止させるには、自社サイトのrobots.txtファイルに以下のコードを入力してください。
User-agent: GPTBot
Disallow: //自社サイトのURLまた、自社サイトの全コンテンツとまではいかないものの、一部のコンテンツをクロールしてほしくない場合は、以下のコードを自社サイトのrobots.txtファイルに入力してください。
User-agent: GPTBot
Allow: //GPTBotがクロールしても大丈夫なリンクを入れる
Disallow: //GPTBotにクロールして欲しくないリンクを入れる

ChatGPTのデータ利用
企業の担当者の方など、重要な情報を扱う立場にある方は、OpenAIがどのように我々のデータを利用しているか知る必要があるでしょう。
OpenAIはWebサイトのクローリング以外にも、ChatGPTに入力された情報も学習に使用しています。それは、OpenAI公式のブログでも明かされています。※3
ChatGPTで情報漏洩を防ぐ方法
前述の通り、ChatGPTに入力した情報は学習にも使われるため、情報漏洩のリスクが伴います。しかし、情報漏洩を気にしていたらChatGPTを業務に活用することができません。
そのため、OpenAIはChatGPTに入力された情報を学習に使わないようにする3つの方法を用意しています。
以下の3つです。
- ChatGPTの設定で「チャットの学習」をオフにする
- プライバシーリクエストを送る
- APIを利用する
ChatGPTの設定で「チャットの学習」をオフにする
まずは、ChatGPTの設定からチャットの学習をオフにする方法をご紹介します。
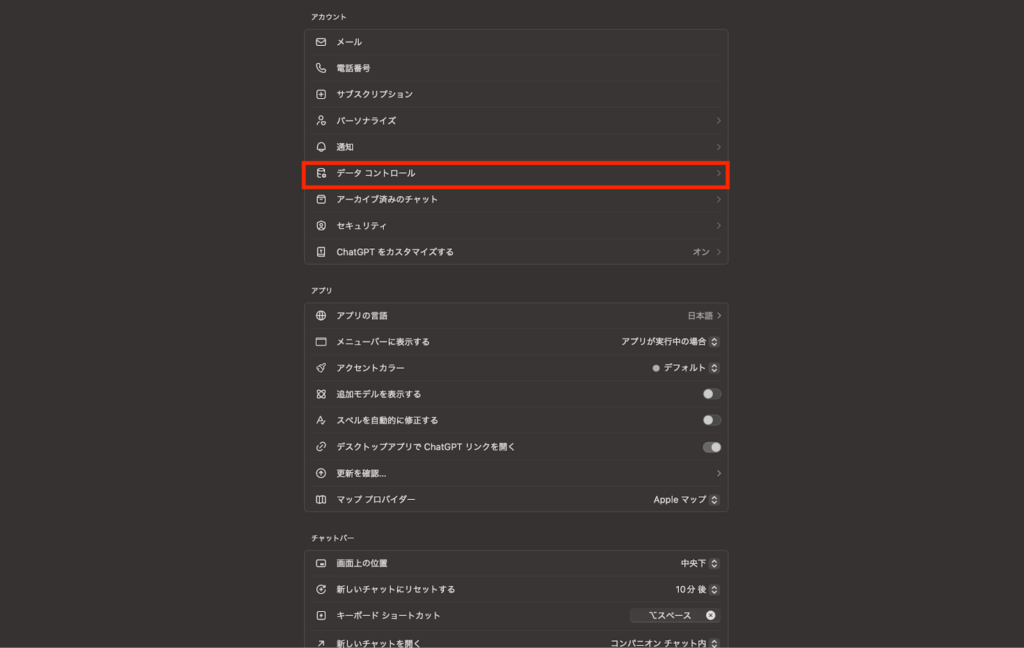
ChatGPTの設定から「データコントロール」クリック。
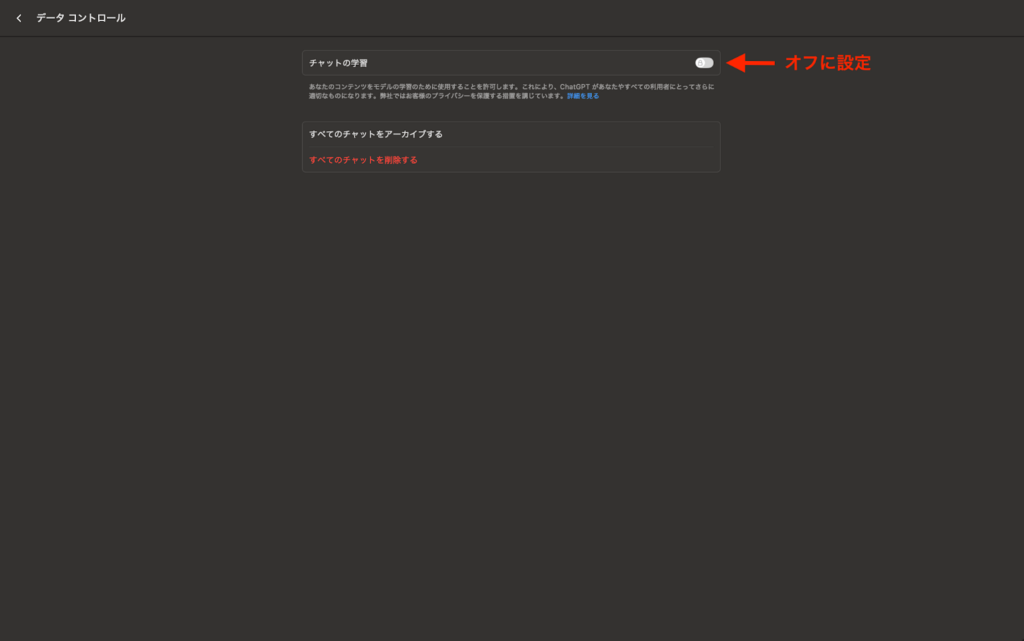
すると、上記の画面に移動するため「チャットの学習」をオフに設定するだけで設定は完了です。
この設定を行うだけで、チャットの履歴が残らなくなり、ChatGPTの学習にデータが使われなくなります。
プライバシーリクエストを送る
OpenAIのプライバシーポータルからも、会話履歴やデータを学習しないようにするためのリクエストを送ることができます。
手順も簡単で、OpenAI Privacy Portalへアクセスします。
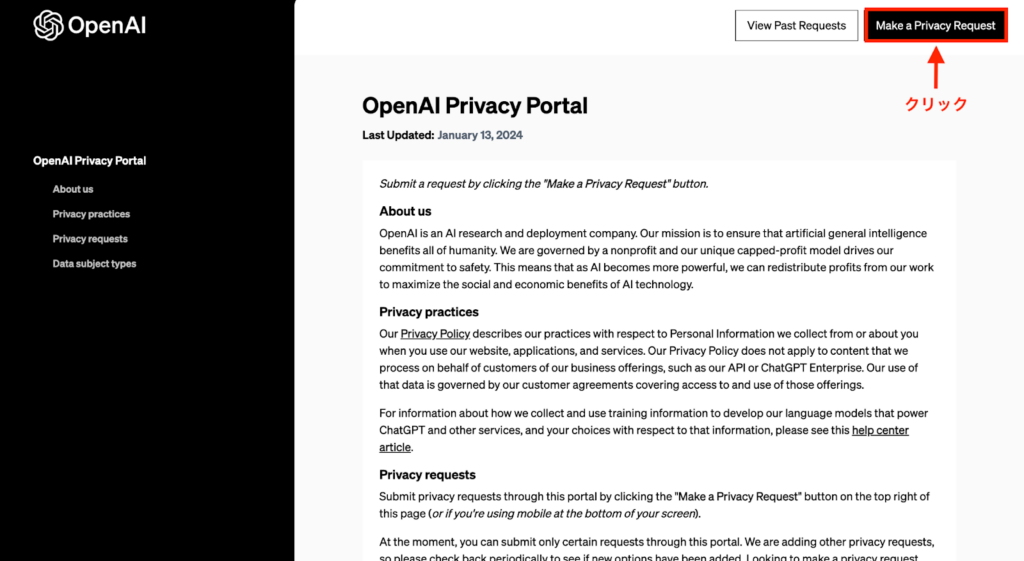
アクセスすると上記画面が表示されるため、画面右上の「Make a Privacy Request」をクリックしてください。
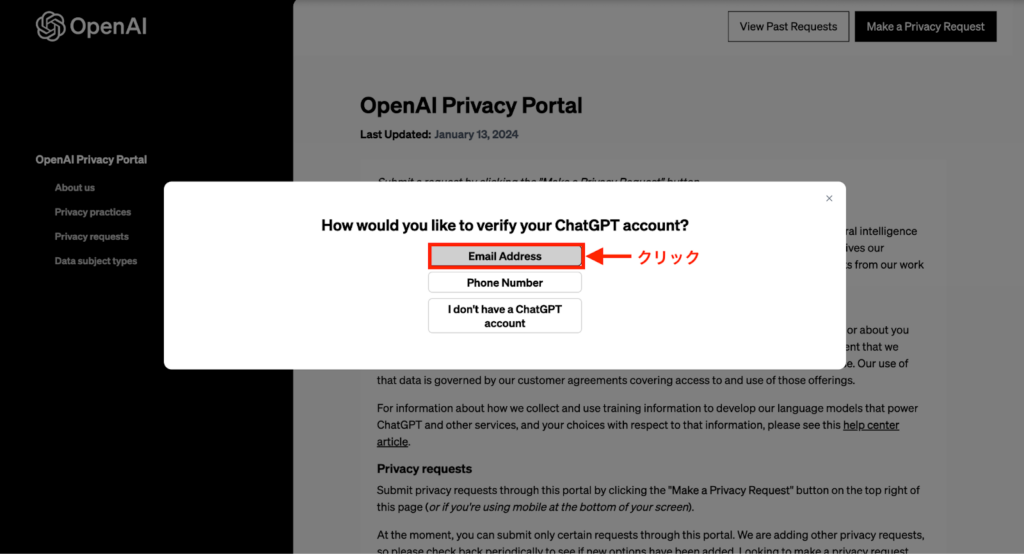
クリックすると、上記の画像が表示されるため、リクエストを送信したいChatGPTのアカウント情報を入力します。今回はEメールアドレスを使用するため、「Email Address」をクリックします。
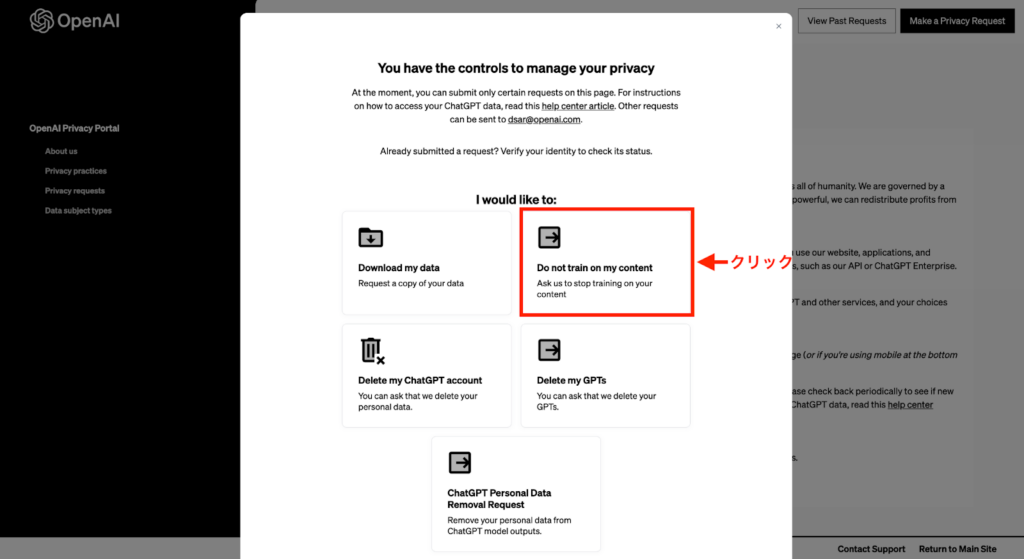
「Email Address」をクリックすると、上記のような表示になるため、赤枠の「Do not train on my content」を選択します。
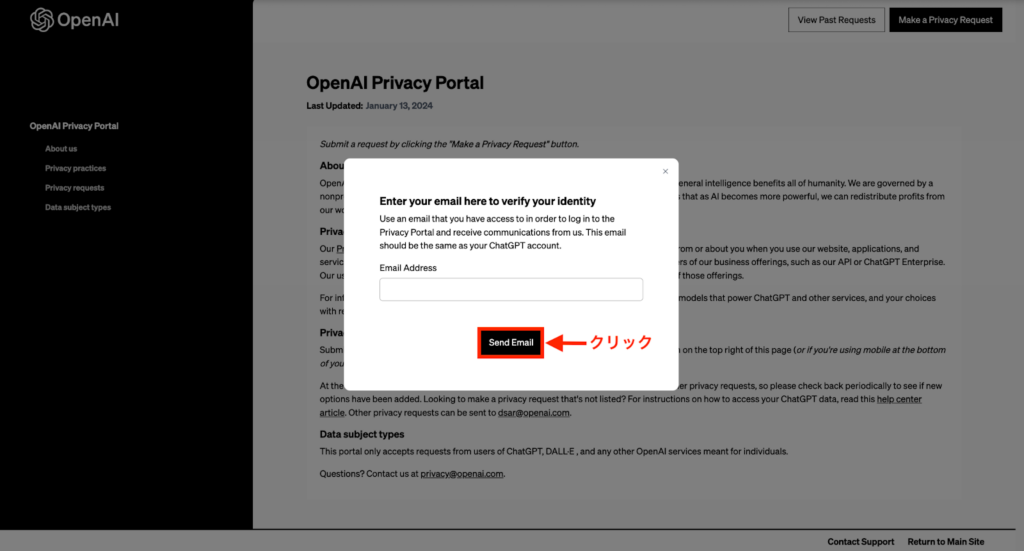
選択すると、上記のようなEメールアドレスの入力画面となるため、該当のChatGPTアカウントに使用しているEメールアドレスを入力し、「Send Email」をクリック。
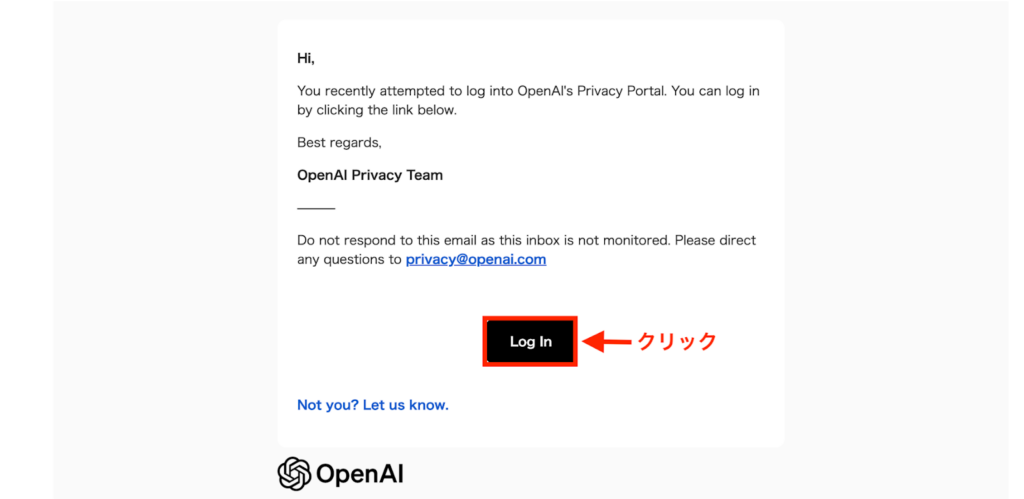
先ほど入力したEメールアドレス宛に、OpenAIから上記のようなメールが届きますので、「Log In」をクリックします。
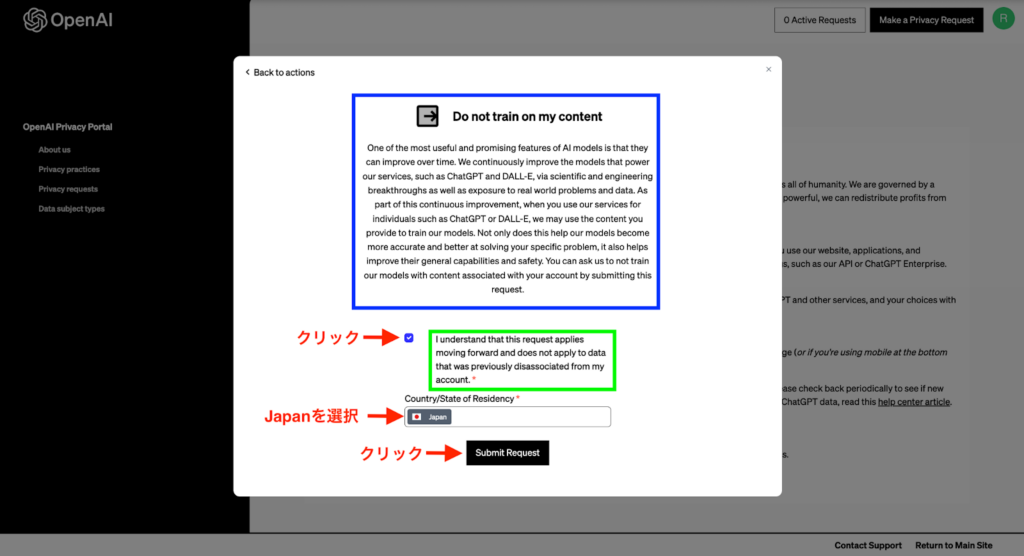
メールの「Log In」をクリックすると上記画面に移動するので、画像の通りチェックマークをつけ、Japanを選択し、「Submit Request」をクリックして進めていきます。
こちらの画面に書かれている内容は下記になりますので、「Submit Request」をクリックする前に一度確認しておきましょう。
青枠内文章の日本語訳
緑枠内文章の日本語訳
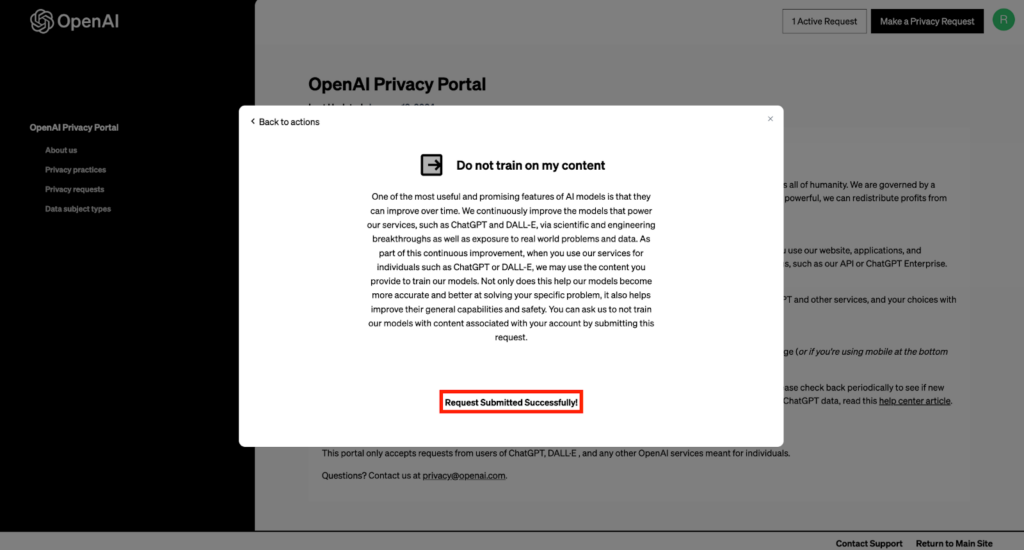
「Submit Request」をクリック後も問題なくリクエストを送信できていれば、上記画面のように「Request Submitted Successfully!」と表示が切り替わります。
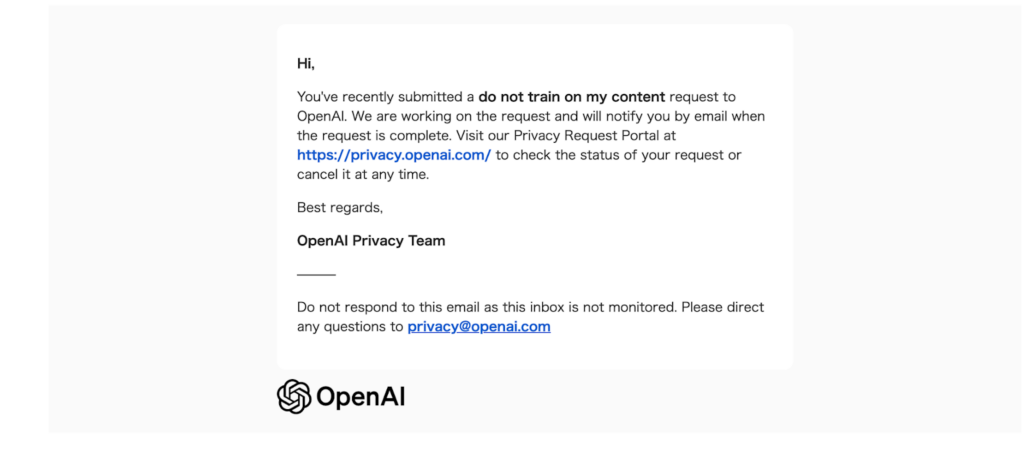
また、同時にOpenAIから上記のような、リクエストが正常に送信された旨のメールがきていれば申請は完了となります。
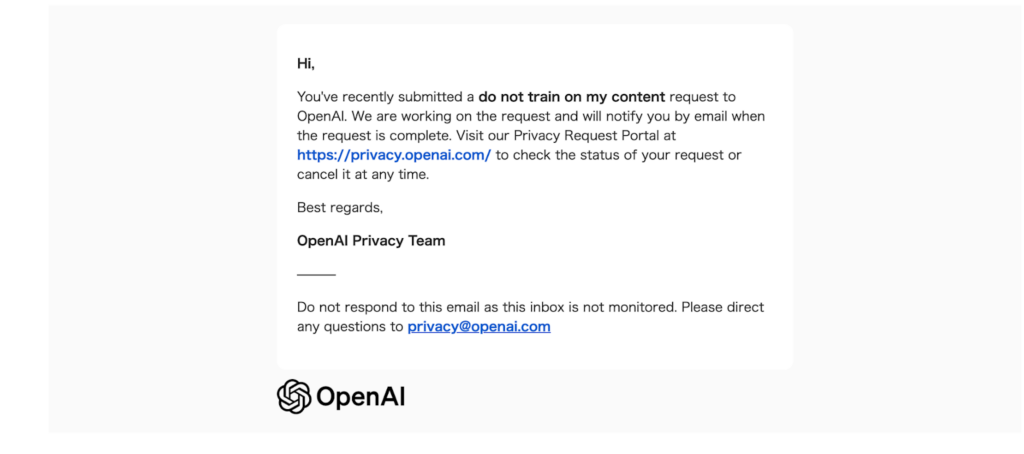
リクエストが正常に処理されると、OpenAIから上記の「Your Do not train on my content request is complete」のメールが届くので、このメールが届けば作業終了です。
APIを利用する
OpenAIはAPIを経由して生成されたデータについては、AIの学習に使用しないとしています。
仮に、情報をAI学習に使用しても良いよという方がいれば、こちらの「OpenAI Data Sharing Opt In」というフォームから手続きが可能です。ChatGPTに個人情報や機密情報を入力しても、情報漏洩のリスクがなくなります。ぜひ、お試しください。


OpenAIのGPTBotはWeb上の情報をChatGPTに学習するためのシステム
OpenAIはGPTBotと呼ばれるウェブクローラーを使ってWeb上のコンテンツを収集し、GPTモデルの学習に利用しています。自社サイトをクロールさせたくない場合は、robots.txtファイルにGPTBotのクロールを禁止設定してください。
また、ChatGPTに入力した内容も学習に使われるため、トレーニング機能をオフにしたり、プライバシーリクエストを送ったりすることで情報漏洩を防ぐことができる。ChatGPTの企業利用にはリスクがあるため、対策をしっかり行いましょう。

最後に
いかがだったでしょうか?
精度と安全性を両立した生成AI活用へ向けて、GPTBot対策やデータ保護を踏まえた最適な導入ステップを専門家が伴走しながら設計します。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。 ︎株式会社WEELのサービスを詳しく見る。
︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。
「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、通勤時間に読めるメルマガを配信しています。
最新のAI情報を日本最速で受け取りたい方は、以下からご登録ください。
また、弊社紹介資料もご用意しておりますので、併せてご確認ください。

