

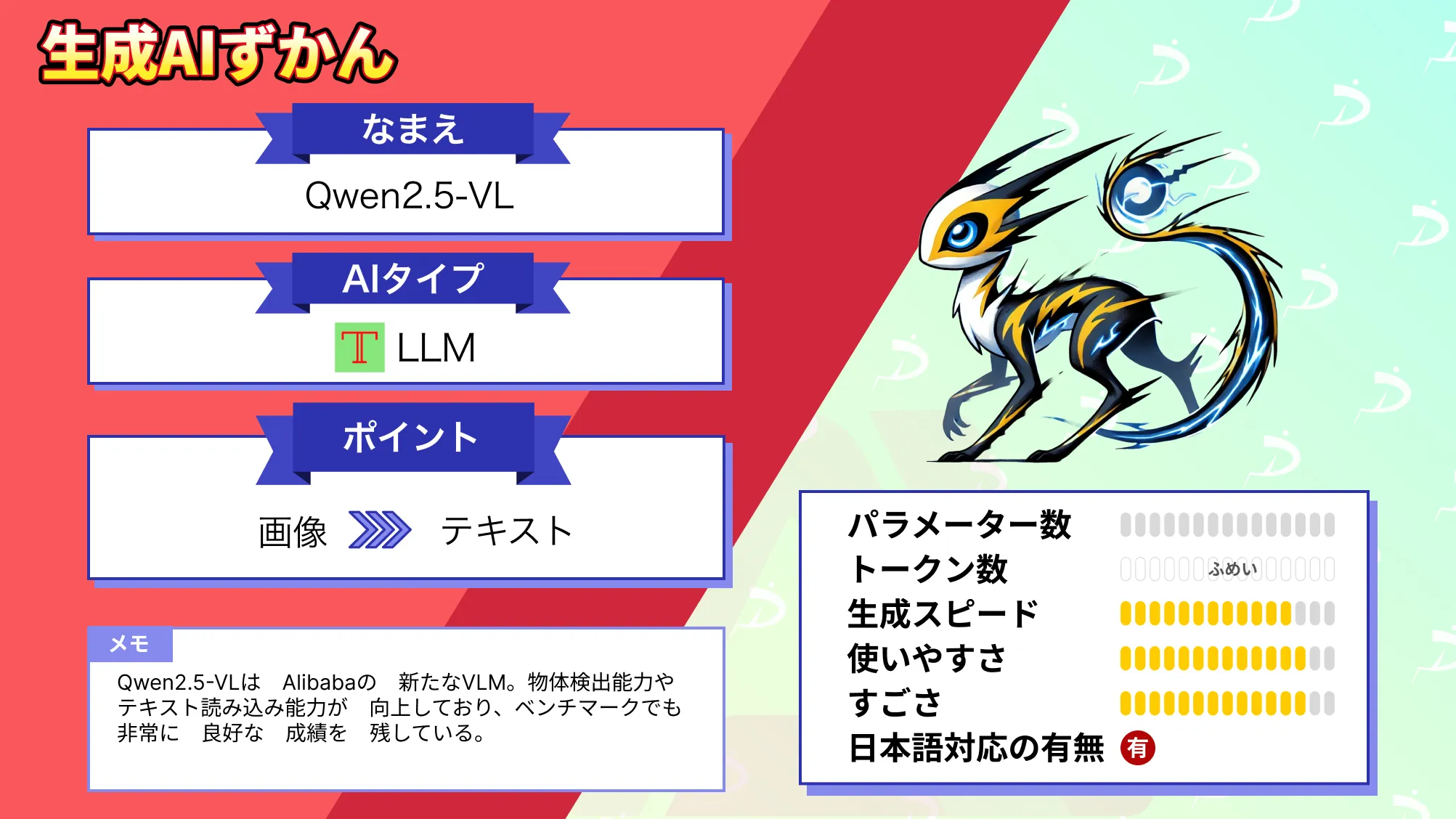
- 日本語に強い軽量VLMとして画像理解と文章処理を同時に実行
- 画像解析と日本語モデルを組み合わせた視覚×言語統合の構造
- MITライセンスで商用利用が可能で、小規模環境でも扱いやすい
国内企業でも活用が進む生成AIの中で、軽量なのに高精度な日本語処理を実現するモデルとして注目されているのが「Sarashina2.2-Vision-3B」です。画像とテキストを同時に扱える設計で、業務で使いやすい場面が多い点が特徴です。
この記事ではモデルの仕組み、特徴、料金、使い方までを体系的に解説します。最後まで読むことで、効果的な活用方法が明確になり、導入判断に必要な知識を一通り押さえられます。
\生成AIを活用して業務プロセスを自動化/
Sarashina2.2-Vision-3Bの概要
Sarashina2.2-Vision-3Bは、SB Intuitionsが開発した日本語特化型のVLMで、約3.8Bという軽量構成でありながら高い日本語理解性能を備えています。大規模モデルは高精度な一方で動作が重く、企業の実務環境では導入ハードルが高いという課題がありました。
このモデルはそのギャップを埋めるために登場し、画像内容の分析と日本語処理を一体で扱える点が従来技術との差別化要素です。
| 観点 | 内容 |
|---|---|
| 開発元 | SB Intuitions |
| モデル種別 | Vision-Language Model(VLM) |
| パラメータ数 | 約3.8B(軽量モデル) |
| 位置づけ | 日本語特化・画像×日本語処理に強いモデル |
| 従来との違い | 大規模モデル並みの精度を小規模環境でも扱える構造 |
日本語データや日本文化に関する情報を豊富に取り込み、精度とモデルサイズのバランスが良い点が特徴です。
なお、Sarashina2.2-Vision-3Bとあわせて他社の最新VLMも比較したい方は、下記の記事も合わせてご確認ください。
Sarashina2.2-Vision-3Bの仕組み
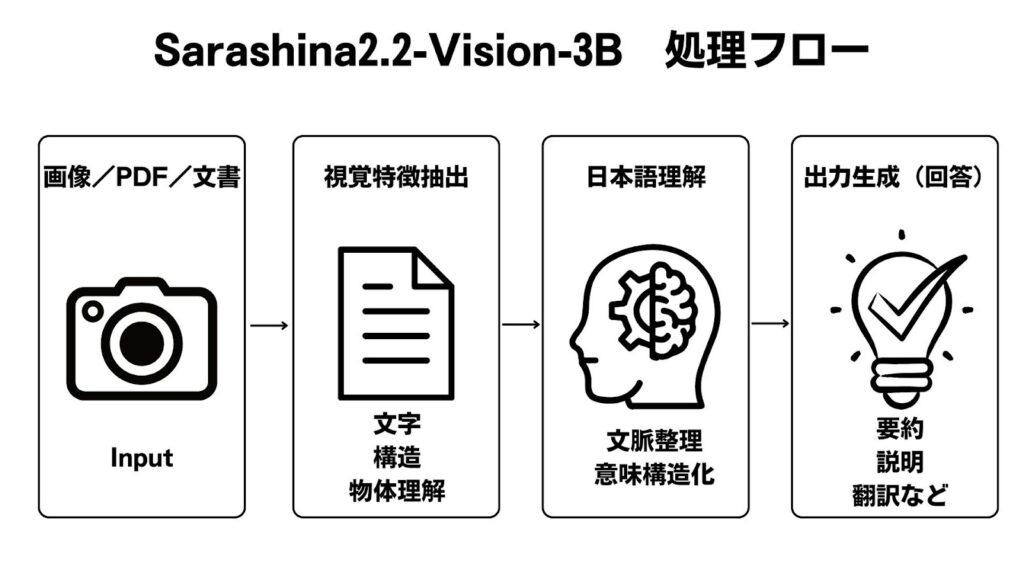
Sarashina2.2-Vision-3Bは、画像を処理するビジョンエンコーダと、日本語の文脈を理解する言語モデルを組み合わせた構造を採用しています。画像は一度特徴量として整理され、その内容が日本語モデルへ渡されることで、視覚情報と文章処理を一貫して扱える仕組みです。
この構造により、画像説明・文書抽出・特定部分の翻訳などを一つのモデルでまとめて実行できます。軽量でありながら、実務でも利用を検討できる水準の精度に達している点が特徴です。
| モジュール | 役割 |
|---|---|
| ビジョンエンコーダ | 画像から特徴量を抽出し言語モデルへ伝達する |
| 日本語特化LLM | 抽出された情報をもとに日本語で内容を理解し応答を生成する |
| 統合インターフェース | 視覚情報と日本語テキストを結合し、タスクごとに最適化する |


Sarashina2.2-Vision-3Bの特徴
主要なVLMと比較すると、Sarashina2.2-Vision-3Bは日本語特化の軽量モデルという独自ポジションに強みがあります。GPT-4oや Claude 3.5 Sonnetのような大規模モデルは高精度ですが重く、一般的なローカル環境では動かしにくいという課題があります。
一方、Sarashina2.2-Vision-3Bは 3.8B という小さな構成で視覚・日本語タスクを両立しており、一般的なローカル環境でも扱いやすい点が特徴です。
| モデル名 | 特徴 | 画像理解 | 日本語能力 | 動作の重さ | 向いている用途 |
|---|---|---|---|---|---|
| GPT-4o(OpenAI) | 汎用性が非常に高い。 音声・画像・動画すべて対応。 | 非常に強い | 強い | 重い(高スペック前提) | 研究、企画、生成系タスク、動画解析 |
| Claude 3.5 Sonnet(Anthropic) | 精度が高く、説明の一貫性が強い。 | 強い | 非常に強い | 中程度 | 業務文書、分析、レビュー |
| Qwen2.5-VL(Alibaba) | コスト効率が良く、画像理解に優れる。 | 強い | 強い | 中程度 | OCR・表読み取り・商品画像解析 |
| LLaVA-OneVision(コミュニティ) | 軽量で導入しやすい。 | 普通 | 普通 | 軽い | ローカル利用・研究用途 |
| Sarashina2.2-Vision-3B(SB Intuitions) | 日本語特化の軽量VLM。 3.8Bと小さく扱いやすい。 | 強い | 日本語特化で強い | 軽い(ローカル可) | 画像×日本語の組み合わせタスク(実務向け) |
Sarashina2.2-Vision-3Bの安全性・制約
Sarashina2.2-Vision-3BはMITライセンスのもとで公開され、研究用途から商用開発まで幅広く利用できますが、導入時にはいくつかの注意点があります。視覚情報と日本語を同時に扱える構造上、画像の解釈精度にゆらぎが生じる場合があり、業務で利用する際は出力内容を検証する体制が欠かせません。
また、学習データの詳細は公開されておらず、特定の専門領域では期待した精度が得られないケースも考えられます。さらに、社内の機密データを入力する際は管理ルールを整備し、利用環境(オンプレミスかクラウドか)ごとのセキュリティ要件を確認することが重要です。
また、モデルの安全性評価や公平性に関する独立した第三者レビューは現時点では限定的であり、重要な業務用途では検証プロセスの設計が欠かせません。
なお、AIモデルを導入する際のセキュリティ課題をより深く知りたい方は、下記の記事もあわせてご確認ください。

Sarashina2.2-Vision-3Bの料金
Sarashina2.2-Vision-3Bは無料で公開されており、モデルそのものを利用するだけであれば料金はかかりません。研究利用でも商用サービスに組み込む場合でも利用できるため、費用を抑えて生成AIを試したい企業でも検討しやすい仕組みです。
ただし、AIを動かすには計算用のパソコンやクラウド環境が必要で、実際にはその部分に費用が発生します。自社サーバーで動かす場合はGPUマシンの準備や電気代がかかり、クラウドで動かす場合は使用量に応じて料金が加算されます。
Sarashina2.2-Vision-3Bのライセンス
Sarashina2.2-Vision-3Bは「MITライセンス」という非常に自由度の高いルールで公開されています。MITライセンスは、研究や業務だけでなく商用サービスに組み込むことも許可されており、企業が独自のアプリやシステムに利用しても問題がありません。
利用時に特別な申請は必要なく、決められた注意事項を守れば誰でも導入できます。注意点としては、モデルを利用する際に「出典を記載してほしい」という最低限のルールがある点です。
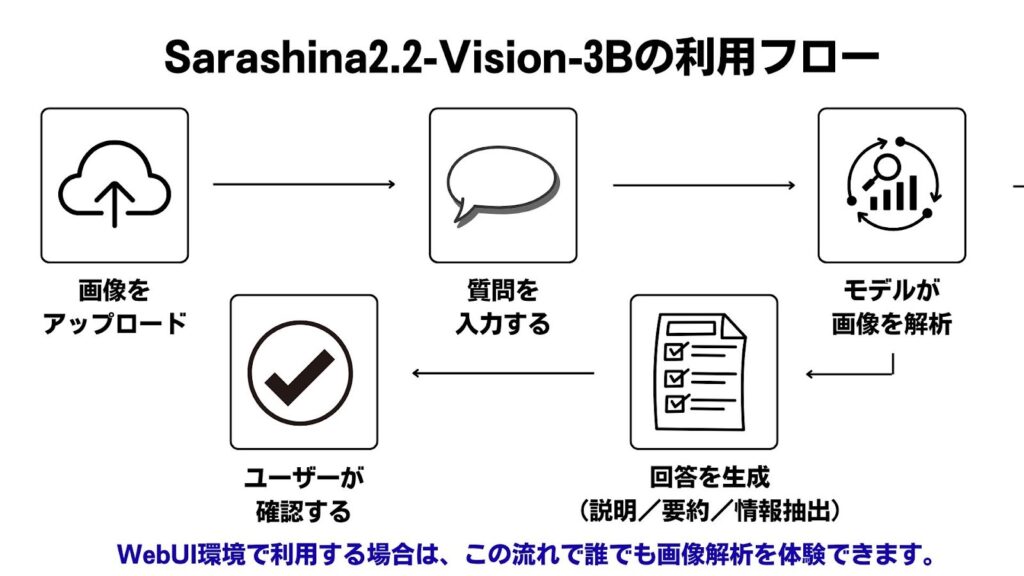
Sarashina2.2-Vision-3Bの使い方
Sarashina2.2-Vision-3Bは、ローカル環境にモデルを配置して利用する方法と、既存のAIフレームワークに読み込んで組み合わせる方法が選べます。基本的な流れは、モデルをロードし、画像とテキストを入力し、推論結果を受け取るというものです。
UIについては公式ツールが提供されているわけではありませんが、HuggingFaceなどの外部環境で画像をアップロードし、質問を入力するだけで動作を確認できます。API利用を行う場合は、PythonやJavaScriptなどのSDKを通して呼び出す形式となります。
Sarashina2.2-Vision-3Bの活用シーン
Sarashina2.2-Vision-3Bは、画像と日本語テキストを同時に扱える特性を生かし、業務・開発・研究などさまざまな場面で活用が検討できます。業務では、画像からの情報整理や商品画像への説明文生成を効率化でき、負担の軽減につながるでしょう。
開発の場面では、画像分類や文書読み取りを組み合わせたアプリケーションの試作に活用でき、既存サービスと連携するための実験環境としても役立ちます。研究分野では、視覚情報の解析や日本語データの検証に利用でき、試行錯誤の速度向上に寄与する点が利点です。
画像理解と日本語処理をまとめて扱いたいという課題に向いたモデルといえます。
なお、業務での生成AI活用イメージをより深く知りたい方は、以下の記事もご覧下さい。

まとめ
Sarashina2.2-Vision-3Bは、日本語理解とマルチモーダル処理に強みを持つ軽量VLMとして、大規模モデルを扱いにくい環境での活用が期待されます。MITライセンスにより商用利用の自由度も高く、今後データセットの拡張や推論精度の改善が進むことで、企業内検索や画像文書解析といった用途において採用が検討される場面は広がる見込みです。
導入を検討する際は、軽量モデルで十分な精度を確保できる業務かを確認しつつ、自社システムとの相性を検証環境でチェックしておくと安心です。

最後に
いかがだったでしょうか?
軽量VLMをオンプレや小規模環境に組み込み、画像×日本語処理を活かした業務自動化・検索基盤をどう設計すべきか、貴社のユースケースに沿って具体的なPoCプランまで整理します。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。 ︎株式会社WEELのサービスを詳しく見る。
︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。
「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、通勤時間に読めるメルマガを配信しています。
最新のAI情報を日本最速で受け取りたい方は、以下からご登録ください。
また、弊社紹介資料もご用意しておりますので、併せてご確認ください。
