

- テキスト・画像・軌跡を組み合わせて高度な制御が可能なビデオ生成モデル
- DragNUWA 1.5ではテキスト入力不要で軌跡だけでアニメーション生成
- MITライセンスで公開され、研究目的なら無料で利用可能
DragNUWAは、マイクロソフトが発表したテキスト、画像、軌跡を主要な制御要素として利用するビデオ生成モデルです。
このモデルは意味的、空間的、時間的な側面から高度に制御可能なビデオ生成を促進し、これまでのビデオ生成モデルとは異なり、ユーザーが画像内の背景やオブジェクトを直接操作できるようになっています。
2024年の1月8日に公開された最新のDragNUWA 1.5では、Stable Video Diffusionを使用して、特定のパスに従い画像をアニメーション化します。

今回は、DragNUWAの概要や使ってみた感想をお伝えします。是非最後までご覧ください!
\生成AIを活用して業務プロセスを自動化/
DragNUWAの概要
DragNUWAは、テキスト、画像、軌跡を主要な制御要素として利用するビデオ生成モデルです。
このモデルは意味的、空間的、時間的な側面から高度に制御可能なビデオ生成を促進し、これまでのビデオ生成モデルとは異なり、ユーザーが画像内の背景やオブジェクトを直接操作できるようになっています。
2024年の1月8日に公開された最新のDragNUWA 1.5では、Stable Video Diffusionを使用して、特定のパスに従い画像をアニメーション化します。
最初に公開されたDragNUWA 1.0は、以下のようにテキストで指示を出す必要がありました。

しかし、DragNUWA 1.5ではテキスト入力がなくても、軌跡を入力するだけでそれに従い画像をアニメーション化してくれます。

このような生成例を見ると、DragNUWAが他のビデオ生成モデルとは一線を画すほど繊細な調整を可能にしていることが分かります。ここからは、DragNUWAを実際に使ってその性能を検証していきます。
なお、Stable Video Diffusionについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

DragNUWAの性能
DragNUWAは従来の手法を上回る制御精度を実験的に実証しています。
研究者たちの評価では、DragNUWAは与えたドラッグ軌跡に従って、カメラワークや物体の動きを高精度に再現することができ、特に複数の物体を同時に動かす場合や複雑な曲線軌跡を扱う場合でも安定した性能を誇っています。
実際に、DragNUWAは従来モデルにはない機能として、曲線軌跡に沿って物体を動かしたり長い軌跡による大きな移動を表現したり、同時に複数オブジェクトを制御できる点が確認されていて、こうした点が既存技術にはなかったと評価されています。
今後はさらなる量的評価(ベンチマークスコアなど)の報告も期待されますが、現時点でDragNUWAは非常に高い可制御性を持つモデルとして注目されています。


DragNUWAのライセンス
DragNUWAはオープンソースとして公開されており、ライセンスはMITとなっています。以下の表からわかる通り、このライセンスでは商用利用・改変・再配布・私的利用はすべて許可されています。
一方で、MITライセンス自体には特許に関する明示的な許諾条項が含まれていないため、特許に関する利用には注意が必要です。
| 利用形態 | 可否 |
|---|---|
| 商用利用 |  |
| 改変 | |
| 再配布 | |
| 特許利用 |  |
| 私的利用 | |
ちなみに、DragNUWAは現状では純粋な研究プロジェクトであり、商用製品としての提供予定はありません。将来的に製品化される場合にはライセンス条件が変更される可能性もありますが、2025年9月時点ではMITライセンスの条件下で無料かつ自由に利用できます。
DragNUWAの料金
DragNUWAは研究用モデルとして公開されており、現状では利用に料金は発生しません。モデルのソースコードや学習済みウェイトはGitHubおよびHugging Faceで無償公開されており、誰でも自由にダウンロードして試せます。
また、ウェブ上のデモ(Hugging Face Spaces)も無料で利用可能です。現在DragNUWAを使うにあたって直接の使用料はありません。今後マイクロソフトが商用サービスとして提供する場合には別途料金体系が設定される可能性がありますが、現段階では研究目的の利用であればコストを気にせず利用できます
DragNUWAの使い方
DragNUWAには、オンラインデモを使用する方法と、ローカルにインストールして使用する方法の2種類がありました。
ただ、2025年9月時点では、Microsoft Researchのプロジェクトページと論文がDragNUWAの一次情報源となっていて、公式GitHubリポジトリは「Microsoftブランチへ移管中」と明記され、実行可能なコードや学習済みウェイトの正式公開は確認できません。
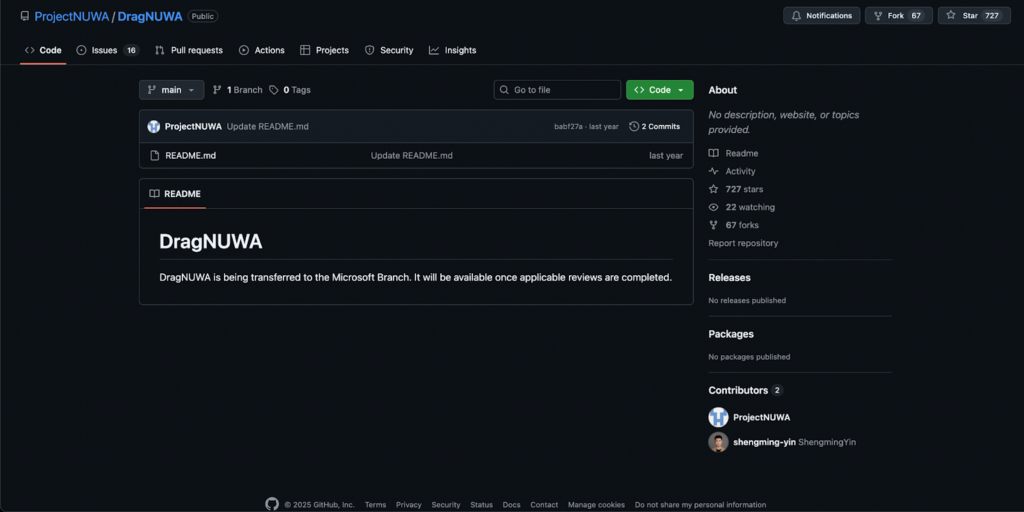
したがって、現時点での使い方は、論文に基づく再現手順と、2024年1月時点で利用可能となっていた使い方を整理します。最新状況は公式ページと該当リポジトリの表記を直接確認してください。
以降、2024年1月時点で利用できていた使い方の紹介となります。
オンラインデモは、以下のリンクにアクセスするだけで利用できるので非常に簡単です。
次に、ローカルにインストールして実行する手順です。
まず以下のコマンドを順に実行し、実行環境を構築します。
git clone https://github.com/ProjectNUWA/DragNUWA.git
cd DragNUWA
conda create -n DragNUWA python=3.8
conda activate DragNUWA
pip install -r environment.txt次に、以下リンク(2025年9月時点で利用不可)から事前トレーニングされたウェイトをダウンロードします。
最後に以下のコマンドを実行して、gradio webUIを起動します。
python DragNUWA_demo.py
まとめ
DragNUWAは、マイクロソフトが発表したテキスト、画像、軌跡を主要な制御要素として利用するビデオ生成モデルです。
このモデルは意味的、空間的、時間的な側面から高度に制御可能なビデオ生成を促進し、これまでのビデオ生成モデルとは異なり、ユーザーが画像内の背景やオブジェクトを直接操作できるようになっています。
2024年の1月8日に公開された最新のDragNUWA 1.5では、Stable Video Diffusionを使用して、特定のパスに従い画像をアニメーション化します。
実際に使ってみた感想は、全体的なバランスを見て、させたいことを的確に指示することで、かなりの高クオリティで画像をアニメーション化してくれると感じました。
この手のAIがさらに進化することで、たった一枚の画像から長編のアニメーションを生成できるような、まるで映画「マイノリティ・リポート」の世界観のAIが登場するかもしれませんね!

最後に
いかがだったでしょうか?
DragNUWAのような高精度なビデオ生成技術は、マーケティング・プロモーション・製品デモの自動化など、企業の制作プロセスを革新する可能性を秘めています。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。 ︎株式会社WEELのサービスを詳しく見る。
︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

